目录
VOLUME
volume:持久化存储卷,可以对数据进行持久化存储
网络存储大体可以分为3类:
1.传统的SAN或NAS设备构建的网络存储设备(脱离本机节点的存储设备):
SAN(storage area network:存储区域网络):iSCSI,FC (协议)
NAS(network additional storage:网络附加存储):nfs,cifs,http (协议)
2.分布式存储:文件系统级别或者块级别
glusterfs,rbd(ceph),cephfs
3.云存储:
EBS,Azure Disk,
查看k8s支持哪些存储
kubectl explain pods.spec.volumes
k8s支持的后端存储如下:
awsElasticBlockStore
azureDisk
azureFile
cephfs
cinder
configMap
csi
downwardAPI
emptyDir
fc
flexVolume
flocker
gcePersistentDisk
gitRepo # 本质也是一个emptyDir类型的存储卷,使用git克隆代码到本地的空目录中,运行pod时将存储卷挂载到容器,之后仓库中代码的变化,不会影响到容器。在pod删除时,emptyDir目录中的数据也不复存在。
glusterfs
hostPath
iscsi
nfs
persistentVolumeClaim
photonPersistentDisk
portworxVolume
projected
quobyte
rbd
scaleIO
secret
storageos
vsphereVolume
常用的如下:
emptyDir
hostPath
nfs
persistentVolumeClaim
glusterfs
cephfs
configMap
如何使用存储卷
需要经历如下步骤:
(1)定义pod的volume,这个volume指明它要关联到哪个存储上的
(2)在容器中要使用volume mounts(挂载存储)
经过以上两步才能使用存储卷
常用存储卷类型
1.EmptyDir
emptyDir类型的Volume在Pod分配到Node上时被创建,Kubernetes会在Node上自动分配一个目录,因此无需指定宿主机Node上对应的目录文件。 这个目录的初始内容为空,当Pod从Node上移除时,emptyDir中的数据会被永久删除。emptyDir Volume主要用于某些应用程序无需永久保存的临时目录,多个容器的共享目录等。
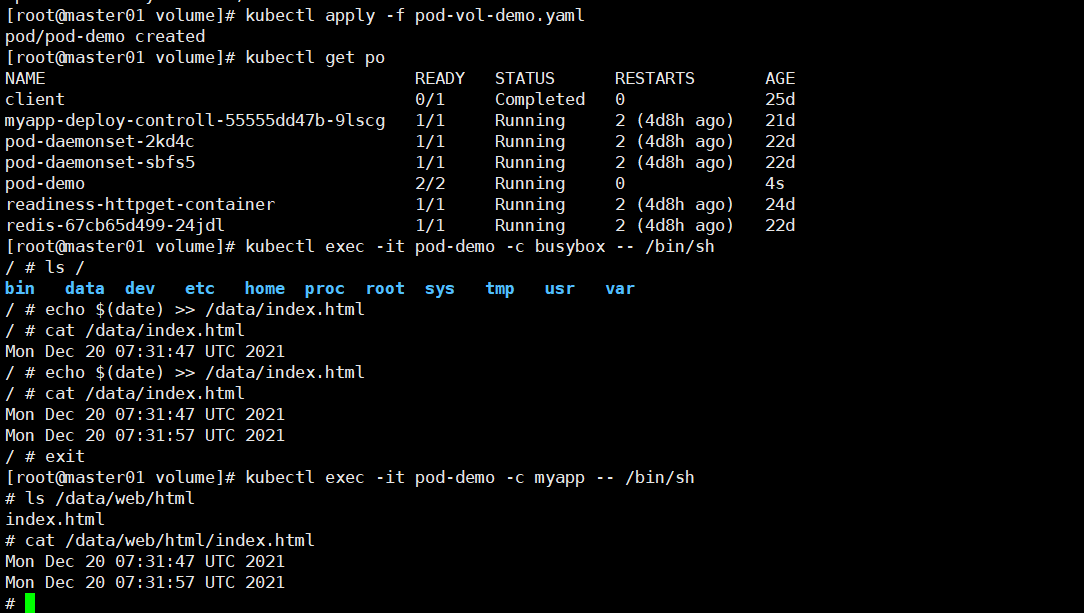
kubectl apply -f pod-vol-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-demo
namespace: default
labels: # <map[string]string> 映射类型,类似于json
app: myapp
tier: frontend
annotations:
master01/created-by: cluster admin
spec:
containers:
- name: myapp
image: nginx:1.20 # 使用镜像启动默认命令
ports:
- name: http
containerPort: 80
volumeMounts:
- name: html
mountPath: /data/web/html/
- name: busybox
image: busybox:latest
imagePullPolicy: IfNotPresent
volumeMounts:
- name: html
mountPath: /data/
command: # ["/bin/sh","-c","sleep 3600"] # 这里使用自定义的命令,而没使用镜像启动默认的命令,就是为了防止默认命令
启动之后会退出
- "/bin/sh"
- "-c"
- "sleep 7200"
volumes:
- name: html
emptyDir: {}
当pod数据卷被pod中的多个容器挂载时,一个容器中产生的数据,会被共享到pod中其他容器挂载在目录中。。。,如下图2
图2:
kubectl apply -f pod-vol-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-demo
namespace: default
labels: # <map[string]string> 映射类型,类似于json
app: myapp
tier: frontend
annotations:
master01/created-by: cluster admin
spec:
containers:
- name: myapp
image: nginx:1.20 # 使用镜像启动默认命令
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
volumeMounts:
- name: html
mountPath: /usr/share/nginx/html/
- name: busybox
