目前的人工智能做了什么?
语音识别:小米的小爱同学,苹果的siri,微软的Cortana
语音合成:小米的小爱同学,苹果的siri,微软的Cortana
图像识别:交通摄像头拍违章,刷脸解锁手机等
视频识别:抖音内容审核,视频社交APP的审核机制
文字识别:从身份证照片提取身份证号码,扫一扫翻译
语义理解:智能问答机器人,也包含小米的小爱同学,苹果的siri,微软的Cortana
我们身边的人工智能
银行办卡刷脸就行
车辆违章有牌儿就跑不了
违法犯罪路过天眼,等于自投罗网
“小爱同学”,”哎~”,”打开电视”,”好的!”
“欢迎使用10010智能语音系统”,”我还有多少话费”,”您的话费余额为0.01元”
扫一扫翻译看不懂的文字(支持26国语言)
开启人工智能技术的大门 : http://ai.baidu.com/
回到应用列表我们可以看到已创建的应用了

这里面有三个值 AppID , API Key , Secret Key 记住可以从这里面看到 , 在之后的学习中我们会用到
语音合成
安装SDK
首先咱们要 pip install baidu-aip 安装一个百度人工智能开放平台的Python SDK实在是太方便了,这也是为什么我们选择百度人工智能的最大原因
点击左侧的技术文档
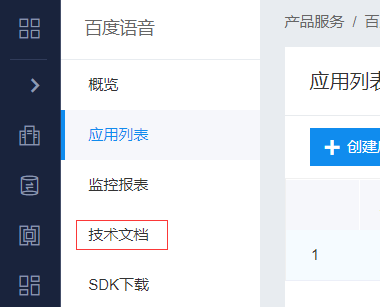
点击左边的语言合成->SDK文档->Python SDK

请严格按照文档里描述的参数进行开发。请注意以下几个问题:
-
合成文本长度必须小于1024字节,如果本文长度较长,可以采用多次请求的方式。切忌文本长度超过限制。
-
语音合成 rest api不限制调用量,但是初始的QPS为100,如果默认配额不能满足您的业务需求,请从控制台中申请提高配额,我们会在两个工作日内完成审批
-
必填字段中,严格按照文档描述中内容填写。
#https://ai.baidu.com/docs#/TTS-Online-Python-SDK/top from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = '16027179' API_KEY = 'eHcOcaZfyw3SwvPmiaUuEU1P' SECRET_KEY = 'GRRkikrCZWqMb6YMeZAkfuUx0Vv2xr3o' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) result = client.synthesis('今天天气怎么样', 'zh', 1, { 'vol': 5,#音量 'per': 4#0为女生 1为男生 3位情感合一 4位度YY }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('tq.wma', 'wb') as f: f.write(result)
语音识别
点击左边的百度语言->语音识别->Python SDK
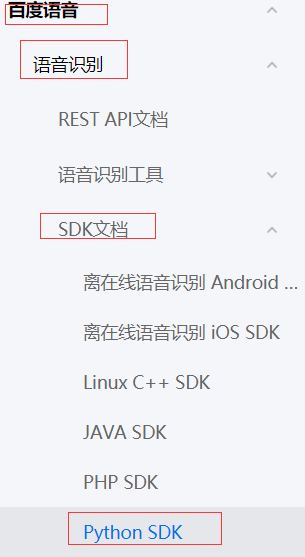
建议使用pcm,因为它比较好实现。而另外2种语言格式,有非常高的要求,只有专业级别的设备才能录制。它才能达到百度的要求。
哎,每次到这里,我都默默无语泪两行,声音这个东西格式太多样化了,如果要想让百度的SDK识别咱们的音频文件,就要想办法转变成百度SDK可以识别的格式PCM
目前已知可以实现自动化转换格式并且屡试不爽的工具 : FFmpeg 这个工具的下载地址是 : 链接:https://pan.baidu.com/s/1jonSAa_TG2XuaJEy3iTmHg 密码:w6hk
命令是 :
ffmpeg -y -i audio.wav -acodec pcm_s16le -f s16le -ac 1 -ar 16000 audio.pcm
目前系统支持的语音时长上限为60s,请不要超过这个长度,否则会返回错误。
#https://ai.baidu.com/docs#/ASR-Online-Python-SDK/top #https://ai.baidu.com/docs#/ASR-Tool-convert/top 工具使用 from aip import AipSpeech import os """ 你的 APPID AK SK """ APP_ID = '16027179' API_KEY = 'eHcOcaZfyw3SwvPmiaUuEU1P' SECRET_KEY = 'GRRkikrCZWqMb6YMeZAkfuUx0Vv2xr3o' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 读取文件 def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() # 识别本地文件 res=client.asr(get_file_content('tq.wma'), 'pcm', 16000, { 'dev_pid': 1537, }) print(res.get("result")[0])
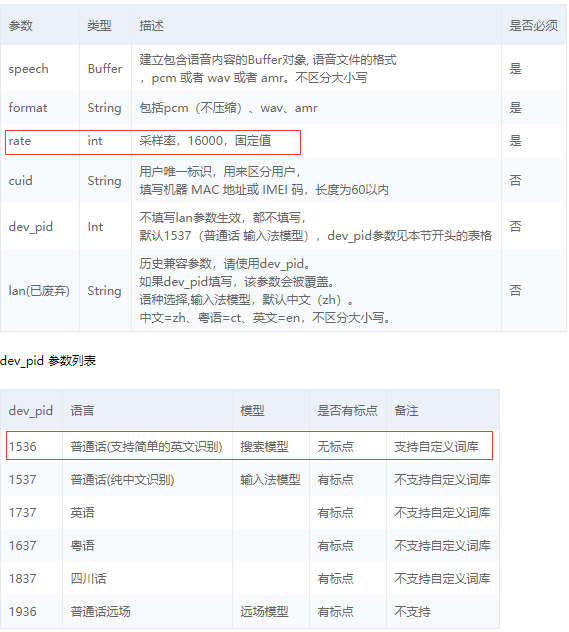
上图的16000表示采样率
1536表示能识别中文和英文,它的容错率比较高
1537必须是标准的普通话,带点地方口音是不行的。
所以建议使用1536
from aip import AipSpeech,AipNlp import os """ 你的 APPID AK SK """ APP_ID = '16027179' API_KEY = 'eHcOcaZfyw3SwvPmiaUuEU1P' SECRET_KEY = 'GRRkikrCZWqMb6YMeZAkfuUx0Vv2xr3o' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) client_nlp = AipNlp(APP_ID, API_KEY, SECRET_KEY) # res=client_nlp.simnet("你叫什么名字","你的名字是什么") # print(res)#对比相识度 https://ai.baidu.com/docs#/NLP-Python-SDK/top # 文件转语音合成 def text2audio(text): result = client.synthesis(text, 'zh', 1, { 'vol': 5, 