Word Puzzles
| Time Limit: 5000MS | Memory Limit: 65536K | |||
| Total Submissions: 12090 | Accepted: 4547 | Special Judge | ||
Description
Word puzzles are usually simple and very entertaining for all ages. They are so entertaining that Pizza-Hut company started using table covers with word puzzles printed on them, possibly with the intent to minimise their client's perception of any possible delay in bringing them their order.
Even though word puzzles may be entertaining to solve by hand, they may become boring when they get very large. Computers do not yet get bored in solving tasks, therefore we thought you could devise a program to speedup (hopefully!) solution finding in such puzzles.
The following figure illustrates the PizzaHut puzzle. The names of the pizzas to be found in the puzzle are: MARGARITA, ALEMA, BARBECUE, TROPICAL, SUPREMA, LOUISIANA, CHEESEHAM, EUROPA, HAVAIANA, CAMPONESA.
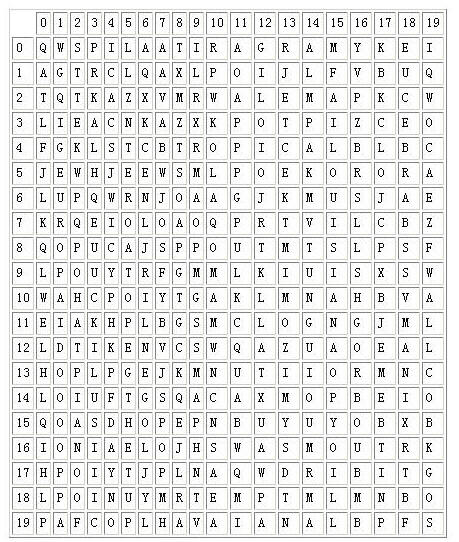
Your task is to produce a program that given the word puzzle and words to be found in the puzzle, determines, for each word, the position of the first letter and its orientation in the puzzle.
You can assume that the left upper corner of the puzzle is the origin, (0,0). Furthemore, the orientation of the word is marked clockwise starting with letter A for north (note: there are 8 possible directions in total).
Even though word puzzles may be entertaining to solve by hand, they may become boring when they get very large. Computers do not yet get bored in solving tasks, therefore we thought you could devise a program to speedup (hopefully!) solution finding in such puzzles.
The following figure illustrates the PizzaHut puzzle. The names of the pizzas to be found in the puzzle are: MARGARITA, ALEMA, BARBECUE, TROPICAL, SUPREMA, LOUISIANA, CHEESEHAM, EUROPA, HAVAIANA, CAMPONESA.
Your task is to produce a program that given the word puzzle and words to be found in the puzzle, determines, for each word, the position of the first letter and its orientation in the puzzle.
You can assume that the left upper corner of the puzzle is the origin, (0,0). Furthemore, the orientation of the word is marked clockwise starting with letter A for north (note: there are 8 possible directions in total).
Input
The first line of input consists of three positive numbers, the number of lines, 0 < L <= 1000, the number of columns, 0 < C <= 1000, and the number of words to be found, 0 < W <= 1000. The following L input lines, each one of size C characters, contain the word puzzle. Then at last the W words are input one per line.
Output
Your program should output, for each word (using the same order as the words were input) a triplet defining the coordinates, line and column, where the first letter of the word appears, followed by a letter indicating the orientation of the word according to the rules define above. Each value in the triplet must be separated by one space only.