image: busybox:latest # sidecar 为主容器提供主页文件
imagePullPolicy: IfNotPresent
volumeMounts:
- name: html
mountPath: /data/
command: # ["/bin/sh","-c","sleep 3600"] # 这里使用自定义的命令,而没使用镜像启动默认的命令,就是为了防止默认命令
启动之后会退出
- "/bin/sh"
- "-c"
- "while true;do echo $(date) >> /data/index.html;sleep 2;done"
volumes:
- name: html
emptyDir: {}
2.hostpath
hostPath Volume为Pod挂载宿主机上的目录或文件。 hostPath Volume使得容器可以使用宿主机的高速文件系统进行存储;hostpath(宿主机路径):节点级别的存储卷,在pod被删除,这个存储卷还是存在的,不会被删除,所以只要同一个pod被调度到同一个节点上来,在pod被删除重新被调度到这个节点之后,对应的数据依然是存在的。
查看hostpath存储卷的使用
kubectl explain pods.spec.volumes.hostPath
cat pod_volume_host.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-hostpath
spec:
containers:
- image: nginx
name: test-nginx
volumeMounts:
- mountPath: /test-nginx
name: test-volume
- image: tomcat
name: test-tomcat
volumeMounts:
- mountPath: /test-tomcat
name: test-volume
volumes:
- name: test-volume
hostPath:
path: /data1
type: DirectoryOrCreate
kubectl apply -f pod_volume_host.yaml
如果pod处于running状态,那么可以执行如下步骤测试存储卷是否可以被正常使用
kubectl exec -it test-hostpath -c test-nginx -- /bin/bash 登录到nginx容器
看是否存在目录 /test-nginx/,如果存在,说明存储卷挂载成功
kubectl exec -it test-hostpath -c test-tomcat-- /bin/bash 登录到tomcat容器
看是否存在目录 /test-tomcat/,如果存在,说明存储卷挂载成功
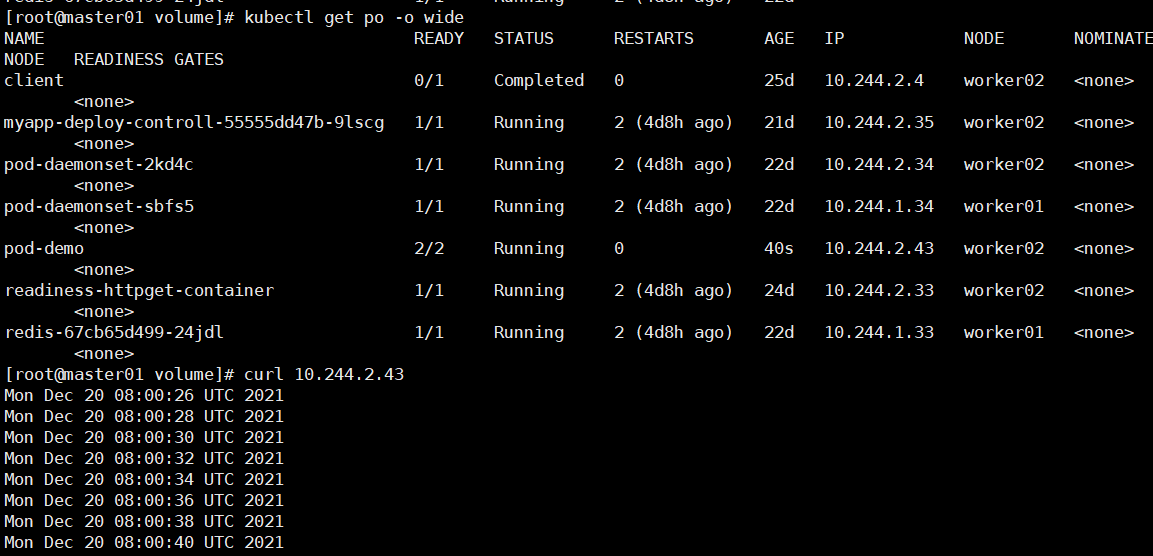
看pod被调度到哪个节点,通过kubectl get pods -o wide查看,如下图1,调度到node1
登录到node1上,查看是否有/data1这个目录,如果有,属于正常创建,那么在这个目录下生成一些文件,可以在刚才创建的pod下面的test-nginx和test-tomcat这两个容器里面看到这些文件,说明pod里面的容器挂载同一个存储卷时,它们是共享的
图1:

hostpath存储卷缺点:
单节点
pod删除之后重新创建必须调度到同一个node节点,数据才不会丢失
nfs,cephfs,glusterfs,pvc,storageclass
参考官网:https://kubernetes.io/docs/concepts/storage/volumes/#hostpath
3.nfs存储卷
1.创建nfs存储
以master1节点作为nfs服务端:
在master1上操作:
安装nfs:
yum install nfs-utils -y
创建共享目录:
mkdir /data/volumes -pv
cat /etc/exports
/data/volumes 192.168.1.0/24(rw,no_root_squash)
exportfs -arv
systemctl start nfs
在node1上手动挂载试试:
yum install nfs-utils -y
mount -t nfs 192.168.1.133:/data/volumes /mnt
df -h 可以看到已经挂载了
手动卸载:
umount /mnt
2.再回到master1节点:
再回到master1节点:
kubectl explain pod.spec.volumes.nfs
https://kubernetes.io/docs/concepts/storage/volumes#nfs
cat pod-nfs.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-nfs-volume
spec:
containers:
- name: test-nfs
image: nginx
ports:
- containerPort: 80
protocol: TCP
volumeMounts:
- name: nfs-volumes
mountPath: /usr/share/nginx/html