'per': 4 }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open('auido.mp3', 'wb') as f: f.write(result) return 'auido.mp3' # 读取音频本地文件 def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() ## 识别本地文件 def audio2text(filepath): res = client.asr(get_file_content(filepath), 'pcm', 16000, { 'dev_pid': 1537, }) print(res.get("result")[0]) return res.get("result")[0] def goto_tl(text,uid): URL = "http://openapi.tuling123.com/openapi/api/v2" import requests data = { "perception": { "inputText": { "text": text } }, "userInfo": { "apiKey": "d9a42945a4f546bd90e023ba1ad10a9e", "userId": uid } } data["perception"]["inputText"]["text"] = text data["userInfo"]["userId"] = uid res = requests.post(URL, json=data) # print(res.content) # print(res.text) print(res.json()) return res.json().get("results")[0].get("values").get("text") text = audio2text('tq.wma') #识别 # 自然语言处理 # print(client_nlp.simnet("大爷",text).get("score")) # if client_nlp.simnet("大爷",text).get("score")>=0.5: # filename = text2audio("银角大王八,哈哈哈哈") # # os.system(f"ffplay{filename}") # os.system(filename) answer = goto_tl(text,"123123213")#图灵解析 filename = text2audio(answer)#语音合成 os.system(filename)
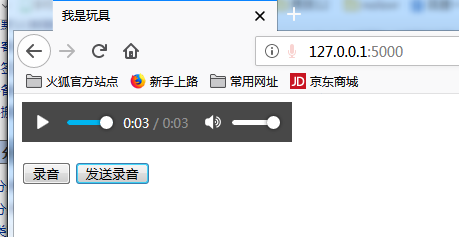
图灵机器人 web录音实现自动交互问答
图灵机器人 是以语义技术为核心驱动力的人工智能公司,致力于“让机器理解世界”,产品服务包括机器人开放平台、机器人OS和场景方案。
官方地址为:
URL = "http://openapi.tuling123.com/openapi/api/v2" import requests data = { "perception": { "inputText": { "text": "北京未来七天,天气怎么样" } }, "userInfo": { "apiKey": "d9a42945a4f546bd90e023ba1ad10a9e", "userId": "123" } } res = requests.post("http://openapi.tuling123.com/openapi/api/v2",json=data) print(res.json())

-----------------FAQ.py
import os from uuid import uuid4 from aip import AipSpeech,AipNlp """ 你的 APPID AK SK """ APP_ID = '16027179' API_KEY = 'eHcOcaZfyw3SwvPmiaUuEU1P' SECRET_KEY = 'GRRkikrCZWqMb6YMeZAkfuUx0Vv2xr3o' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) client_nlp = AipNlp(APP_ID, API_KEY, SECRET_KEY) def text2audio(text): filename = f"{uuid4()}.mp3" result = client.synthesis(text, 'zh', 1, { 'vol': 5, 'per': 4 }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open(filename, 'wb') as f: f.write(result) return filename # 识别本地文件 def audio2text(filepath): res = client.asr(get_file_content(filepath), 'pcm', 16000, { 'dev_pid': 1536, }) print(res) return res.get("result")[0] #读取文件 def get_file_content(filePath): os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() def goto_tl(text,uid): URL = "http://openapi.tuling123.com/openapi/api/v2" import requests data = { "perception": { "inputText": { "text": text } }, "userInfo": { "apiKey": "d9a42945a4f546bd90e023ba1ad10a9e", "userId": "123" } } data["perception"]["inputText"]["text"] = text data["userInfo"]["userId"] = uid res = requests.post(URL, json=data) # print(res.content) # print(res.text) print(res.json()) return res.json().get("results")[0].get("values").get("text")
