(博客园-番茄酱原创)
在我的系统中,hadoop-2.5.1的安装路径是/opt/lib64/hadoop-2.5.1下面,然后hadoop-2.2.0的路径是/home/hadoop/下载/hadoop-2.2.0,我的eclipse的安装路径是/opt/programming/atd-bundle/eclipse。
因为老师需要我们写mapreduce程序,所以现在需要配置hadoop的eclipse插件。之前在windows下面安装hadoop一直会有莫名其妙的问题,所以索性直接在linux下面装了。Linux下面还更简单一些。
下面谈谈如何配置吧。
其实这次配置,并不是直接生成hadoop2.5.1的插件,而是生成hadoop2.2.0的插件,但是兼容hadoop-2.5.1。(这句话实际上指的是下面1步骤中的那个包是基于hadoop-2.2.0的开发的并且编译时候依赖hadoop-2.2.0,所以我们需要下载hadoop-2.2.0)。因此,我们需要下载的东西有3个,一个是hadoop插件源文件,一个是ant(fedora20在线安装),一个是额外的hadoop-2.2.0.tar.gz
。
- 下载hadoop2x-eclipse-plugin-master.zip,这是插件源文件,需要用ant编译。下载地址是:https://codeload.github.com/jaradgreen/hadoop2x-eclipse-plugin/zip/master
- 然后安装在线安装ant编译工具,在终端输入:yum install ant,一路选择yes或y安装。
- 将下载的hadoop2x-eclipse-plugin-master.zip解压,cd到下载的文件目录,终端输入:unzip hadoop2x-eclipse-plugin-master.zip,然后在当前目录下就会多出一个文件夹:hadoop2x-eclipse-plugin-master
- 然后cd hadoop2x-eclipse-plugin-master/src/contrib/eclipse-plugin进入解压的文件夹/hadoop2x-eclipse-plugin-master/src/contrib/eclipse-plugin目录下,修改build.xml。
- 修改编译配置文件build.xml.输入命令vi build.xml
