1 简述
Spark为包含键值对类型的RDD提供了一些专有的操作。这些RDD被称为PairRDD。
2 创建PairRDD
2.1
在sprk中,很多存储键值对的数据在读取时直接返回由其键值对数据组成的PairRDD。
2.2
可以调用map()函数,将一个普通的RDD转换为PairRDD。
scala 版:
使用第一个单词作为作为键创建出一个PairRDD
val pairs = lines.map(x => s.split(" ")(0), x)
java版:
同样是使用第一个单词作为作为键创建出一个PairRDD
1 PairFunction<String, String> keyData = new PairFunction<String, String>() {
2 public Tuple2<String, String> call(String str) {
3 return new Tuple2(str.split(" ")[0], str);
4 }
5 }
3 PairRDD的转化操作
表:对Pair RDD的转化操作(以键值对集合{(1,2),(3,4),(3,6)}为例)

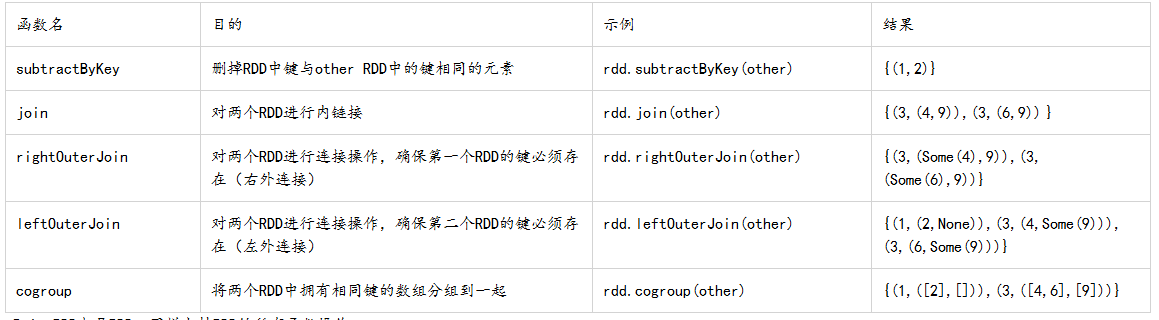
表:针对两个pair RDD的转化操作(rdd={(1,2),(3,4),(3,6)} other ={(3,9)})
4 PairRDD的聚合操作
4.1 scala
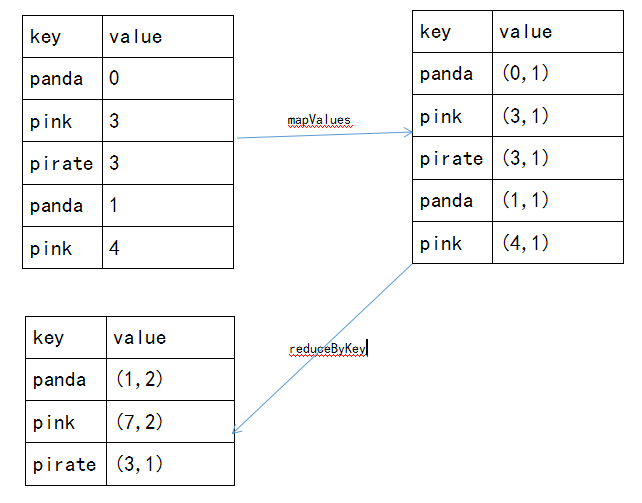
scala中使用mapValues()和reduceByKey()计算每个键对应的平均值:
用Scala实现单词计数:
1 val input=sc.textFile(path)
2 val word=input.flatMap(x=>x.split(" "))
3 val result=word.map(s=>(x,1)).reduceByKey((x,y)=>(x+y))
4.2 java
用Java实现单词计数:
1 public class WordCount implements Serializable {
2 private static final long serialVersionUID = 1L;
3 private final static SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount" );
4 private final static JavaSparkContext sc = new JavaSparkContext( sparkConf);
5 public void wordCount(){
6 JavaRDD<String> input= sc.textFile("hdfs://hadoop:8020/words.txt" );
7 JavaRDD<String> words= input.flatMap( new FlatMapFunction<String, String>() {
8 private static final long serialVersionUID = 1L;
9 @Override
10 public Iterator<String> call(String x ) throws Exception {
11 return Arrays.asList( x.split( " ")).iterator();
12 }
13 });
14 JavaPairRDD<String, Integer> result=words .mapToPair(new PairFunction<String, String, Integer>() {
15 private static final long serialVersionUID = 1L;
16 @Override
17 public Tuple2<String, Integer> call(String x) throws Exception {
18 return new Tuple2<String, Integer>(x, 1);
19 }
20 }).reduceByKey( new Function2<Integer, Integer, Integer>() {
21 private static final long serialVersionUID = 1L;
22 @Override
23 public Integer call(Integer x , Integer y ) throws Exception {
24 return x +y ;
25 }
26 });
27 }
28 }