常用的分类算法一般假设不同类的比例是均衡的,现实生活中经常遇到不平衡的数据集,比如广告点击预测(点击转化率一般都很小)、商品推荐(推荐的商品被购买的比例很低)、信用卡欺诈检测等等。
对于不平衡数据集,一般的分类算法都倾向于将样本划分到多数类,体现在整体的准确率很高。
但对于极不均衡的分类问题,比如仅有1%的人是坏人,99%的人是好人,最简单的分类就是将所有人都划分为好人,都能得到99%的准确率,显然这样的分类并没有提供任何的信息。
处理不平衡数据,可以从两方面考虑:
一是改变数据分布,从数据层面使得类别更为平衡;
二是改变分类算法,在传统分类算法的基础上对不同类别采取不同的加权方式,使得更看重少数类。
本文主要从数据的角度出发,主要方法为采样,分为欠采样和过采样以及对应的一些改进方法。
一、欠采样
随机欠采样
减少多数类样本数量最简单的方法便是随机剔除多数类样本,可以事先设置多数类与少数类最终的数量比例,在保留少数类样本不变的情况下,根据比例随机选择多数类样本。
-
优点:操作简单,只依赖于样本分布,不依赖于任何距离信息。
-
缺点:会丢失一部分多数类样本的信息,无法充分利用已有信息。
Tomek links方法
首先来看一些定义。假设样本点
首先来看一些定义。
假设样本点xi和xj属于不同的类别,d(xi,xj)表示两个样本点之间的距离。
称(xi,xj)为一个Tomek link对,如果不存在第三个样本点xl使得d(xl,xi)<d(xi,xj)或者d(xl,xj)<d(xi,xj)成立。
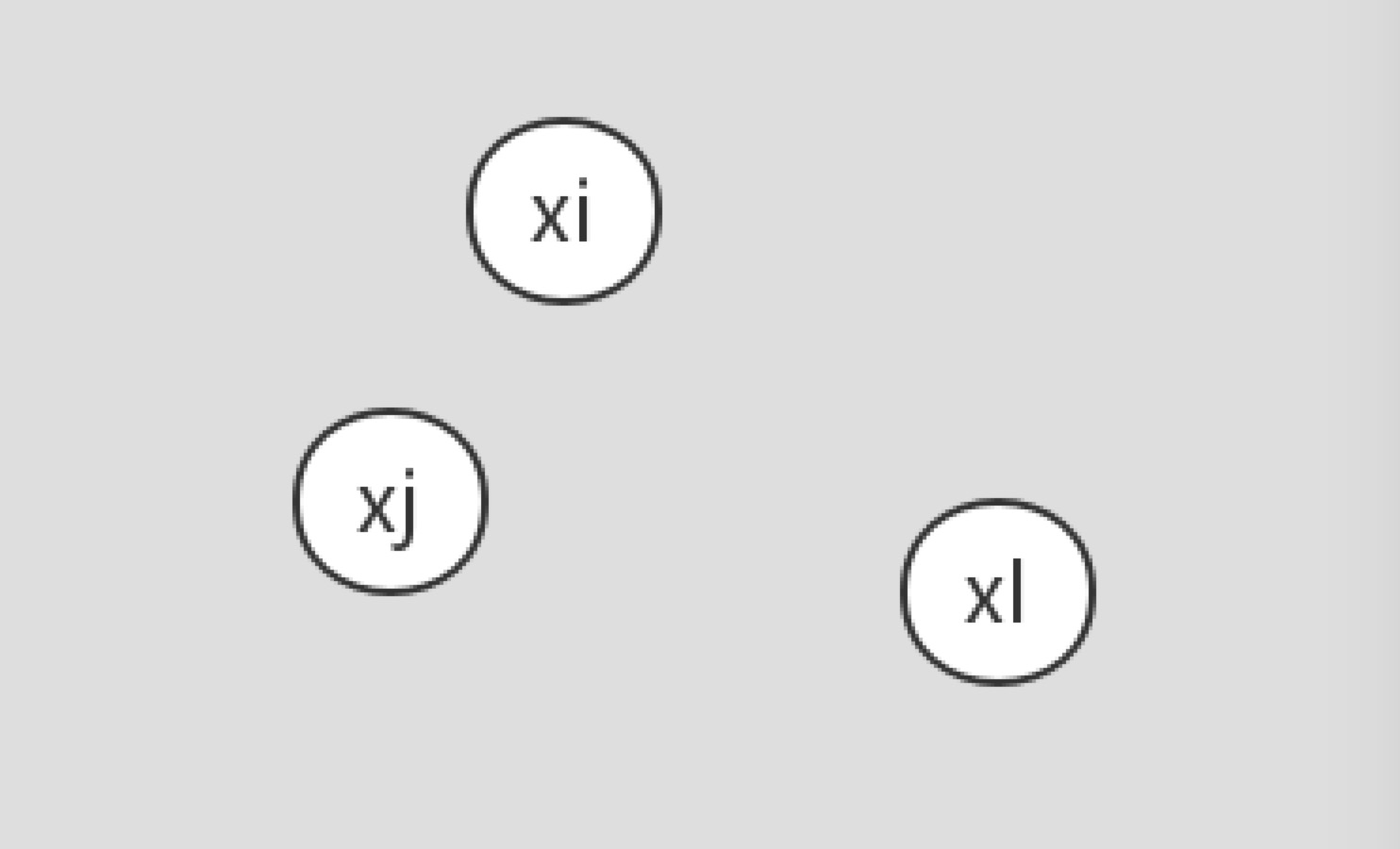
容易看出,如果两个样本点为Tomek link对,则其中某个样本为噪声(偏离正常分布太多)或者两个样本都在两类的边界上。
下图是对Tomek link对的直观解释(其中加号为少数类,减号为多数类):A、B、C中的样本在两类的边界上,D、E中的多数类样本均为噪声。
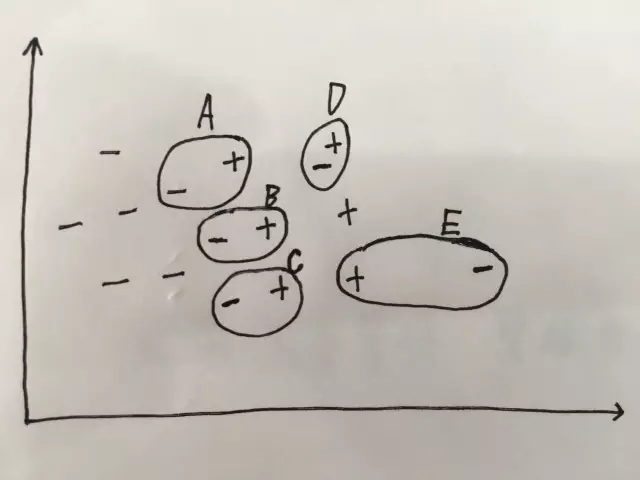
Tomek link对一般有两种用途:
-
欠采样:将Tomek link对中属于多数类的样本剔除。
-
数据清洗:将Tomek link对中的两个样本都剔除。
NearMiss方法
NearMiss方法是利用距离远近剔除多数类样本的一类方法,实际操作中也是借助kNN,总结起来有以下几类:
-
NearMiss-1:在多数类样本中选择与最近的3个少数类样本的平均距离最小的样本。
-
NearMiss-2:在多数类样本中选择与最远的3个少数类样本的平均距离最小的样本。
-
NearMiss-3:对于每个少数类样本,选择离它最近的给定数量的多数类样本。
NearMiss-1和NearMiss-2方法的描述仅有一字之差,但其含义是完全不同的:NearMiss-1考虑的是与最近的3个少数类样本的平均距离,是局部的;NearMiss-2考虑的是与最远的3个少数类样本的平均距离,是全局的。
