1 物理时钟 vs 逻辑时钟
可能有人会问,为什么分布式系统不使用物理时钟记录事件?每个事件对应打上一个时间戳,当需要比较顺序的时候比较相应时间戳就好了。
这是因为现实生活中物理时间有统一的标准,而分布式系统中每个节点记录的时间并不一样,即使设置了NTP时间同步节点间也存在毫秒级别的偏差。因而分布式系统需要有另外的方法记录事件顺序关系,这就是逻辑时钟(logical clock)。
2 Lamport时间戳
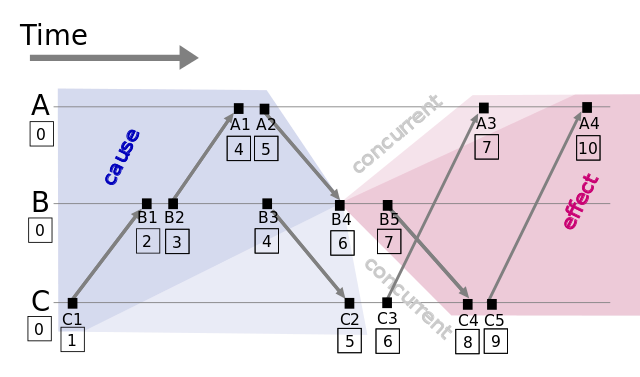
图1
- 每个事件对应一个Lamport时间戳,初始值为0
- 如果事件在节点内发生,时间戳加1
- 如果事件属于发送事件,时间戳加1并在消息中带上该时间戳
- 如果事件属于接收事件,时间戳 = Max(本地时间戳,消息中的时间戳) + 1
3 Vector clock
Lamport时间戳帮助我们得到事件顺序关系,但还有一种顺序关系不能用Lamport时间戳很好地表示出来,那就是同时发生关系(concurrent)。例如图1中事件B4和事件C3没有因果关系,属于同时发生事件,但Lamport时间戳定义两者有先后顺序。
Vector clock是在Lamport时间戳基础上演进的另一种逻辑时钟方法,它通过vector结构不但记录本节点的Lamport时间戳,同时也记录了其他节点的Lamport时间戳。Vector clock的原理与Lamport时间戳类似,使用图例如下:
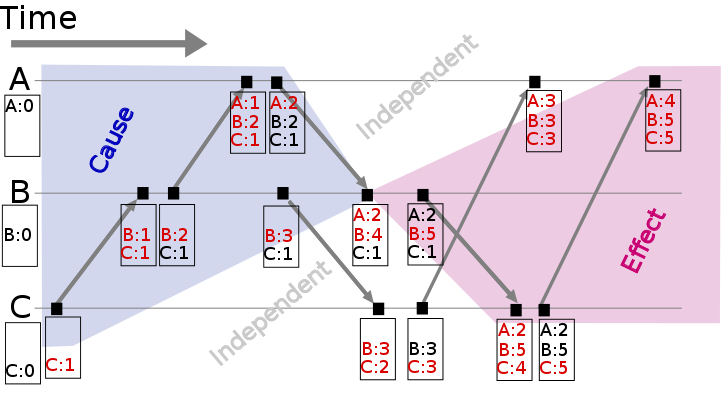
4 Version vector
基于Vector clock我们可以获得任意两个事件的顺序关系,结果或为先后顺序或为同时发生,识别事件顺序在工程实践中有很重要的引申应用,最常见的应用是发现数据冲突(detect conflict)。
分布式系统中数据一般存在多个副本(replication),多个副本可能被同时更新,这会引起副本间数据不一致,Version vector的实现与Vector clock非常类似,目的用于发现数据冲突。下面通过一个例子说明Version vector的用法:
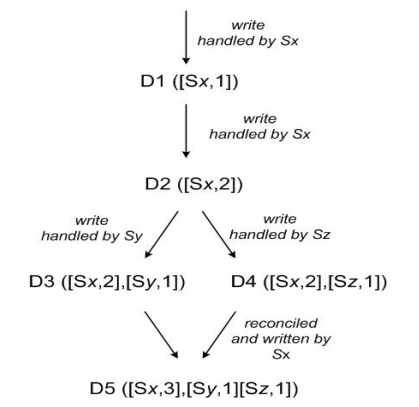
- client端写入数据,该请求被Sx处理并创建相应的vector ([Sx, 1]),记为数据D1
- 第2次请求也被Sx处理,数据修改为D2,vector修改为([Sx, 2])
- 第3、第4次请求分别被Sy、Sz处理,client端先读取到D2,然后D3、D4被写入Sy、Sz
- 第5次更新时client端读取到D2、D3和D4 3个数据版本,通过类似Vector clock判断同时发生关系的方法可判断D3、D4存在数据冲突,最终通过一定方法解决数据冲突并写入D5
Vector clock只用于发现数据冲突,不能解决数据冲突。如何解决数据冲突因场景而异,具体方法有以最后更新为准(last write win),或将冲突的数据交给client由client端决定如何处理,或通过quorum决议事先避免数据冲突的情况发生。