numpy生成数组的三种方式:
import numpy as np
1、np.arange(24)
2、np.array(range(24))
3、np.array([1,2,3,4])
基础操作:
t1 = np.array([[1,2,3],[4,5,6]]) # 创建一个数组
查看t1的结构: t1.shape # 返回一个tuple元组,(2,3)两行三列的数组
修改t1结构:t1.reshape((3,2)) # 把数组修改为三行两列的数组
查看t1的个数:t1.size # 数组中的数据个数 6
查看t1的维度:t1.ndim # 返回数组的维度,2
查看t1的数据类型:t1.dtype # dtype('int32')
修改t1的数据类型:t1.astype(np.float)
数组的计算(广播原则):
遵循广播原则:

数组与数的加减乘除 :数组中的每个数都要与该数进行相应的加减乘除
eg: t1 + 1
返回为:array([[2, 3, 4],[5, 6, 7]])
数组与数组的加减乘除:
a、与相同形状的数组的加减乘除,每个对应位置依次像加减乘除
t2 = np.arange(6).reshape(2,3)
eg:t1+t2

b、与不相同形状的数组的加减乘除。
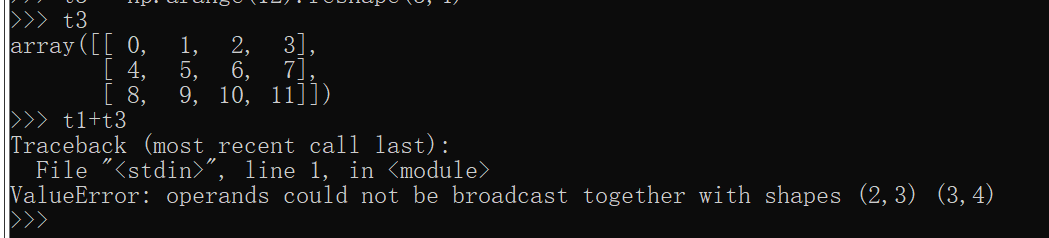
1)对于行列的维度完全不同的不可以进行加减乘除
t3 = np.arange(12).reshape(3,4)
eg: t1 + t3
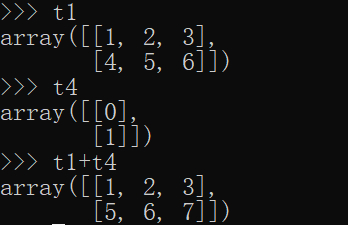
2)两个数组中的行的数值一样,其中的一个数组的列是1的可以进行加减乘除
eg:t4 = np.arange(2).reshape((2,1))
t1 + t4
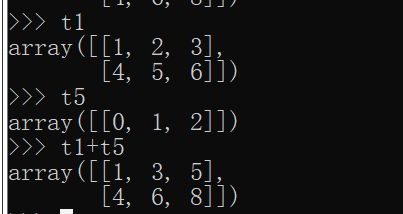
3)两个数组中的列的数值一样,其中的一个数组的行是1的可以进行加减乘除
eg:t5 = np.arange(3).reshape(1,3)
t1+t5
读取数据:

numpy的索引和切片
t1 = np.arange(24).reshape(4,6)
切片:
# 取三行四列的数据 t1[2,3]
# 取三行四行的数据 t1[[2,3],:]
# 取所有行第四列的数据 t1[:,3]
索引
t1[[0,1,2],[0,1,2]] 取得值是(0,0),(1,1),(2,2)
布尔索引:
t1[t1<10]
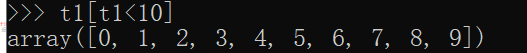
t1[t1!=t1] # 找出该数组中的nan和inf
t1[t1==t1] # 找出数组中的除了nan和inf的数据
numpy的常用方法:
三元运算:np.where(t1<10,0,10) 把<10的替换为0,其他的替换为10
裁剪:t1clip(10,20) 把<10的替换为10,大于20的替换为20
求和:t1.sum(axis=None)
均值:t1.mean(a,axis=None) 受离群点的影响较大
中值:np.median(t1,axis=None)
最大值:t1.max(axis=None)
最小值:t1.min(axis=None)
极值:np.ptp(t1,axis=None) 即最大值和最小值的差
标准差:t1.std(axis=None)
数组拼接:np.hstack((t1,t2)) # 两个数组水平拼接
np.vstack((t1,t2)) # 数组竖直拼接

创建一个全0的数组: np.zeros((3,4))
创建一个全1的数组:np.ones((3,4))
注意:
nan与任何数做运算的结构都是nan
因此我们需要对nan进行替换,消除nan对数据结果的影响
缺失值的用均值替换
import numpy as np
def repalce_nan(t1):
"""
使用平均值替换数组中的nan
:param t1: 传入数组
:return: 返回替换后的数组
"""
for i in range(t1.shape[1]):
now_row = t1[:,i]
nan_count = np.count_nonzero(now_row!=now_row) # 每列数据中的nan的个数now_row!=now_row相当于np.isnan(now_row)
if nan_count != 0: # 当前行有nan
not_have_nan = now_row[now_row==now_row] # 拿取该列不是nan的数,得到一个数组
avg = not_have_nan.mean() # 对该数组计算平均值
now_row[now_row!=now_row] = avg # 把平均值赋值给nan
return t1
if __name__ == '__main__':
t1 = np.arange(24).reshape((4, 6)).astype(np.float)
t1[[2, 3], 4:] = np.nan # 将3,4行,5列之后的数据赋值为nan
t1 = repalce_nan(t1)
print(t1.astype(int))