NearMiss-1方法得到的多数类样本分布也是“不均衡”的,它倾向于在比较集中的少数类附近找到更多的多数类样本,而在孤立的(或者说是离群的)少数类附近找到更少的多数类样本,原因是NearMiss-1方法考虑的局部性质和平均距离。
NearMiss-3方法则会使得每一个少数类样本附近都有足够多的多数类样本,显然这会使得模型的精确度高、召回率低。
论文中有对这几种方法的比较,得到的结论是NearMiss-2的效果最好,不过这也是需要综合考虑数据集和采样比例的不同造成的影响。
二、过采样
随机过采样
与欠采样对应,增加少数类样本数量最简单的方法便是随机复制少数类样本,可以事先设置多数类与少数类最终的数量比例,在保留多数类样本不变的情况下,根据ratio随机复制少数类样本。
在使用的过程中为了保证所有的少数类样本信息都会被包含,可以先完全复制一份全量的少数类样本,再随机复制少数类样本使得数量比例满足给定的ratio。
-
优点:操作简单,只依赖于样本分布,不依赖于任何距离信息,属于非启发式方法。
-
缺点:重复样本过多,容易造成分类器的过拟合。
SMOTE
SMOTE全称为Synthetic Minority Over-sampling Technique,主要思想来源于手写字识别:对于手写字的图片而言,旋转、扭曲等操作是不会改变原始类别的(要排除翻转和180度大规模旋转这类的操作,因为会使得“9”和“6”的类别发生变化),因而可以产生更多的样本。
SMOTE的主要思想也是通过在一些位置相近的少数类样本中生成新样本达到平衡类别的目的,由于不是简单地复制少数类样本,因此可以在一定程度上避免分类器的过度拟合。具体如下图:
其算法流程如下:
-
设置向上采样的倍率为N,即对每个少数类样本都需要产生对应的N个少数类新样本。
-
对少数类中的每一个样本x,搜索得到其k(通常取5)个少数类最近邻样本,并从中随机选择N个样本,记为y1,y2,…,yN(可能有重复值)。
-
构造新的少数类样本rj=x+rand(0,1)∗(yj−x),其中rand(0,1)表示区间(0,1)内的随机数。
Borderline SMOTE
原始的SMOTE算法对所有的少数类样本都是一视同仁的,但实际建模过程中发现那些处于边界位置的样本更容易被错分,因此利用边界位置的样本信息产生新样本可以给模型带来更大的提升。Borderline SMOTE便是将原始SMOTE算法和边界信息结合的算法。它有两个版本:Borderline SMOTE-1和Borderline SMOTE-2。
Borderline SMOTE-1算法流程:
1 记整个训练集合为T,少数类样本集合为P,多数类样本集合为N。对P中的每一个样本xi,在整个训练集合T中搜索得到其最近的m个样本,记其中少数类样本数量为mi。 
3 对DANGER中的每一个样本点,采用普通的SMOTE算法生成新的少数类样本。
Borderline SMOTE-2和Borderline SMOTE-1是很类似的,区别是在得到DANGER集合之后,对于DANGER中的每一个样本点xi:
- Borderline SMOTE-1:从少数类样本集合P中得到k个最近邻样本,再随机选择样本点和xi作随机的线性插值产生新的少数类样本。(和普通SMOTE算法流程相同)
- Borderline SMOTE-2:从少数类样本集合P和多数类样本集合N中分别得到k个最近邻样本Pk和Nk。设定一个比例α,在Pk中选出α比例的样本点和xi作随机的线性插值产生新的少数类样本,方法同Borderline SMOTE-1;在Nk中选出1−α比例的样本点和xi作随机的线性插值产生新的少数类样本,此处的随机数范围选择的是(0,0.5),即使得产生的新的样本点更靠近少数类样本。
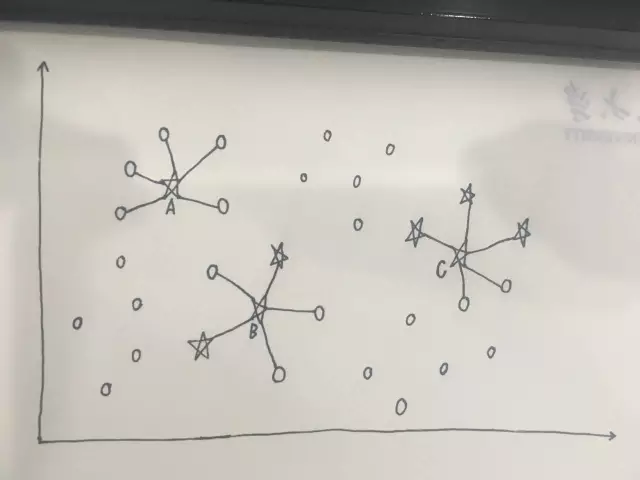
下图可以帮助我们直观理解Borderline SMOTE的基本想法。考虑最近的m=5个样本:
-
对于A而言,最近的5个样本均属于多数类样本,认为A为噪声点,在其附近产生少数类样本会使得噪声的影响更大
-
对于C而言,最近的5个样本中有3个属于少数类样本,2个属于多数类样本,此类样本是不容易被错分的,认为C为安全点
-
对于B而言,最近的5个样本中有2个属于少数类样本,3个属于多数类样本,此类样本容易被错分,认为B处于少数类的边界上,加入危险集
-
最终只会对B这类的样本点做SMOTE操作
三、综合采样
目前为止我们使用的重采样方法几乎都是只针对某一类样本:对多数类样本欠采样,对少数类样本过采样。也有人提出将欠采样和过采样综合的方法,解决样本类别分布不平衡和过拟合问题,本部分介绍其中的两个例子:SMOTE+Tomek links和SMOTE+ENN。
SMOTE+Tomek links
SMOTE+Tomek links方法的算法流程非常简单:
-
利用SMOTE方法生成新的少数类样本,得到扩充后的数据集T
-
剔除T中的Tomek links对。
普通SMOTE方法生成的少数类样本是通过线性差值得到的,在平衡类别分布的同时也扩张了少数类的样本空间,产生的问题是可能原本属于多数类样本的空间被少数类“入侵”(invade),容易造成模型的过拟合。
Tomek links对寻找的是那种噪声点或者边界点,可以很好地解决“入侵”的问题。
下图红色加号为SMOTE产生的少数类样本,可以看到,红色样本“入侵”到原本属于多数类样本的空间,这种噪声数据问题可以通过Tomek links很好地解决。
由于第一步SMOTE方法已经很好地平衡了类别分布,因此在使用Tomek links对的时候考虑剔除所有的Tomek links对(而不是只剔除Tomek links对中的多数类)。
SMOTE+ENN
SMOTE+ENN方法和SMOTE+Tomek links方法的想法和过程都是很类似的:
-
利用SMOTE方法生成新的少数类样本,得到扩充后的数据集T。
-
对T中的每一个样本使用kNN(一般k取3)方法预测,若预测结果和实际类别标签不符,则剔除该样本。