- 在build.xml文件中project标签后面第三行,添加 <property name="eclipse.home" location="/opt/programming/adt-bundle/eclipse"/><!---这个是用来指出eclipse的安装目录->
- <property name="hadoop.home" location="/home/hadoop/下载/hadoop-2.2.0"/><!--此处需要hadoop2.2.0的发行包,编译依赖此路径(不是源包,也不是你安装的hadoop-2.5.1的路径,别弄混了)-->
- <property name="version" value="2.5.1"/> <!--(注意:自己根据自己的hadoop2.2.0和eclipse的路径情况,更改上述的安装位置)-->
- 然后进行ant编译, 运行ant命令, ant jar -D eclipse.home=/opt/programming/adt-bundle/eclipse -D hadoop.home=/home/hadoop/下载/hadoop-2.2.0 -D version=2.5.1
- 然后ant就会编译生成一个jar文件,在hadoop2x-eclipse-plugin-master/build/contrib/eclipse-plugin 下面,名为hadoop-eclipse-plugin-2.5.1.jar 然后将其拷到eclipse安装路径下的plugin文件夹下面,我的是/opt/programming/adt-bundle/eclipse/plugins 这个命令是mv /home/hadoop/下载/hadoop2x-eclipse-plugin-master/build/contrib/eclipse-plugin/hadoop-eclipse-plugin-2.5.1.jar /opt/programming/adt-bundle/eclipse/plugins/根据自己的情况进行更改啦
- 重启eclipse,一路点击windows->show view->other->mapreduce tools就可以选择hadoop视图了,然后就可以进行相应的编程了。
- 把刚刚的hadoop-2.2.0删掉,他已经光荣的完成使命啦
打开eclipse,然后进行一些配置
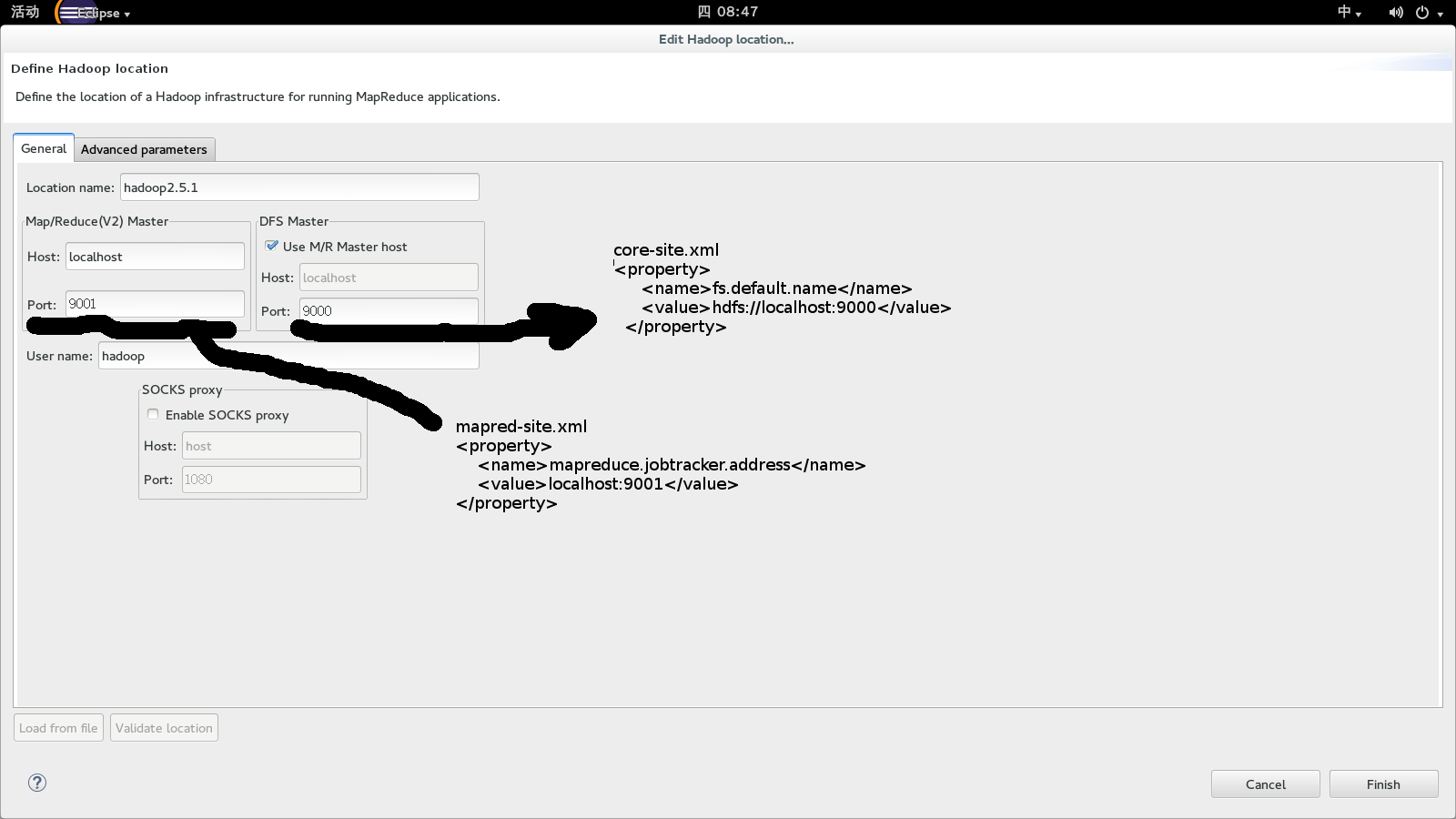