volumes:
- name: nfs-volumes
nfs:
path: /data/volumes
server: 192.168.1.133
path: /data/volumes #nfs的共享目录
server: master1 #nfs服务器地址
默认是读写挂载的
kubectl apply -f pod-nfs.yaml
kubectl get pods -o wide 显示如下:

刚才创建的pod在node1节点上
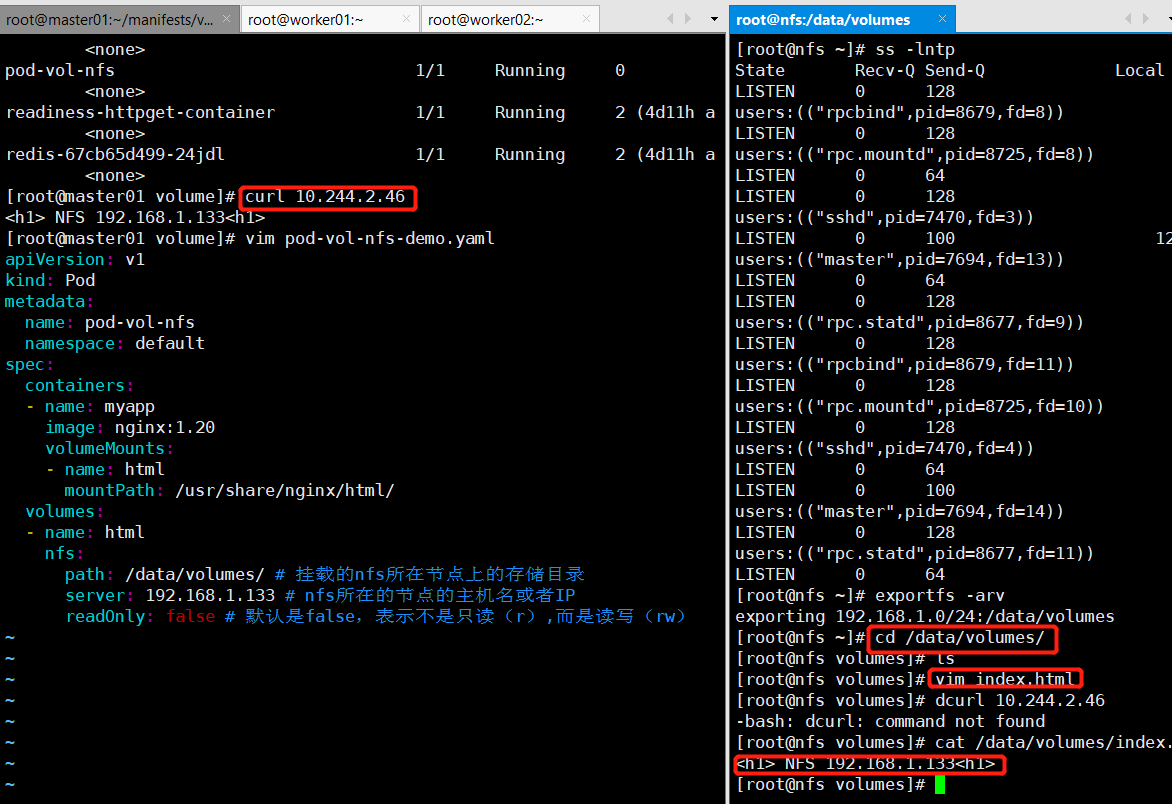
cd /data/volumes
创建一个共享的文件
cat index.html
<h1> NFS 192.168.1.133<h1>
curl 10.244.2.46
显示如下:
上面说明挂载nfs存储卷成功了,nfs支持多个客户端挂载,可以在多创建几个pod,挂载同一个nfs服务器;但是nfs如果宕机了,数据也就丢失了,所以需要使用分布式存储,常见的分布式存储有glusterfs和cephfs
作业:自己在上面pod里,在创建一个容器。这个容器也是使用nfs类型的volume,但是这个volume我们要求大家自己在nfs服务端创建一个共享目录,生成一个volume,然后被新的容器挂载使用。
练习:
apiVersion: v1
kind: Pod
metadata:
name: test-nfs-volume
spec:
containers:
- name: test-nfs
image: nginx
ports:
- containerPort: 80
protocol: TCP
volumeMounts:
- name: nfs-volumes
mountPath: /usr/share/nginx/html
- name: test-tomcat
image: tomcat
ports:
- containerPort: 8080
protocol: TCP
volumeMounts:
- name: nfs-tomcat
mountPath: /tomcat
volumes:
- name: nfs-volumes
nfs:
path: /data/volumes
server: 192.168.1.133
- name: nfs-tomcat
nfs:
path: /data/volumes1
server: 192.168.1.133
4.pvc存储卷
1.pv
PersistentVolume(PV)是群集中的一块存储,由管理员配置或使用存储类动态配置。 它是集群中的资源,就像节点是集群资源一样。 PV是容量插件,如Volumes,但其生命周期独立于使用PV的任何单个pod。 此API对象捕获存储实现的详细信息,包括NFS,iSCSI或特定于云提供程序的存储系统
2.pvc
PersistentVolumeClaim(PVC)是一个持久化存储卷,我们在创建pod时可以定义这个类型的存储卷。 它类似于一个pod。 Pod消耗节点资源,PVC消耗PV资源。 Pod可以请求特定级别的资源(CPU和内存)。 pvc在申请pv的时候也可以请求特定的大小和访问模式(例如,可以一次读/写或多次只读)。
3.pv和pvc

accessModes:kubectl explain.pvc.spec
不同的存储卷支持的访问访问模式:
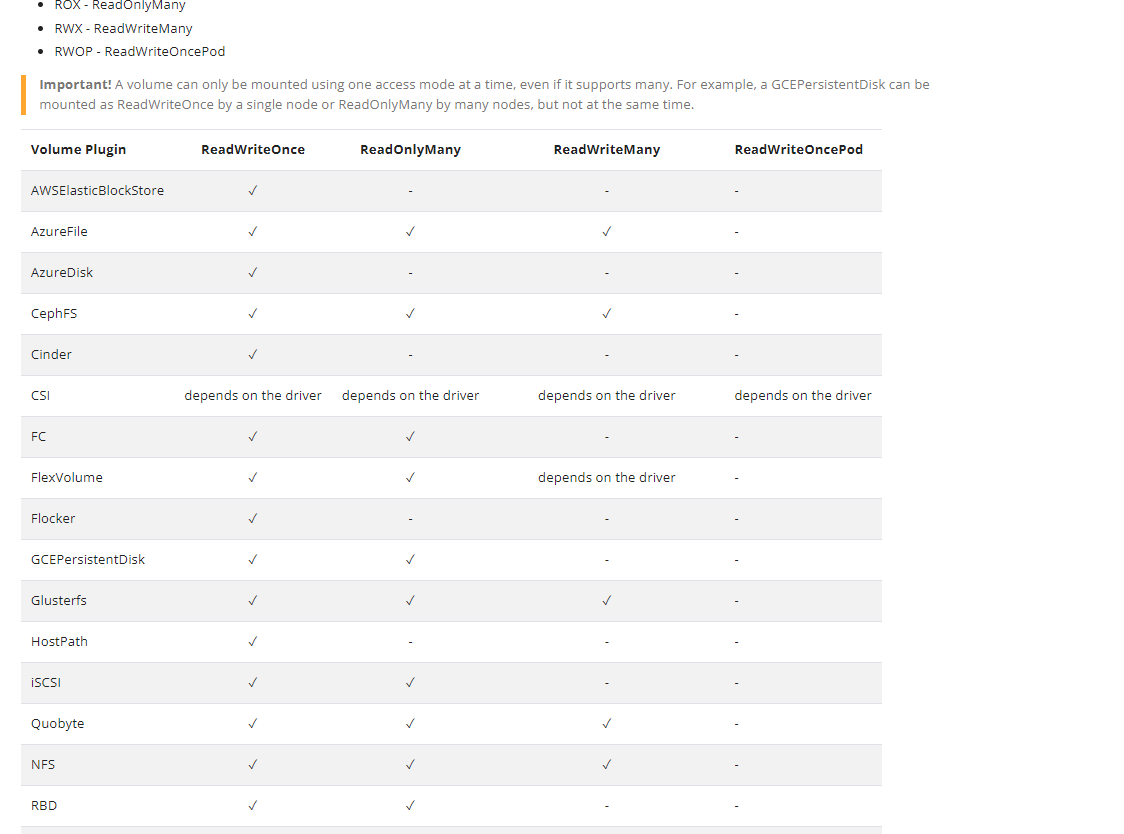
3.1 pv和pvc的生命周期
PV是群集中的资源。 PVC是对这些资源的请求,并且还充当对资源的索赔检查。 PV和PVC之间的相互作用遵循以下生命周期:
(1)pv的供应方式
可以通过两种方式配置PV:静态或动态。
静态的
集群管理员创建了许多PV。它们包含可供群集用户使用的实际存储的详细信息。它们存在于Kubernetes API中,可供使用。
动态的
当管理员创建的静态PV都不匹配用户的PersistentVolumeClaim时,群集可能会尝试为PVC专门动态配置卷。此配置基于StorageClasses:PVC必须请求存储类,管理员必须已创建并配置该类,以便进行动态配置。
(2)绑定
用户创建pvc并指定需要的资源和访问模式。在找到可用pv之前,pvc会保持未绑定状态
(3)使用
a)需要找一个存储服务器,把它划分成多个存储空间;
b)k8s管理员可以把这些存储空间定义成多个pv;
c)在pod中使用pvc类型的存储卷之前需要先创建pvc,通过定义需要使用的pv的大小和对应的访问模式,找到合适的pv;
d)pvc被创建之后,就可以当成存储卷来使用了,我们在定义pod时就可以使用这个pvc的存储卷
e)pvc和pv它们是一一对应的关系,pv如果被pvc绑定了,就不能被其他pvc使用了;
f)我们在创建pvc的时候,应该确保和底下的pv能绑定,如果没有合适的pv,那么pvc就会处于pending状态。
(4)回收策略
当我们创建pod时如果使用pvc做为存储卷,那么它会和pv绑定,当删除pod,pvc和pv绑定就会解除,解除之后和pvc绑定的pv卷里的数据需要怎么处理,目前,卷可以保留,回收或删除
Retain
Recycle (不推荐使用,1.15可能被废弃了)
Delete
• Retain
