一、先是一些整除的性质:
void fenjie(int x) { for (int i = 2; i <= sqrt(x); i++) { while (x % i == 0) { if (!vis[i]) { vis[i] = 1; ans[++tot] = i; } x /= i; } } if (x > 1) ans[++tot] = x; }
分析:这个算法的关键有三个:1.如果除以一个因数就把它除尽. 2.记录这个数有没有进入答案. 3.最后可能还剩下一个数,至于为什么能剩下一个数,我们有一个很重要的定理:每一个数的质因数只有一个大于sqrt(n)的,根据唯一分解定律可以很容易证明.
下面是同余和带余除法的相关知识:
•int gcd(int a, int b) { if (b==0) return a; return gcd(b, a % b); }
int exgcd(int a, int b, int &x, int &y) { if (!b) { x = 1; y = 0; return a; } int r = exgcd(b, a%b, x, y); int t = x; x = y; y = t - a / b*y; return r; }
这只是一组特解,如果我们要求出所有解该怎么办?可以得到一个解系:x = x0 + kb,y = y0 - ka。
不过运用这一个算法有个重要的前提,我们要求解的ax+by=c的c必须等于gcd(a,b),如果不等于该如何处理呢,可以看我的另一篇博客:青蛙的约会:传送门
另外,第一件事要先判断有没有解,利用裴蜀定理即可.
七、逆元
存在的充要条件为(a,b)=1
int inv(int a, int b) { int x, y; exgcd(a, b, x, y); return x; }
八、线性求逆元
for (inv[1] = 1, i = 2; i <= n; ++i) inv[i] = (p - p / i) * inv[p % i] % p;
程序里是p-p/i而不是p/i是为了避免负数.
int sieve(int n, bool isprime[], int prime[]) { int tot = 0; for (int i = 2; i <= n; ++i) isprime[i] = 1; for (int i = 2; i <= n; ++i) if (isprime[i]) { prime[++tot] = i; for (int j = i + i; j <= n; j += i) isprime[j] = 0; } return tot; }
复杂度O(nloglogn)
例7:求[1,10^7]内的所有素数。内存限制1MB
分析:内存只有1mb开不下这么大的数组,但是只要求一个答案,我们可以分段来做,假设我们分为k段,第i段为[l,r],我们枚举不超过sqrt(r)的素数并筛掉[l,r]的数即可,只是枚举素数总要保存的吧,那么我们用一种比较玄学的方法:保存[1,sqrt(10^7)]的素数,这样如果区间被覆盖在左边,直接就可以得到答案,如果被覆盖在右边,我们也稍微枚举一下就好了.
但是这个复杂度还是太高,能不能做到O(n)呢?其实可以,如果我们能够保证每一个数只被删除一次就可以了,怎么保证呢?我们利用数的最小分解来分析:比如一个数18,它的分解是唯一的,但是分解的数的排列并不是唯一的,比如2*3*3,3*2*3,我们只让它被第一个删除,怎么样才能做到呢?我们每次添加一个比当前已经分解的最小的质数更小的质数,比如已有了3*3,我们就只能添加2,如果已有2*3,我们就不能再继续搜了,为什么呢?如果我们添加一个5,5*2*3可以先被2*3*5搜到,这样被重复搜索了.这个线性筛的本质就是我们强行给它定一个搜索的顺序和限制,使得每一个数只能被删除一次.
int sieve(int n, int f[], int prime[]) { int tot = 0; for (int i = 2; i <= n; ++i) { if (!f[i]) prime[++tot] = f[i] = i; for (int j = 1; j <= tot; ++j) { int t = i * prime[j]; if (t > n) break; f[t] = prime[j]; if (f[i] == prime[j]) break; } } }
这个代码中f[i]就是i被分解的最小质因数,如果我们枚举的素数正好等于f[i],也就不能继续了.