先选择hadoop的安装路径

然后点击ok
然后点击hadoop location,然后新建一个location
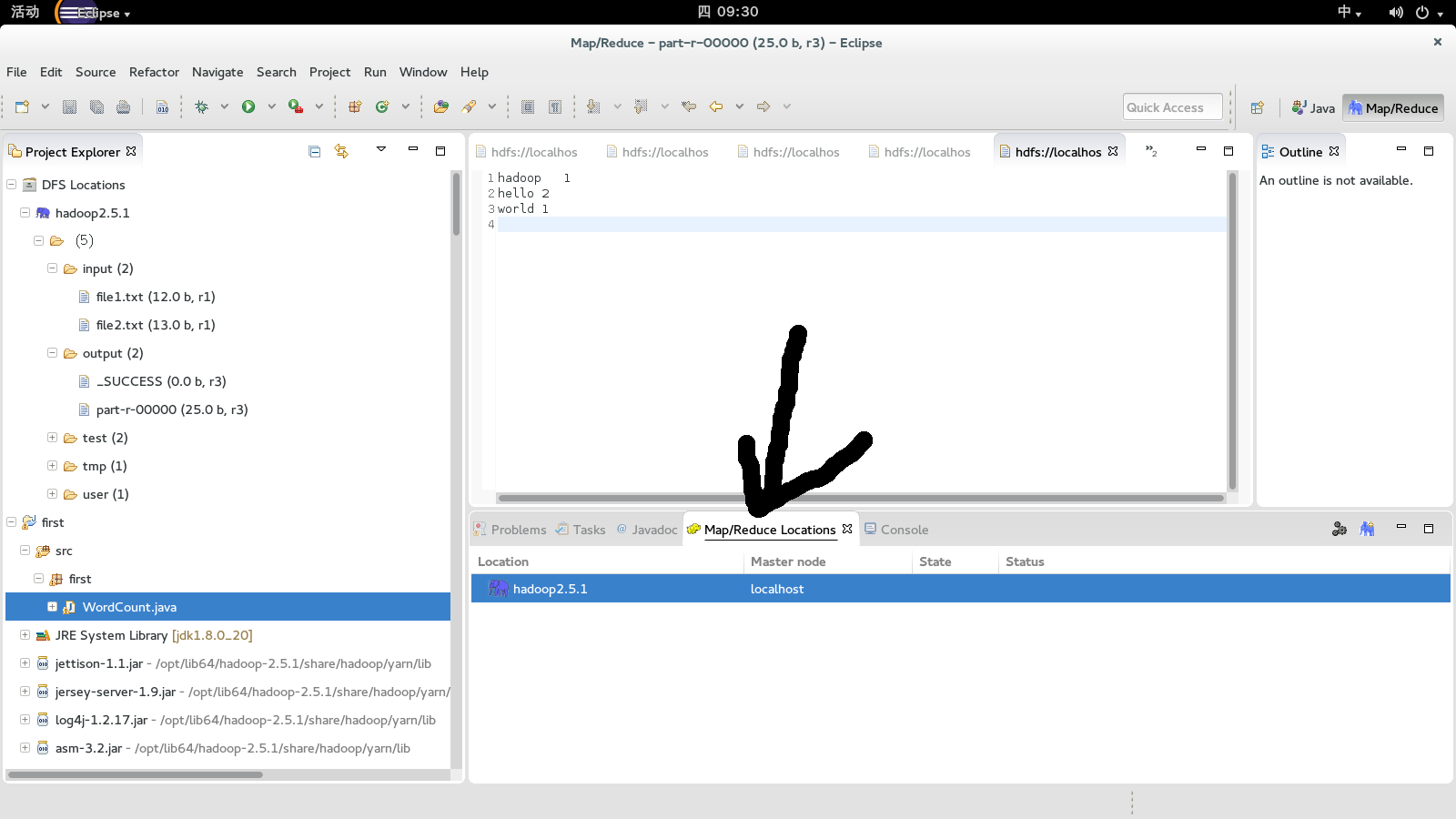
右击鼠标新建一个location
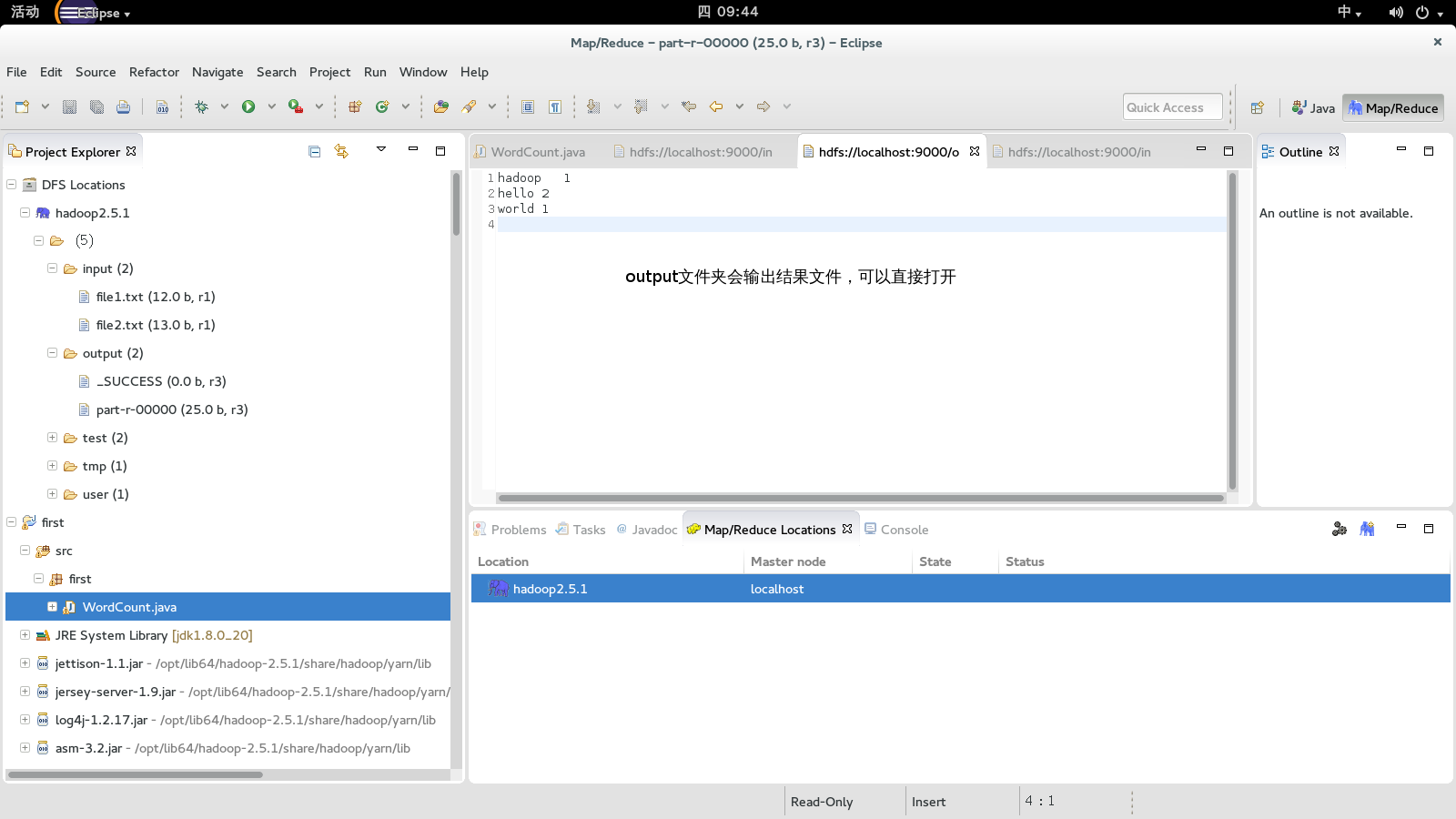
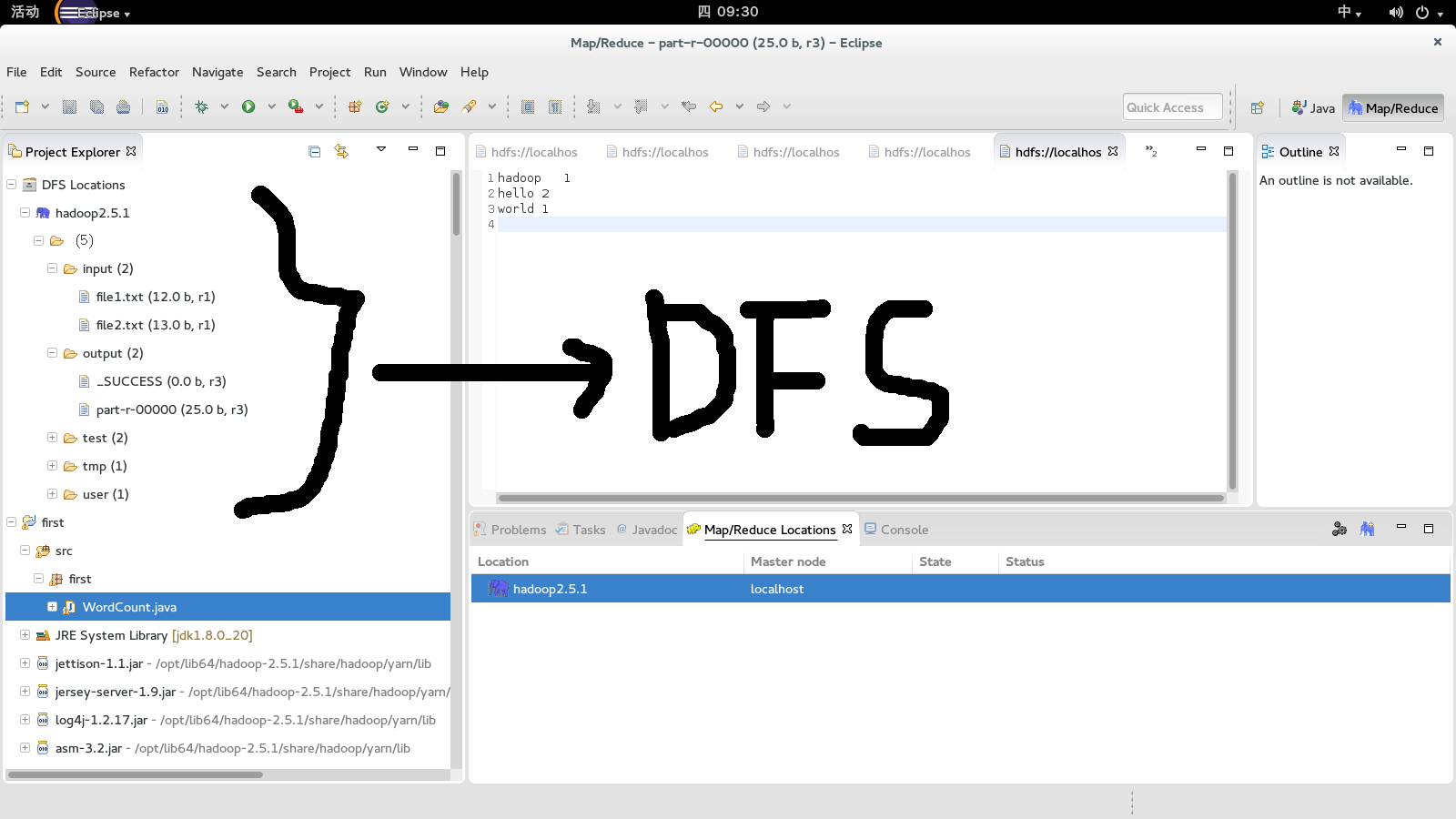
到这边,hadoop的eclipse就配置完毕了。如果你的hadoop的是开启的状态下,在eclipse中便可以直接操作dfs了
对了,如果你要跑wordcount程序,你需要在hadoop的src包中找到WordCount.java文件,
该目录下面有好多例子,目录是hadoop-2.5.1-src/hadoop-mapreduce-project/hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples

附上其中除了命名空间的包名的代码
