字符函数
| 函数 | 说明 |
|---|---|
| ascii(x) | 返回x的ascii值 select ascii('a') from dual; -- 97 |
| concat(x,y) | 返回x和y的拼接字符串 select concat('a','b') from dual; -- ab |
| instr(strObj,strSearch[,start[,n]]) | 在strObj中查找strSearch内容,从start位置开始找起,返回第n个结果的索引,start和n默认为1,可以不指定 select instr(‘a1a2a3a4’,‘a’) from dual; -- 1 索引从1开始 select instr(‘a1a2a3a4’,‘a’,2) from dual; -- 从索引2开始找a,结果是3 select instr(‘a1a2a3a4’,‘a’,2,2) from dual; -- 从索引2开始返回第二个结果,索引为5 |
| length(x) | x的长度 select length('abc') from dual; -- 3 |
| lower(x) | x的小写形式 select lower(‘aBcD’) from dual; -- abcd |
| upper(x) | x的大写形式 select upper(‘aBcD’) from dual; -- ABCD |
| ltrim(x[,str]) | 去掉左边的字符串,默认是空格 select length(ltrim(’ abc’)) from dual; -- 3,因为结果是’abc’去掉了左边的空格 select length(ltrim(’***abc’,’*’)) from dual; –- 去掉字符串中的* 结果为3 |
| rtrim(x[,str]) | 类似于ltrim,该函数是去掉右边的字符 |
| trim(x[,str]) | 去掉左右两边的字符 |
| replace(strObj,old,new) | 替换字符中的old为new select replace(‘a1a1a1’,‘1’,‘a’) from dual; -- aaaaaa |
| substr(strObj,star[,length]) | 从strObj中截取字符串,star是开始位置,length可以省略,默认从star位置截取到strObj最后 select substr(‘abcdefg’,2) from dual; -- bcdefg select substr(‘abcdefg’,2,4) from dual; -- bcde |
| regexp_substr(strObj,'[^,]+',star,number) | 从strObj中截取字符串,'[^,]+'是正则表达式,此处表示匹配除了逗号至少出现一次的字符,star是开始位置,number是第几个字段 select regexp_substr('7788,5566,8899','[^,]+',1,1) from dual; -- 7788 select regexp_substr('7788,5566,8899','[^,]+',1,2) from dual; -- 5566 |
数字函数
| 函数 | 说明 |
|---|---|
| sign(x) | 判断x是正数还是负数,正数返回1,负数返回0 select sign(-1) from dual; -- 0select sign(3) from dual; -- 1 |
| abs(x) | 取x的绝对值 select abs(-1) from dual; -- 1 |
| ceil(x) | 大于或等于x的最小值 select ceil(1.1) from dual; -- 2 select ceil(-1.9) from dual; -- -1 |
| floor(x) | 返回小于或等于x的最大值 select floor(1.9) from dual; -- 1 select floor(-1.1) from dual; -- -2 |
| round(x[,y]) | 在y位上四舍五入,y可以省略,默认取值并四舍五入 select round(3.45),round(3.51),round(3.4444,2),round(3.5555,2) from dual; -- 3,4,3.44,3.56 |
| trunc(x[,y]) | 在y位上截断,y省略的话是取整,不会四舍五入,只是简单截断 |
| mod(x,y) | 求x除以y的余数 select mod(5,2) from dual; -- 1 |
日期函数
对日期或时间的处理,sysdate在Oracle中是当前时间的关键字
| 函数 | 说明 |
|---|---|
| add_months(date,n) | 在date参数上增加一个n的月 select sysdate,add_months(sysdate,1) from dual; -- 2021/1/23 16:41:47 , 2021/2/23 16:41:47 |
| last_day(date) | 返回data参数所在月的最后一天的日期 select last_day(sysdate) from dual; -- 2021/1/31 16:47:32 |
| round(date[,fmt]) | 返回四舍五入的日期,fmt默认是’DDD’,月中的某一天,fmt取值可以是’YEAR’,‘MONTH’,‘DDD’,'DAY’ select sysdate,round(sysdate),round(sysdate,'year'),round(sysdate,'month'),round(sysdate,'day') from dual; -- 2021/1/23 16:48:48 , 2021/1/24 , 2021/1/1 , 2021/2/1 , 2021/1/24 |