当删除pvc的时候,pv仍然存在,处于released状态,但是它不能被其他pvc绑定使用,里面的数据还是存在的,当我们下次再使用的时候,数据还是存在的,这个是默认的回收策略,管理员能够通过下面的步骤手工回收存储卷:
1)删除PV:在PV被删除后,在外部设施中相关的存储资产仍然还在;
2)手工删除遗留在外部存储中的数据;
3)手工删除存储资产,如果需要重用这些存储资产,则需要创建新的PV。
• Delete
删除pvc时即会从Kubernetes中移除PV,也会从相关的外部设施中删除存储资产,例如AWS EBS, 或者Cinder存储卷。
3.2 创建pv
(1)在nfs中导出多个存储目录,在nfs服务器上操作(这里是k8s的master1节点)
mkdir /data/volume_test/v{1,2,3,4,5,6,7,8,9,10} -p
cat /etc/exports
/data/volume_test/v1 192.168.0.0/24(rw,no_root_squash)
/data/volume_test/v2 192.168.0.0/24(rw,no_root_squash)
/data/volume_test/v3 192.168.0.0/24(rw,no_root_squash)
/data/volume_test/v4 192.168.0.0/24(rw,no_root_squash)
/data/volume_test/v5 192.168.0.0/24(rw,no_root_squash)
/data/volume_test/v6 192.168.0.0/24(rw,no_root_squash)
/data/volume_test/v7 192.168.0.0/24(rw,no_root_squash)
/data/volume_test/v8 192.168.0.0/24(rw,no_root_squash)
/data/volume_test/v9 192.168.0.0/24(rw,no_root_squash)
/data/volume_test/v10 192.168.0.0/24(rw,no_root_squash)
exportfs -arv 使配置文件生效
service nfs restart
(2)把上面的存储目录做成pv
kubectl explain pv 查看pv的创建方法
kubectl explain pv.spec.nfs 查看怎么把nfs定义成pv
参考:https://kubernetes.io/docs/concepts/storage/persistent-volumes
(3)创建pv(pv是集群级别的资源,不需要定义namespace)
cat pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: v1
spec:
capacity:
storage: 1Gi
accessModes: ["ReadWriteOnce"]
nfs:
path: /data/volume_test/v1
server: master1
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: v2
spec:
capacity:
storage: 2Gi
accessModes: ["ReadWriteMany"]
nfs:
path: /data/volume_test/v2
server: master1
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: v3
spec:
capacity:
storage: 3Gi
accessModes: ["ReadOnlyMany"]
nfs:
path: /data/volume_test/v3
server: master1
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: v4
spec:
capacity:
storage: 4Gi
accessModes: ["ReadWriteOnce","ReadWriteMany"]
nfs:
path: /data/volume_test/v4
server: master1
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: v5
spec:
capacity:
storage: 5Gi #pv的存储空间容量
accessModes: ["ReadWriteOnce","ReadWriteMany"]
nfs:
path: /data/volume_test/v5 #把nfs的存储空间创建成pv
server: master1
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: v6
spec:
capacity:
storage: 6Gi
accessModes: ["ReadWriteOnce","ReadWriteMany"]
nfs:
path: /data/volume_test/v6
server: master1
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: v7