------------------app.py
import os from flask import Flask,render_template,jsonify,request,send_file from uuid import uuid4 # from flask_cors import CORS from FAQ import audio2text, client_nlp, text2audio, goto_tl app = Flask(__name__) # CORS(app) @app.route("/") def webtoy(): return render_template("index.html") @app.route("/uploader",methods=["POST","GET"])#上传文件 def uploader(): filename = f"{uuid4()}.wav" file = request.files.get("reco") file.save(filename) text = audio2text(filename) # 自然语言处理 LowB if text: answer = goto_tl(text, "qiaoxiaoqiang") filename = text2audio(answer) return jsonify({"code":0,"msg":"文件上传成功","filename":filename}) @app.route("/getaudio/<filename>") def getaudio(filename): return send_file(filename) @app.route("/delaudio/<filename>") def delaudio(filename): os.remove(filename) return None if __name__ == '__main__': app.run("0.0.0.0",5000,debug=True)
------------------index.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>我是玩具</title> </head> <body> <audio controls id="player" autoplay></audio> <p></p> <button onclick="start_reco()">录音</button> <button onclick="stop_reco()">发送录音</button> </body> <script type="text/javascript" src="/static/Recorder.js"></script> <script type="text/javascript" src="/static/jquery-3.3.1.min.js"></script> <script type="text/javascript"> var serv = "http://127.0.0.1:5000"; var reco = null; var audio_context = new AudioContext();//1.音频内容对象 打开麦克风 audio navigator.getUserMedia = (navigator.getUserMedia || //兼容性 navigator.webkitGetUserMedia || navigator.mozGetUserMedia || navigator.msGetUserMedia); //如果getUserMedia执行成功 执行 create_stream navigator.getUserMedia({audio: true}, create_stream, function (err) { console.log(err) }); function create_stream(user_media) { // audio 麦克风和扬声器 //瓢 水 var stream_input = audio_context.createMediaStreamSource(user_media);//2.创建媒体流容器 reco = new Recorder(stream_input); } //开启录音 function start_reco() { reco.record(); } function stop_reco() { reco.stop(); reco.exportWAV(function (wav_file) { console.log(wav_file); // Blob=wav_file 对象 音频 视频图像都在blob中 var formdata = new FormData(); // form 表单 {key:value} formdata.append("reco",wav_file); // form - input type="file" name="reco" formdata.append("username","Alexander.DSB.Li"); // form input type="text / password 编辑框" name="username" value = "Alexander.DSB.Li" $.ajax({ url: serv + "/uploader", type: 'post', processData: false,//不校验 contentType: false, data: formdata, dataType: 'json',//返回值数据格式 success: function (data) { console.log(data); //更改属性 document.getElementById("player").src = serv + "/getaudio/" +data.filename; } }) $.ajax({url:"/delaudio"+filename,success:function(result){ }}); });//异步 reco.clear(); } </script> </html>