十、线性同余方程
int CRT(const int a[], const int m[], int n) { int M = 1, ret = 0; for (int i = 1; i <= n; ++i) M *= m[i]; for (int i = 1; i <= n; ++i) { int Mi = M / m[i], ti = inv(Mi, m[i]); ret = (ret + a[i] * Mi * ti) % M; } return ret; }
例8:今有物不知其数,三三数之剩二,五五数之剩三,七七数之剩二,问物几何?
分析:
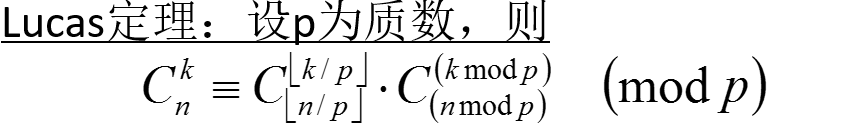


第二个证明的n=p1^k1*p2^k2*...*pn^kn,不等于第一个证明中的n,当初为此迷惑了半天......
由此可以看出积性函数可以先拆成乘积的形式然后再合并就能得到公式.
欧拉函数的性质:1.phi(p^k)=(p-1)*p^(k-1) 2.积性函数(当a,b互质时!) 3.当b是质数,a%b==0,phi(a*b)=phi(a)*b,显然也可以利用积性函数来得到.
代码:
int phi(int x) { int ret = x; for (int i = 2; i * i <= x; ++i) if (x % i == 0) { while (x % i == 0) x /= i; ret = ret / i * (i - 1); } if (x > 1) ret = ret / x * (x - 1); return ret; }
这份代码先除后乘的原因是防止溢出,我们在比赛的时候,如果数据范围大也要这么处理!
其实欧拉函数也可以像筛素数那样打一个表出来,具体的实现:
for(i=1; i<=maxn; i++) p[i]=i; for(i=2; i<=maxn; i+=2) p[i]/=2; for(i=3; i<=maxn; i+=2) if(p[i]==i) { for(j=i; j<=maxn; j+=i) p[j]=p[j]/i*(i-1); }
例10:
2705: [SDOI2012]Longge的问题
Submit: 3160 Solved: 1973
[Submit][Status][Discuss]
Description
Input
Output
Sample Input
Sample Output
HINT
【数据范围】
对于60%的数据,0<N<=2^16。
对于100%的数据,0<N<=2^32。
Source
分析:如果直接暴力求gcd,n^2的枚举时间加上每次求gcd的时间,直接爆掉,那么能不能用更好的方法做呢?
我们可以换个思路,要求Σgcd(i,n),我们假设gcd(i,n) = g,也就是我们要求以g为最大公约数的(i,n)有多少对,然后g对答案的贡献就是g*个数,显然,这个g是n的约数,对于约数的枚举我们有一个技巧,就是只枚举到它的sqrt即可,和它成对的一个约数就是n/i,前提是i != sqrt(n).如果g = 1,我们可以直接用欧拉函数来统计,如果g != 1呢?那么我们可以把i,n写作i = i'*g,n = n'*g,i和n同时除以g,那么n和i就互质了,这样直接用欧拉函数就可以解决问题了.