spec:
capacity:
storage: 7Gi
accessModes: ["ReadWriteOnce","ReadWriteMany"]
nfs:
path: /data/volume_test/v7
server: master1
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: v8
spec:
capacity:
storage: 8Gi
accessModes: ["ReadWriteOnce","ReadWriteMany"]
nfs:
path: /data/volume_test/v8
server: master1
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: v9
spec:
capacity:
storage: 9Gi
accessModes: ["ReadWriteOnce","ReadWriteMany"]
nfs:
path: /data/volume_test/v9
server: master1
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: v10
spec:
capacity: #pv的存储空间容量
storage: 10Gi
accessModes: ["ReadWriteOnce","ReadWriteMany"]
nfs:
path: /data/volume_test/v10 #把nfs的存储空间创建成pv
server: master1
---
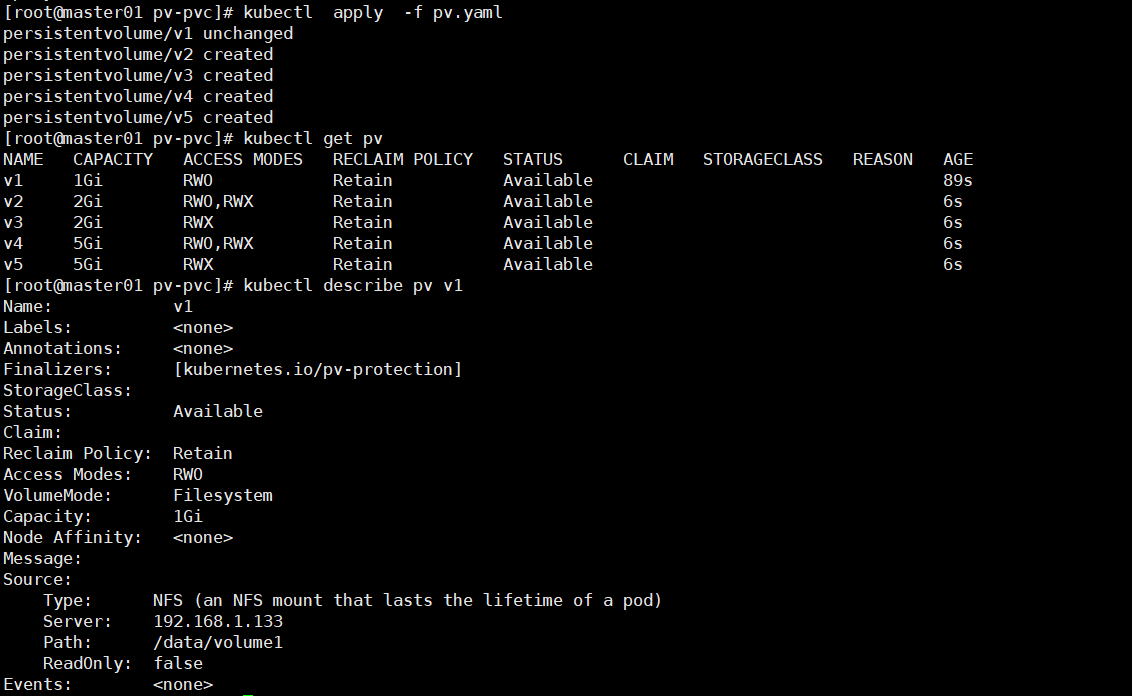
kubectl apply -f pv.yaml
kubectl get pv 显示如下:
(4)创建pvc
cat pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes: ["ReadWriteMany"]
resources: # 申请PV资源时,PV满足的最小值
requests:
storage: 2Gi
(5)创建pod
cat pod-pvc.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-pvc
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: nginx-html
mountPath: /usr/share/nginx/html
volumes:
- name: nginx-html
persistentVolumeClaim:
claimName: my-pvc
kubectl apply -f pod-pvc.yaml
注:
(1)我们每次创建pvc的时候,需要事先有划分好的pv,可能不方便,那么可以在创建pvc的时候直接动态创建一个pv这个存储类,pv事先是不存在的
(2)pvc和pv绑定,如果使用默认的回收策略retain,那么删除pvc之后,pv会处于released状态,我们想要继续使用这个pv,需要手动删除pv,kubectl delete pv pv_name,删除pv,不会删除pv里的数据,当我们重新创建pvc时还会和这个最匹配的pv绑定,数据还是原来数据,不会丢失.
5.StorageClass
详见个人本地文档
6.configmap和 secret
配置容器化应用的方式:
1.自定义命令行参数;
args:[]
2.把配置文件直接添加进镜像;
3.环境变量
(1) Cloud Native的应用程序一般可直接通过环境变量加载配置;
(2) 通过entrypoint脚本来预处理变量为配置文件中的配置信息;
4.存储卷:直接挂载配置文件到容器目录中
5.configmap
# 1.什么是Configmap?
Configmap是k8s中的资源对象,用于保存非机密性的配置的,数据可以用key/value键值对的形式保存,也可通过文件的形式保存。
# 2.Configmap能解决哪些问题?
我们在部署服务的时候,每个服务都有自己的配置文件,如果一台服务器上部署多个服务:nginx、tomcat、apache等,那么这些配置都存在这个节点上,假如一台服务器不能满足线上高并发的要求,需要对服务器扩容,扩容之后的服务器还是需要部署多个服务:nginx、tomcat、apache,新增加的服务器上还是要管理这些服务的配置,如果有一个服务出现问题,需要修改配置文件,每台物理节点上的配置都需要修改,这种方式肯定满足不了线上大批量的配置变更要求。 所以,k8s中引入了Configmap资源对象,可以当成volume挂载到pod中,实现统一的配置管理。
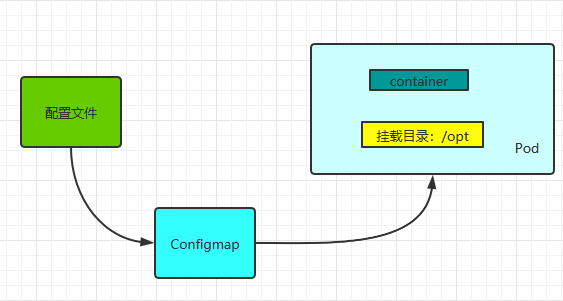
1、Configmap是k8s中的资源, 相当于配置文件,可以有一个或者多个Configmap;
2、Configmap可以做成Volume,k8s pod启动之后,通过 volume 形式映射到容器内部指定目录上;
3、容器中应用程序按照原有方式读取容器特定目录上的配置文件。
4、在容器看来,配置文件就像是打包在容器内部特定目录,整个过程对应用没有任何侵入。