Sample Input
20 20 10 QWSPILAATIRAGRAMYKEI AGTRCLQAXLPOIJLFVBUQ TQTKAZXVMRWALEMAPKCW LIEACNKAZXKPOTPIZCEO FGKLSTCBTROPICALBLBC JEWHJEEWSMLPOEKORORA LUPQWRNJOAAGJKMUSJAE KRQEIOLOAOQPRTVILCBZ QOPUCAJSPPOUTMTSLPSF LPOUYTRFGMMLKIUISXSW WAHCPOIYTGAKLMNAHBVA EIAKHPLBGSMCLOGNGJML LDTIKENVCSWQAZUAOEAL HOPLPGEJKMNUTIIORMNC LOIUFTGSQACAXMOPBEIO QOASDHOPEPNBUYUYOBXB IONIAELOJHSWASMOUTRK HPOIYTJPLNAQWDRIBITG LPOINUYMRTEMPTMLMNBO PAFCOPLHAVAIANALBPFS MARGARITA ALEMA BARBECUE TROPICAL SUPREMA LOUISIANA CHEESEHAM EUROPA HAVAIANA CAMPONESA
Sample Output
0 15 G 2 11 C 7 18 A 4 8 C 16 13 B 4 15 E 10 3 D 5 1 E 19 7 C 11 11 H
Source
大致题意:给一个表格,再给w个单词,要求每个单词首字母在表格中出现的位置和延伸方向,有8种方向!
分析:因为给了很多串,那么把这些串都放到trie树里.每次暴力枚举所有位置和方向,dfs扩展,将经过的节点标记,非常暴力,但是可以过.
考虑对这个算法优化,事实上不需要对每一个点都dfs扩展,只需要对第一列和最后一列以及第一行和最后一行上的每个点dfs一下就可以了,这样可以覆盖到每条对角线和行列.然后考虑到每次扩展实际上就是在trie上匹配字符串,如果失配了不走了,这样的话就需要搜索每个点.那么可以利用AC自动机来加速.利用fail指针,如果当前匹配的字符串下一位没有节点能与当前位置匹配,就跳到失配指针所指的位置上去.
#include <cstdio> #include <queue> #include <cstring> #include <iostream> #include <algorithm> using namespace std; int l, c, tot = 1, w,ans[1010][3], len[1010]; char s[1010][1010], s2[1010],dir[1010]; int dx[] = { -1, -1, 0, 1, 1, 1, 0, -1 }; int dy[] = { 0, 1, 1, 1, 0, -1, -1, -1 }; struct node { int tr[30], id, fail; }e[1010 * 110]; void insert(char *ss,int x) { int len = strlen(ss); int u = 1; for (int i = 0; i < len; i++) { int t = ss[i] - 'A'; if (!e[u].tr[t]) e[u].tr[t] = ++tot; u = e[u].tr[t]; } e[u].id = x; } void build() { for (int i = 0; i < 26; i++) e[0].tr[i] = 1; queue <int> q; q.push(1); while (!q.empty()) { int u = q.front(); q.pop(); int fail = e[u].fail; for (int i = 0; i < 26; i++) { int y = e[u].tr[i]; if (y) { e[y].fail = e[fail].tr[i]; q.push(y); } else e[u].tr[i] = e[fail].tr[i]; } } } void solve(int sx, int sy, int dirr) { int x = sx, y = sy, u = 1; while (x >= 1 && x <= l && y >= 1 && y <= c) { while (u && !e[u].tr[s[x][y] - 'A']) u = e[u].fail; u = e[u].tr[s[x][y] - 'A']; if (e[u].id) { ans[e[u].id][1] = x - (len[e[u].id] - 1) * dx[dirr]; ans[e[u].id][2] = y - (len[e[u].id] - 1) * dy[dirr]; dir[e[u].id] = dirr; } x += dx[dirr]; y += dy[dirr]; } } int main() { scanf("%d%d%d", &l, &c, &w); for (int i = 1; i <= l; i++) scanf("%s", s[i] + 1); for (int i = 1; i <= w; i++) { scanf("%s", s2); len[i] = strlen(s2); insert(s2,i); } build(); for (int i = 1; i <= l; i++) for (int j = 0; j < 8; j++) solve(i, 1, j), solve(i, c, j); for (int i = 1; i <= c; i++) for (int j = 0; j < 8; j++) solve(1, i, j), solve(l, i, j); for (int i = 1; i <= w; i++) printf("%d %d %c ", ans[i][1] - 1, ans[i][2] - 1, dir[i] + 'A'); return 0; }