#include <cstdio> #include <queue> #include <cstring> #include <iostream> #include <algorithm> #include <cmath> using namespace std; long long n,ans; long long phi(long long x) { long long res = x; for (long long i = 2; i <= sqrt(x); i++) { if (x % i == 0) { while (x % i == 0) x /= i; res = res / i * (i - 1); } } if (x > 1) res = res / x * (x - 1); return res; } int main() { scanf("%lld", &n); for (long long i = 1; i <= sqrt(n); i++) { if (n % i == 0) { ans += i * phi(n / i); if (i * i < n) ans += n / i * phi(i); } } printf("%lld ", ans); return 0; }
例11:
2186: [Sdoi2008]沙拉公主的困惑
Time Limit: 10 Sec Memory Limit: 259 MBSubmit: 4549 Solved: 1567
[Submit][Status][Discuss]
Description
大富翁国因为通货膨胀,以及假钞泛滥,政府决定推出一项新的政策:现有钞票编号范围为1到N的阶乘,但是,政府只发行编号与M!互质的钞票。房地产第一大户沙拉公主决定预测一下大富翁国现在所有真钞票的数量。现在,请你帮助沙拉公主解决这个问题,由于可能张数非常大,你只需计算出对R取模后的答案即可。R是一个质数。
Input
第一行为两个整数T,R。R<=10^9+10,T<=10000,表示该组中测试数据数目,R为模后面T行,每行一对整数N,M,见题目描述 m<=n
Output
共T行,对于每一对N,M,输出1至N!中与M!素质的数的数量对R取模后的值
Sample Input
4 2
Sample Output
数据范围:
对于100%的数据,1 < = N , M < = 10000000
#include <cstdio> #include <queue> #include <cstring> #include <iostream> #include <algorithm> #include <cmath> using namespace std; const int maxn = 10000001; int t, p,n,m; long long f[maxn], ans[maxn],prime[664580],niyuan[maxn]; bool vis[maxn]; void init() { long long tot = 0; for (int i = 2; i <= maxn; i++) { if (!vis[i]) prime[++tot] = i; for (int j = 1; j <= tot; j++) { if (prime[j] * i > maxn) break; vis[prime[j] * i] = 1; if (i % prime[j] == 0) break; } } f[1] = 1; for (int i = 2; i <= maxn; i++) f[i] = f[i - 1] * i % p; niyuan[1] = 1; for (int i = 2; i <= maxn && i < p; i++) niyuan[i] = (p - p / i) * niyuan[p % i] % p; ans[1] = 1; for (int i = 2; i <= maxn; i++) { if (!vis[i]) ans[i] = ans[i - 1] * (i - 1) % p * niyuan[i % p] % p; else ans[i] = ans[i - 1]; } } int main() { scanf("%d%d", &t, &p); init(); for (int i = 1; i <= t; i++) { scanf("%d%d", &n, &m); printf("%d ", f[n] * ans[m] % p); } return 0; }
十三、欧拉定理


不过求逆元一般是用扩展欧几里得来做,常数小,效率高,这两种方法的限制较多.

3884: 上帝与集合的正确用法
Time Limit: 5 Sec Memory Limit: 128 MBSubmit: 2462 Solved: 1093
[Submit][Status][Discuss]
Description
Input
Output
Sample Input
2
3
6
Sample Output
1
4
HINT
 --图片摘自Codeplay0314的博客.
--图片摘自Codeplay0314的博客.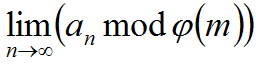 存在,那么
存在,那么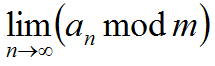 也一定存在。当m=1时,
也一定存在。当m=1时,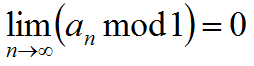 存在,所以
存在,所以
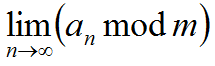 存在.
存在.#include <cstdio> #include <queue> #include <cstring> #include <iostream> #include <algorithm> #include <cmath> using namespace std; int t, p; long long qpow(long long a, long long b, long long mod) { long long res = 1; while (b) { if (b & 1) res = res * a % mod; b >>= 1; a = a * a % mod; } return res; } long long phi(int x) { long long res = x; for (long long i = 2; i <= sqrt(x);i++) { if (x % i == 0) { while (x % i == 0) x /= i; res = res / i * (i - 1); } } if (x > 1) res = res / x * (x - 1); return res; } long long solve(int x) { if (x == 1) return 0; long long t = phi(x); return qpow(2, solve(t) + t, x); } int main() { scanf("%d", &t); while (t--) { scanf("%d", &p); printf("%lld ",solve(p)); } return 0; }
十四、积性函数


线性筛与积性函数之间有一定的联系,如果题目要求我们求出质数的同时求出欧拉函数值,我们可以利用积性函数的性质在筛法中求出欧拉函数值:
void shai() { phi[1] = 1; for (int i = 2; i <= maxn; i++) { if (!vis[i]) { prime[++tot] = i; phi[i] = i - 1; } for (int j = 1; j <= tot; j++) { int t = prime[j] * i; if (t > maxn) break; vis[t] = 1; if (i % prime[j] == 0) { phi[t] = phi[i] * j; break; } else phi[t] = phi[i] * phi[j]; } } }
现在来解释一下代码:这个线性筛和之前的模板不太一样,原理是相同的,当i % prime[j] == 0的时候就代表找到了最小表示的最小质数,不能继续往下筛了,如果i是一个质数,那么它的phi肯定是i-1,如果i,prime[j]互质,那么利用积性函数的定义直接来就好了。
否则, 如果i刚好是prime[j]的倍数,则利用欧拉函数的第三条性质即可.