| months_between(d1,d2) | d1和d2之间的月份差 select months_between(sysdate,add_months(sysdate,2)) from dual; -- -2 |
| next_day(date,'星期一') | 指定日期后的下一个星期一(也可以是星期二等等) select next_day(sysdate,'星期一') from dual; -- 2021/1/25 16:51:39 |
| extract(month from date) | 从指定日期中提取月份 select extract(month from sysdate) from dual; -- 12 month还可以是day,year提取日期和年 |
| trunc(date,fmt) | 截断日期fmt,fmt可以是month/year,相当于只要月或年的信息 select trunc(sysdate,‘month’) from dual; --2021/1/1日期信息没有了,只保留到月,年也类似。 |
转换函数
| 函数 | 说明 |
|---|---|
| to_date(datastr,fmt) | 把字符串形式的日期信息按照fmt格式进行转换 select to_date('2020-12-20 15:33:44','yyyy-mm-dd hh24:mi:ss') from dual; |
| to_char(dataobj,fmt) | 把日期对象显示为fmt指定的日期格式,还可以把数字转换为字符串形式 select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') from dual; |
| to_number(numberStr,fmt) | 把字符形式的数字按照一定的格式转换为数字 select to_number('00123') from dual; -- 123 select to_number('12345.678', '99999.999') from dual; -- 12345.678,参数1和2要对应,参数2可以比参数1位数多,但不能反过来 |
统计函数
在分组的情况下使用
| 函数 | 说明 |
|---|---|
| sum | 求和函数 |
| count | 统计数据数目 |
| avg | 求平均值 |
| max | 求最大值 |
| min | 求最小值 |
nvl和nvl2函数
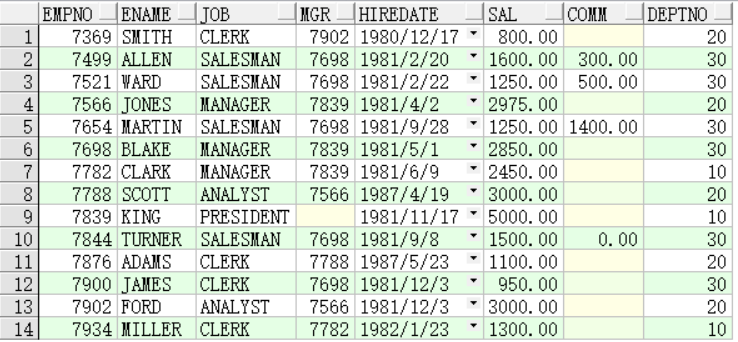
在上表中,如果要加sal+comm列时,comm有的列为null,不能参与运算,会使原有的sal都显示不出来:
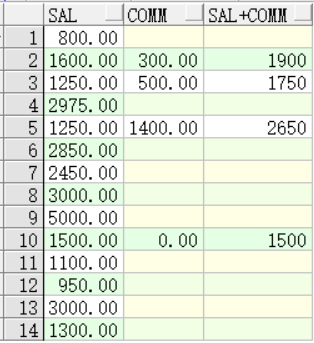
此时可以使用nvl函数,nvl函数可以把一列中值为null的值变成想要的值来进行运算:
SELECT sal,comm,sal+NVL(comm,0) FROM emp;
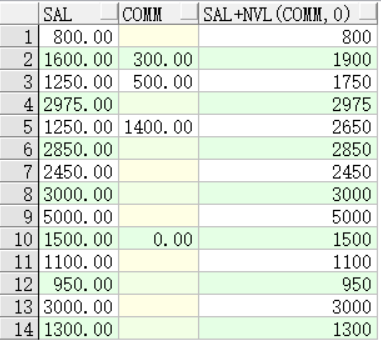
nvl(col,value):当col为null时,返回value的值
nvl2(expr1,expr2,expr3):如果expr1值为null,返回expr3的值,如果expr1值不为null,则返回expr2的值
select nvl2(null,1,0),nvl2('abc',1,0) from dual; -- 0 1
decode函数
decode(条件,值1,返回值1,值2,返回值2,....,值n,返回值n,缺省值):这个函数有switch和if的特征
行转列
decode函数配置统计函数可以实现行转列的效果,下面有表:
| 姓名 | 科目 | 成绩 |
|---|---|---|
| 赵一 | Java | 100 |
| 赵一 | C | 90 |
| 赵一 | C++ | 95 |
| 钱二 | Java | 90 |
| 钱二 | C | 100 |
| 钱二 | C++ | 99 |
想要把这个表中的数据转换为下面的格式:
| 姓名 | Java | C | C++ |
|---|---|---|---|
| 赵一 | 100 | 90 | 95 |
| 钱二 | 90 | 100 | 99 |
首先使用decode函数:
-- ++是特殊字符用2代替了++
SELECT 姓名,
DECODE(科目, 'Java', 成绩) JAVA,
DECODE(科目, 'C', 成绩) C,
DECODE(科目, 'C++', 成绩) C2
FROM 成绩表 GROUP BY 姓名 ;
| 姓名 | Java | C | C2 |
|---|---|---|---|
| 赵一 | 100 | ||
| 赵一 | 90 | ||
| 赵一 | 95 | ||
| 钱二 | 90 | ||
| 钱二 | 100 | ||
| 钱二 | 99 |
使用decode函数后变为上表,解决方法:使用分组和sum函数,将姓名一样的数据合为一条:
SELECT 姓名,
SUM(DECODE(科目, 'Java', 成绩)) JAVA,
SUM(DECODE(科目, 'C', 成绩)) C,
SUM(DECODE(科目, 'C++', 成绩)) C2
FROM 成绩表 GROUP BY 姓名 ;