(1)HashMap的改变
java8之前,hashmap结构如下。 为了减少碰撞, hashcode和equals方法要写的严谨一些,且hashcode和equals要保持一致。但由于长度有限,碰撞是避免不了的,因此有个加载因子,当添加元素到达hash表的75%时进行扩容。提高空间利用率和 减少查询成本的折中,主要是泊松分布,0.75的话碰撞最小。
扩容2倍后重新排序计算位· 但扩容后任然解决不了碰撞。
哈希冲突主要与两个因素有关,(1)填装因子,填装因子是指哈希表中已存入的数据元素个数与哈希地址空间的大小的比值,a=n/m ; a越小,冲突的可能性就越小,相反则冲突可能性较大;但是a越小空间利用率也就越小,a越大,空间利用率越高,为了兼顾哈希冲突和存储空间利用率,通常将a控制在0.6-0.9之间,而.net中的HashTable则直接将a的最大值定义为0.72 (虽然微软官方MSDN中声明HashTable默认填装因子为1.0,但实际上都是0.72的倍数),(2)与所用的哈希函数有关,如果哈希函数得当,就可以使哈希地址尽可能的均匀分布在哈希地址空间上,从而减少冲突的产生

jdk1.8后,数组 链表+红黑树。在jdk1.8版本后,java对HashMap做了改进,在链表长度大于8的时候,将后面的数据存在红黑树中,以加快检索速度。
hashmap转红黑树的两个条件
一个是链表长度到8,一个是数组长度到64.
判断数组长度是否小于64,小于则进行扩容,否则转红黑树。
(2) ConcurrentHashMap
CouncurrentHashMap<jdk1.7>
1、底层:
(1)底层数据结构:
<jdk1.7>:数组(Segment) + 数组(HashEntry) + 链表(HashEntry节点)
底层一个Segments数组,存储一个Segments对象,一个Segments中储存一个Entry数组,存储的每个Entry对象又是一个链表头结点。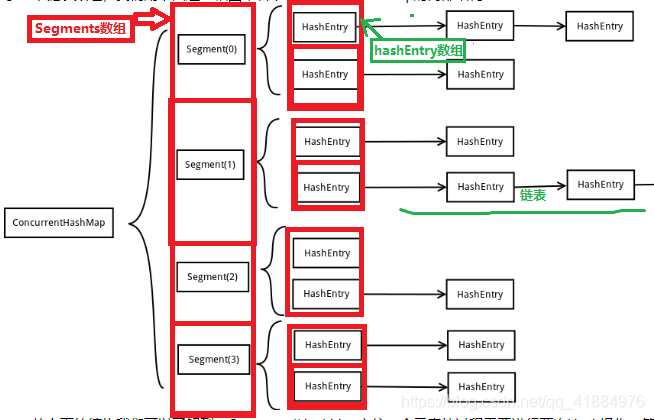
无锁 采用CAS添加元素

https://www.cnblogs.com/banjinbaijiu/p/9147434.html
put函数底层调用了putVal进行数据的插入,对于putVal函数的流程大体如下。
① 判断存储的key、value是否为空,若为空,则抛出异常,否则,进入步骤②
② 计算key的hash值,随后进入无限循环,该无限循环可以确保成功插入数据,若table表为空或者长度为0,则初始化table表,否则,进入步骤③
③ 根据key的hash值取出table表中的结点元素,若取出的结点为空(该桶为空),则使用CAS将key、value、hash值生成的结点放入桶中。否则,进入步骤④
④ 若该结点的的hash值为MOVED,则对该桶中的结点进行转移,否则,进入步骤⑤
⑤ 对桶中的第一个结点(即table表中的结点)进行加锁,对该桶进行遍历,桶中的结点的hash值与key值与给定的hash值和key值相等,则根据标识选择是否进行更新操作(用给定的value值
替换该结点的value值),若遍历完桶仍没有找到hash值与key值和指定的hash值与key值相等的结点,则直接新生一个结点并赋值为之前最后一个结点的下一个结点。进入步骤⑥
⑥ 若binCount值达到红黑树转化的阈值,则将桶中的结构转化为红黑树存储,最后,增加binCount的值。
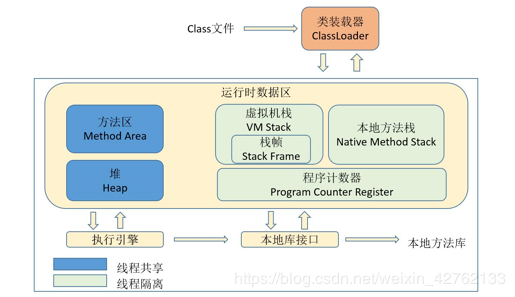
(3)jvm 永久区的改变 https://blog.csdn.net/weixin_42762133/article/details/95735737
方法区(Method Area) 与Java堆一样, 是各个线程共享的内存区域, 它用于存储已被虚拟机加载的类信息, 常量, 静态变量, 即时编译器编译后的代码等数据。 虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分, 但是它却有一个别名叫做Non-Heap非堆, 目的应该是与Java Heap 区分开来。
JDK1.8中进行了较大改动
移除了永久代(PermGen),替换为元空间(Metaspace);--》用的是物理内存。所以对元空间的垃圾回收
永久代中的 class metadata 转移到了 native memory(本地内存,而不是虚拟机);
永久代中的 interned Strings 和 class static variables 转移到了 Java heap;
永久代参数 (PermSize MaxPermSize) -> 元空间参数(MetaspaceSize MaxMetaspaceSize)
https://blog.csdn.net/stone_tomcate/article/details/101032106