例13:
2818: Gcd
Time Limit: 10 Sec Memory Limit: 256 MBSubmit: 5930 Solved: 2636
[Submit][Status][Discuss]
Description
给定整数N,求1<=x,y<=N且Gcd(x,y)为素数的
数对(x,y)有多少对.
Input
一个整数N
Output
如题
Sample Input
Sample Output
HINT
hint
对于样例(2,2),(2,4),(3,3),(4,2)
1<=N<=10^7
Source
分析:这道题是比较典型的gcd(a,b) = c求个数之类的问题,做法和这道题:传送门差不多,首先我们假设gcd(a,b) = g,这样不能直接统计,那么我们可以得到a = a' * g,b = b' * g, (a',b') = 1,同时约掉g,就变成了求互质的数的个数。不过这和bzoj2705有点不太一样,它并没有一个确定的数,不过我们可以分类讨论.
1.如果x < y,那么从1到maxn枚举y,答案就是Σφ(y).
2.如果x > y,一样的,不过答案就是Σφ(x).
3.如果x = y,那么情况只有一种:x = y = 1,但是这种情况已经在上面两种情况中被算了,所以总的答案就是2*Σφ(i) - 1 (1 <= i <= maxn)
那么这个maxn就很显然了,就是n除以当前的g.
这个题的数据范围有点大,需要用到线性算法,我们既要求出质数,又要推出欧拉函数值,那么直接用线性筛就能解决.
#include <cstdio> #include <queue> #include <cstring> #include <iostream> #include <algorithm> #include <cmath> using namespace std; int n,tot = 0; const int maxn = 10000010; int p[maxn], prime[maxn], f[maxn]; long long sum[maxn]; long long ans; void init() { p[1] = 1; for (int i = 2; i <= n; ++i) { if (!f[i]) { prime[++tot] = f[i] = i; p[i] = i - 1; } for (int j = 1; j <= tot; ++j) { long long t = i * prime[j]; if (t > n) break; f[t] = prime[j]; p[t] = p[i] * (prime[j] - (prime[j] < f[i])); if (prime[j] == f[i]) break; } } } int main() { scanf("%d", &n); init(); for (int i = 1; i <= n; i++) sum[i] = sum[i - 1] + p[i]; for (int i = 1; i <= tot; i++) ans += 2 * sum[n / prime[i]] - 1; printf("%lld", ans); return 0; }
例14:




分析:这道题对于我这种蒟蒻来说还是很有难度啊。
思路非常巧妙,既然不定方程要有有限个数解,那么这个肯定会对解有所限制,也就是本题中的正整数.这个时候我们要表示出方程中的一个根x,设z = n!,那么x=yz/(y-z),这样的话不能得到答案,我们要得到的式子一定是分母只能有乘积的形式,并且同一个字母不能同时在分子分母中出现,因为我们就是利用正整数的整除性来求解的,可以看出x和y都大于z,所以我们设y = z + d,带入,就消掉了y,可以得到x = z^2/d + z,因为x是正整数,所以z^2/d必须是整数,所以d是z^2的因子,那么我们只需要求出z^2有多少个约数就好了.