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length < 2) { System.err.println("Usage: wordcount <in> [<in>...] <out>"); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); for (int i = 0; i < otherArgs.length - 1; ++i) { FileInputFormat.addInputPath(job, new Path(otherArgs[i])); } FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
运行之前,需要配置run的参数:hdfs://localhost:9000/input hdfs://localhost:9000/output。然后再run as-> run on hadoop(要先把hadoop开启)
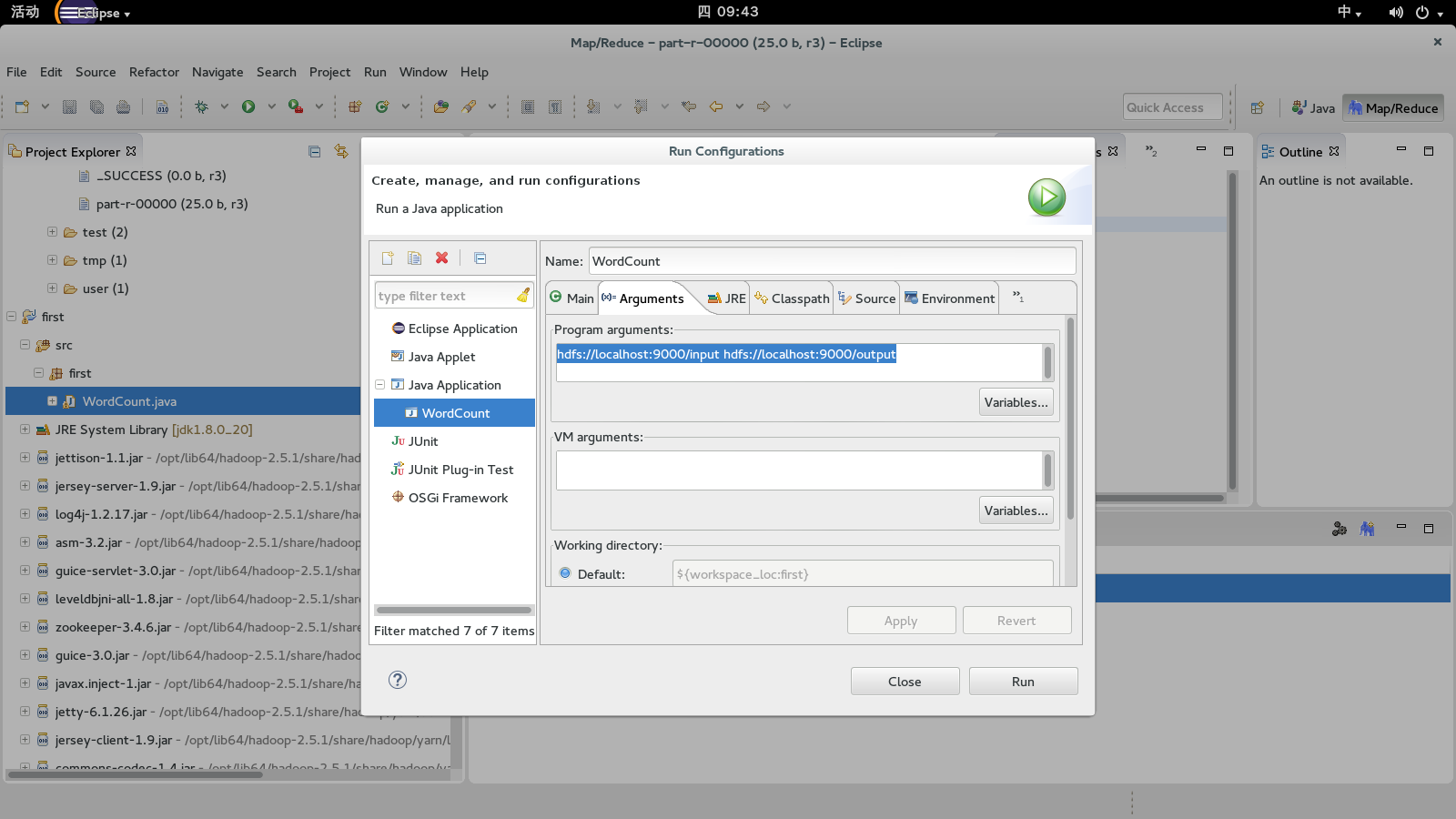
在input文件夹下面放置2个文件,比如file1.txt,file2.txt,然后运行过后程序会新建一个output文件夹,里面会包含结果
file1

file2.txt

output下面文件内容