# 3.Configmap应用场景
(1)、使用k8s部署应用,当你将应用配置写进代码中,更新配置时也需要打包镜像,configmap可以将配置信息和docker镜像解耦,以便实现镜像的可移植性和可复用性,因为一个configMap其实就是一系列配置信息的集合,可直接注入到Pod中给容器使用。configmap注入方式有两种,一种将configMap做为存储卷,一种是将configMap通过env中configMapKeyRef注入到容器中。
(2)、使用微服务架构的话,存在多个服务共用配置的情况,如果每个服务中单独一份配置的话,那么更新配置就很麻烦,使用configmap可以友好的进行配置共享。
# 4. 局限性
ConfigMap在设计上不是用来保存大量数据的。在ConfigMap中保存的数据不可超过1 MiB。如果你需要保存超出此尺寸限制的数据,可以考虑挂载存储卷或者使用独立的数据库或者文件服务。
Configmap创建方法
1.命令行直接创建
直接在命令行中指定configmap参数创建,通过--from-literal指定参数
kubectl create configmap tomcat-config --from-literal=tomcat_port=8080 --from-literal=server_name=myapp.tomcat.com
kubectl describe configmap tomcat-config
'''
Name: tomcat-config
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
server_name:
----
myapp.tomcat.com
tomcat_port:
----
8080
Events: <none>
'''
2.通过文件创建
通过指定文件创建一个configmap,--from-file=<文件>
vim nginx.conf
server {
server_name www.nginx.com;
listen 80;
root /home/nginx/www/
}
#定义一个key是www,值是nginx.conf中的内容
kubectl create configmap www-nginx --from-file=www=./nginx.conf
kubectl describe configmap www-nginx
'''
Name: www-nginx
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
www:
----
server {
server_name www.nginx.com;
listen 80;
root /home/nginx/www/
}
'''*
3.指定目录创建configmap
mkdir test-a
cd test-a/
cat my-server.cnf
'''
server-id=1
'''
cat my-slave.cnf
'''
server-id=2
'''
#指定目录创建configmap
kubectl create configmap mysql-config --from-file=/root/test-a/
#查看configmap详细信息
kubectl describe configmap mysql-config
'''
Name: mysql-config
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
my-server.cnf:
----
server-id=1
my-slave.cnf:
----
server-id=2
Events: <none>
'''
4编写configmap资源清单YAML文件
cat mysql-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
labels:
app: mysql
data:
master.cnf: |
[mysqld]
log-bin
log_bin_trust_function_creators=1
lower_case_table_names=1
slave.cnf: |
[mysqld]
super-read-only
log_bin_trust_function_creators=1
使用Configmap
1.通过环境变量引入:使用configMapKeyRef
#创建一个存储mysql配置的configmap
kubectl apply -f mysql-configmap.yaml
cat mysql-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
labels:
app: mysql
data:
log: "1"
lower: "1"
#创建pod,引用Configmap中的内容
kubectl apply -f mysql-pod.yaml
cat mysql-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
spec:
containers:
- name: mysql
image: busybox
command: [ "/bin/sh", "-c", "sleep 3600" ]
env:
- name: log_bin #定义环境变量log_bin
valueFrom:
configMapKeyRef:
name: mysql #指定configmap的名字
key: log #指定configmap中的key
- name: lower #定义环境变量lower
valueFrom:
configMapKeyRef:
name: mysql
key: lower
restartPolicy: Never
kubectl exec -it mysql-pod -- /bin/sh
/ # printenv
log_bin=1
lower=1
2.通过环境变量引入:使用envfrom
kubectl apply -f mysql-pod-envfrom.yaml
cat mysql-pod-envfrom.yaml
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod-envfrom
spec:
containers:
- name: mysql
image: busybox
imagePullPolicy: IfNotPresent
command: [ "/bin/sh", "-c", "sleep 3600" ]
envFrom:
- configMapRef:
name: mysql #指定configmap的名字
restartPolicy: Never
kubectl exec -it mysql-pod-envfrom -- /bin/sh
/ # printenv
lower=1
log=1
3.把configmap做成volume,挂载到pod
kubectl apply -f mysql-configmap.yaml
cat mysql-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
labels:
app: mysql
data:
log: "1"
lower: "1"
my.cnf: |
[mysqld]
User1=root1
kubectl apply -f mysql-pod-volume.yaml
cat mysql-pod-volume.yaml
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod-volume
spec:
containers:
- name: mysql
image: busybox
command: [ "/bin/sh","-c","sleep 3600" ]
volumeMounts:
- name: mysql-config
mountPath: /tmp/config
volumes:
- name: mysql-config
configMap:
name: mysql
restartPolicy: Never
kubectl exec -it mysql-pod-volume -- /bin/sh
/ # cd /tmp/config/
/tmp/config # ls
log lower my.cnf
Configmap热更新
kubectl edit configmap mysql
把logs: “1”变成log: “2”
保存退出
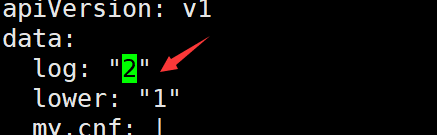
kubectl exec -it mysql-pod-volume -- /bin/sh
/ # cat /tmp/config/log
2
#发现log值变成了2,更新生效了
注意:
更新 ConfigMap 后:
使用该 ConfigMap 挂载的 Env 不会同步更新
使用该 ConfigMap 挂载的 Volume 中的数据需要一段时间(实测大概10秒)才能同步更新
secret
configMap保存数据为明文方式,而对于敏感数据需要加密存放,就要使用secret。保存在secret中的数据也是key/value键值对,只显示键,不显示值,即使显示值,值也是base64编码的加密数据。
比如:1.私钥和证书需要存放在secret当中;2.连接MySQL的密码可以保存在secret中;3.连接私有镜像的仓库的账户和密码可以使用secret保存。
kubectl create secret --help
# secret 的三种类型:
docker-registry Create a secret for use with a Docker registry
generic Create a secret from a local file, directory, or literal value
tls Create a TLS secret
generic:通用的,一般保存密码之类的
tls:保存私钥和类型
docker-registry:保存docker-registry的认证信息
docker运行一个镜像,首先是检查当前节点有没有,如果没有就要去仓库中托,如果我们用的是私有仓库,则必须要输入账号密码才能够访问,那么仓库账号和密码放在哪呢?