求约数的个数要用到乘法原理和线性筛,z可以表示为p1^k1 * p2^k2 * p3^k3*...*pn^kn这种形式,每个质因数可以选1到ki个或不选,而约数就是由不同的质因子通过相乘组合起来的,所以约数的个数就等于(k1 + 1)*(k2 + 1)*...*(kn + 1),而我们要求z^2的因子个数,总不可能直接平方吧......可以发现每个质因子的次数扩大了两倍,那么每个质因子就有2*ki + 1种选择,和上面一样直接乘法原理出答案.
因为z = n!,所以枚举1到n中的质数i的倍数,看i出现了几次,就能得到ki.
#include<iostream> #include<cstdio> #include<cstring> #include<queue> #include<cmath> using namespace std; const int mod = 1000000007; int prime[1000010], tot, cnt[1000010],n; bool vis[1000010]; long long ans = 1; void init() { for (int i = 2; i <= n; i++) { if (!vis[i]) prime[++tot] = i; for (int j = 1; j <= tot; j++) { if (prime[j] * i > n) break; vis[prime[j] * i] = 1; if (i % prime[j] == 0) break; } } } int main() { scanf("%d", &n); init(); for (int i = 1; i <= tot; i++) for (int j = prime[i]; j <= n; j += prime[i]) for (int k = j; k % prime[i] == 0; k /= prime[i]) cnt[i]++; for (int i = 1; i <= tot; i++) ans = (ans * 1LL * (cnt[i] * 2 + 1) % mod) % mod; printf("%lld ", ans); return 0; }
例15:
You are given array a with n elements and the number m. Consider some subsequence of a and the value of least common multiple (LCM) of its elements. Denote LCM as l. Find any longest subsequence of a with the value l ≤ m.
A subsequence of a is an array we can get by erasing some elements of a. It is allowed to erase zero or all elements.
The LCM of an empty array equals 1.
The first line contains two integers n and m (1 ≤ n, m ≤ 10^6) — the size of the array a and the parameter from the problem statement.
The second line contains n integers ai (1 ≤ ai ≤ 10^9) — the elements of a.
In the first line print two integers l and kmax (1 ≤ l ≤ m, 0 ≤ kmax ≤ n) — the value of LCM and the number of elements in optimal subsequence.
In the second line print kmax integers — the positions of the elements from the optimal subsequence in the ascending order.
Note that you can find and print any subsequence with the maximum length.
7 8 6 2 9 2 7 2 3
6 5 1 2 4 6 7
6 4 2 2 2 3 3 3
2 3 1 2 3
一句话题意:

分析:对于一个数k,它的所有约数的lcm肯定不大于k,也就是说对于每一个[1,m]中的数,我们只需要求出它的约数是a中的数的个数就好了,难道又要用筛法或质因数分解吗?其实不必,我们可以想到一个O(nm)的做法:枚举[1,m]中的每一个数,然后看看a中有多少个数整除它,显然T掉,能不能改进一下呢?
对于枚举的优化,要么是减少枚举层数,要么是减少对答案没有贡献的枚举,我们可以只用枚举整除数i的数,然后看看a中有没有这个数,这个操作可以用一个vis数组,只需要O(1)的时间查询。不过ai <= 10^9,我们似乎开不下这么大的vis数组,观察题目,发现m只有10^6,大于10^6的数我们可以不用考虑.
其实相对于枚举约数,枚举倍数更容易,我们从一个数扩展,将它的倍数的计数器累加即可,其实两种方法都可以.
#include <cstdio> #include <queue> #include <cstring> #include <iostream> #include <algorithm> #include <cmath> using namespace std; const int maxn = 1000010; int num[maxn], cnt[maxn],tot,a[maxn],ans,id,vis[maxn]; int n, m; int main() { scanf("%d%d", &n, &m); for (int i = 1; i <= n; i++) { int t; scanf("%d", &t); a[i] = t; if (t > m) continue; ++num[t]; } for (int i = 1; i <= n; i++) { if (!vis[a[i]]) for (int j = a[i]; j <= m; j += a[i]) cnt[j] += num[a[i]]; vis[a[i]] = 1; } for (int i = 1; i <= m; i++) if (cnt[i] > ans) { ans = cnt[i]; id = i; } printf("%d %d ", id, ans); for (int i = 1; i <= n; i++) if (id % a[i] == 0) printf("%d ", i); return 0; }
题意:已知n个数,第i个为ci,给定一个数x mod ci的结果,再给点一个k,问能不能知道x mod k的值?
分析:刚看题目的我一脸蒙蔽,对题意有点不理解,能的情况似乎有很多,我该从哪里下手呢?
先从不能的情况来看,可以知道,如果不能知道x mod k的值,当且仅当有两个解x1,x2, x1 ≡ x2(mod ci)x1 ≢ x2 (mod k) 左边这个是不同余的意思,为什么是这样的呢?因为题目中说x mod k的值是唯一的,我们却会出现两个满足题意的x值 mod k的值不同,这就矛盾了。
那么我们怎样求解这两个同余式呢?如果x1 ≡ x2(mod ci),那么(x1 - x2) % ci = 0,所以x1 - x2一定是ci的最小公倍数的倍数,然后对第二个式子变形一下:(x1 - x2) % k != 0,也就是说k不整除lcm{ci}那么这道题就变成了要我们求解lcm{ci}到底是不是k的倍数。
但是直接求会lcm会爆掉啊,如果取模的话涉及到除法要求逆元复杂度又会爆炸,该怎么处理?正确的方法是分解质因数:将k表示为p1^k1 * p2 ^ k2 * ... *pn ^ kn的形式,如果lcm{ci}是k的倍数,那么p1^k1、p2^k2...pn^kn一定会全部出现在某些ci中,我们只需要在读入的时候检验一下打个标记就好了。一位大神说的对:lcm就是质因子的并集,gcd就是质因子的交集,遇到gcd、lcm,分解一下质因子不失为一种好的方法。
#include<iostream> #include<cstdio> #include<cstring> #include<queue> #include<cmath> using namespace std; int n, k, c,tot,prime[100010]; bool vis[100010]; int main() { scanf("%d%d", &n, &k); for (int i = 2; i <= sqrt(k); i++) { if (k % i == 0) { int t = 1; while (k % i == 0) { t *= i; k /= i; } prime[++tot] = t; } } if (k) prime[++tot] = k; for (int i = 1; i <= n; i++) { int c; scanf("%d", &c); for (int j = 1; j <= tot; j++) if (c % prime[j] == 0) vis[j] = 1; } for (int i = 1; i <= tot; i++) if (!vis[i]) { printf("No "); return 0; } printf("Yes "); return 0; }
例17:
The GCD table G of size n × n for an array of positive integers a of length n is defined by formula
Let us remind you that the greatest common divisor (GCD) of two positive integers x and y is the greatest integer that is divisor of both xand y, it is denoted as . For example, for array a = {4, 3, 6, 2} of length 4 the GCD table will look as follows:
Given all the numbers of the GCD table G, restore array a.
The first line contains number n (1 ≤ n ≤ 500) — the length of array a. The second line contains n2 space-separated numbers — the elements of the GCD table of G for array a.
All the numbers in the table are positive integers, not exceeding 109. Note that the elements are given in an arbitrary order. It is guaranteed that the set of the input data corresponds to some array a.
In the single line print n positive integers — the elements of array a. If there are multiple possible solutions, you are allowed to print any of them.
4
2 1 2 3 4 3 2 6 1 1 2 2 1 2 3 2
4 3 6 2
1
42
42
2
1 1 1 1
1 1
题意:给出n个数之间任意两个数的gcd,求这n个数分别是多少.
分析:我们要从这个表中得到一些原数列的信息,显然,最大的那个数肯定是原数列中的数,然后把这个数去掉,并且将这个数和之前得到的数列中的数的gcd去掉,因为是一个矩形,所以一定会出现两次gcd,重复这种操作就能得到原数列中的数.
至于实现,最好用map、hash,如果一个一个找数会浪费很多时间.