kubectl explain pod.spec
imagePullSecrets <[]Object> # 配置docker(或kubelet)拉取私有仓库镜像的secret(使用私有仓库账号和密码创建)的对象列表
kubectl create secret docker-registry <name> --docker-server=DOCKER_REGISTRY_SERVER --docker-username=DOCKER_USER --docker-password=DOCKER_PASSWORD --docker-email=DOCKER_EMAIL # 给私有仓库创建secret
'''
Create a secret based on a file, directory, or specified literal value.
A single secret may package one or more key/value pairs.
When creating a secret based on a file, the key will default to the basename of the file, and the
value will default to the file content. If the basename is an invalid key or you wish to chose your
own, you may specify an alternate key.
When creating a secret based on a directory, each file whose basename is a valid key in the
directory will be packaged into the secret. Any directory entries except regular files are ignored
(e.g. subdirectories, symlinks, devices, pipes, etc).
Examples:
# Create a new secret named my-secret with keys for each file in folder bar
kubectl create secret generic my-secret --from-file=path/to/bar
# Create a new secret named my-secret with specified keys instead of names on disk
kubectl create secret generic my-secret --from-file=ssh-privatekey=path/to/id_rsa
--from-file=ssh-publickey=path/to/id_rsa.pub
# Create a new secret named my-secret with key1=supersecret and key2=topsecret
kubectl create secret generic my-secret --from-literal=key1=supersecret
--from-literal=key2=topsecret
# Create a new secret named my-secret using a combination of a file and a literal
kubectl create secret generic my-secret --from-file=ssh-privatekey=path/to/id_rsa
--from-literal=passphrase=topsecret
# Create a new secret named my-secret from an env file
kubectl create secret generic my-secret --from-env-file=path/to/bar.env
'''
kubectl create secret generic mysql-root-password --from-literal=password=MyP@ss123
[root@master01 volume]# kubectl get secret
NAME TYPE DATA AGE
default-token-tqx6z kubernetes.io/service-account-token 3 26d
mysql-root-password Opaque 1 26s # Opaque 模糊类型
[root@master01 volume]# kubectl describe secret mysql-root-password
Name: mysql-root-password
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password: 9 bytes # 只显示密码是9个字节,明文密码被隐藏了
kubectl get secret mysql-root-password -o yaml
Name: mysql-root-password
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password: 9 bytes
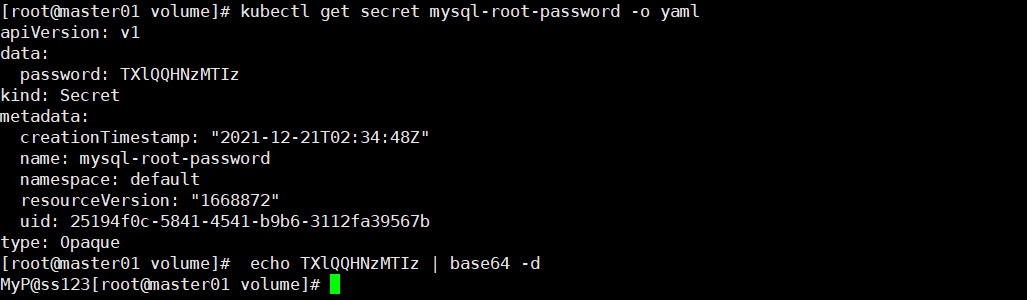
[root@master01 volume]# kubectl get secret mysql-root-password -o yaml
apiVersion: v1
data:
password: TXlQQHNzMTIz # 可以查看到加密后的密码,但是这种加密是对称加密,密码可以被解码。
kind: Secret
metadata:
creationTimestamp: "2021-12-21T02:34:48Z"
name: mysql-root-password
namespace: default
resourceVersion: "1668872"
uid: 25194f0c-5841-4541-b9b6-3112fa39567b
type: Opaque
echo TXlQQHNzMTIz | base64 -d # 如下图
在容器中引用secret:
kubectl apply -f pod-secret-1.yaml
cat pod-secret-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-secret-1
namespace: default
labels:
app: myapp
tier: frontend
annotations:
zhang.com/created-by: "cluster admin"
spec:
containers:
- name: myapp
image: nginx:1.20
ports:
- name: http
containerPort: 80
env:
- name: MYSQP_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-root-password
key: password
kubectl exec -it pod-secret-1 -- /bin/sh
查看容器中的环境变量:
printenv # 如下图