#include<iostream> #include<cstdio> #include<cstring> #include<queue> #include<cmath> #include<map> using namespace std; map <int, int> m; int a[510 * 510],n,tot,ans[510*510]; bool cmp(int x, int y) { return x > y; } int gcd(int a, int b) { if (!b) return a; return gcd(b, a % b); } int main() { scanf("%d", &n); for (int i = 1; i <= n * n; i++) { scanf("%d", &a[i]); m[a[i]]++; } sort(a + 1, a + n * n + 1,cmp); for (int i = 1; i <= n * n; i++) { if (!m[a[i]]) continue; m[a[i]]--; for (int j = 1; j <= tot; j++) m[gcd(a[i], a[j])] -= 2; ans[++tot] = a[i]; } for (int i = 1; i <= tot; i++) printf("%d ", ans[i]); return 0; }
大BOSS
1876: [SDOI2009]SuperGCD
Time Limit: 4 Sec Memory Limit: 64 MBSubmit: 3744 Solved: 1349
[Submit][Status][Discuss]
Description
Input
Output
一行,表示A和B的最大公约数。
Sample Input
54
Sample Output
HINT
Source
#include<iostream> #include<cstdio> #include<cstring> #include<queue> #include<cmath> #include<map> using namespace std; const int mod = 100000000; int tot; struct node { int x[2010], len; }a,b; void read(node &c) { char s[10010]; scanf("%s", s); int len = strlen(s),cnt = 0,chengji = 1; for (int i = len - 1; i >= 0; i--) { cnt = cnt + (s[i] - '0')* chengji; chengji *= 10; if ((len - i) % 8 == 0) { c.x[++c.len] = cnt; cnt = 0; chengji = 1; } } if (cnt != 0) c.x[++c.len] = cnt; } void div1() { for (int i = a.len; i >= 1; i--) { if (a.x[i] % 2 == 1) a.x[i - 1] += mod; a.x[i] >>= 1; } while (a.x[a.len] == 0 && a.len > 1) a.len--; } void div2() { for (int i = b.len; i >= 1; i--) { if (b.x[i] % 2 == 1) b.x[i - 1] += mod; b.x[i] >>= 1; } while (b.x[b.len] == 0 && b.len > 1) b.len--; } bool check() { if (a.len != b.len) return false; for (int i = 1; i <= a.len; i++) if (a.x[i] != b.x[i]) return false; return true; } bool cmp() { if (a.len > b.len) return true; else if (a.len < b.len) return false; for (int i = a.len; i >= 1; i--) { if (a.x[i] > b.x[i]) return true; else if (a.x[i] < b.x[i]) return false; } return true; } void jian(node &c, node d) { for (int i = 1; i <= c.len; i++) { if (c.x[i] >= d.x[i]) c.x[i] -= d.x[i]; else { c.x[i] = c.x[i] + mod - d.x[i]; c.x[i + 1]--; } } while (c.x[c.len] == 0 && c.len > 1) c.len--; } void mul() { for (int i = 1; i <= a.len; i++) a.x[i] <<= 1; for (int i = 1; i <= a.len; i++) if (a.x[i] >= mod) { a.x[i] -= mod; a.x[i + 1]++; } while (a.x[a.len + 1]) a.len++; } void print() { printf("%d", a.x[a.len]); for (int i = a.len - 1; i >= 1; i--) printf("%08d", a.x[i]); printf(" "); } int main() { read(a); read(b); while (a.x[1] % 2 == 0 && b.x[1] % 2 == 0) { tot++; div1(); div2(); } while (!check()) { if (cmp()) jian(a, b); else jian(b, a); while (a.x[1] % 2 == 0) div1(); while (b.x[1] % 2 == 0) div2(); } while (tot--) mul(); print(); return 0; }
陆陆续续添加了18道题,难度基本上是noip提高组+,推荐阅读进阶博客:传送门,谢谢大家的阅读,如果发现有什么错误,请指出!qq:1339623011,愿不吝赐教!