Intel 处理器架构演进
刚刚把《硬/软件接口》重新过完了一遍,觉得对微处理器中间的结构有点意犹未尽,真的是很有趣啊,然鹅翻开《量化分析方法》的目录看了看,又吓得我把书扔回去了……内容略多,留着慢慢看吧。
其实 Intel 历年处理器架构演变这事老早我就很好奇了,尤其在 SC17 上今年我们摸过的 Xeon Platinum 8176 那一代 CPU 性能比上代 E5-269x 暴涨了一大截,更是让人好奇这里面有些什么变化。
所以准备来理一理 Intel 处理器架构的演进史。
![]()
Intel Micro-architecture
下面这个表是从维基百科里面扒的:
| Architectural change | Fabrication process | Micro-architecture | Code names | Release date | Processors | ||||
|---|---|---|---|---|---|---|---|---|---|
| 8P/4P Server | 4P/2P Server/ Workstation | Enthusiast/ Workstation | Desktop | Mobile | |||||
| Tick (new fabrication process) | 65 nm | P6, NetBurst | Presle, Cedar Mill, Yonah | 2006-01-05 | Presler | Cedar Mill | Yonah | ||
| Tock (new micro-architecture) | Core | Merom | 2006-07-27 | Tigerton | Woodcrest Clovertown | Kentsfield | Conroe | Merom | |
| Tick | 45 nm | Penryn | 2007-11-11 | Dunnington | Harpertown | Yorkfield | Wolfdale | Penryn | |
| Tock | Nehalem | Nehalem | 2008-11-17 | Beckton | Gainestown | Bloomfield | Lynnfield | Clarksfield | |
| Tick | 32 nm | Westmere | 2010-01-04 | Westmere-EX | Westmere-EP | Gulftown | Clarkdale | Arrandale | |
| Tock | Sandy Bridge | Sandy Bridge | 2011-01-09 | (Skipped) | Sandy Bridge-EP | Sandy Bridge-E | Sandy Bridge | Sandy Bridge-M | |
| Tick | 22 nm | Ivy Bridge | 2012-04-29 | Ivy Bridge-EX | Ivy Bridge-EP | Ivy Bridge-E | Ivy Bridge | Ivy Bridge-M | |
| Tock | Haswell | Haswell | 2013-06-02 | Haswell-EX | Haswell-EP | Haswell-E | Haswell-DT | Haswell-MB (notebooks) Haswell-LP (ultrabooks) |
|
| Refresh | Haswell Refresh, Devil's Canyon | 2014-05-11, 2014-06-02 | |||||||
| Tick | 14 nm | Broadwell | 2014-09-05 | Broadwell-EX | Broadwell-EP | Broadwell-E | |||
| Tock | Skylake | Skylake | 2015-08-05 | Skylake-SP | Skylake-SP | Skylake-X | Skylake | ||
| Optimizations (refreshes) | Kaby Lake | 2017-01-03 | Kabylake-X | Kabylake | |||||
| Kaby Lake R | 2017-08-21 | ||||||||
| Coffee Lake | 2017-10-05 | Coffee Lake | |||||||
| Process | 10 nm | Cannon Lake | 2018 | ||||||
| Architecture | Ice Lake | Ice Lake | 2018/ 2019? | ||||||
| Optimization | Tiger Lake | 2019? | |||||||
| Process | 7 nm | ||||||||
| Architecture | |||||||||
| Optimization | |||||||||
| Process | 5 nm | ||||||||
| Architecture | |||||||||
| Optimization | |||||||||
P6
P6) 是 Intel 的第六代微架构,最早用于 1995 年的 Pentium Pro 处理器,后面 2000 的 NetBurst) 感觉应该也算是包含在 P6 这个大系列里面,一直到 2006 年的 Core) 为止。
这个横跨了将近 10 年的架构系列最早是 600nm 的工艺,一直到最后达到了 65nm,算是不断摸索完善出来的,也是 Intel 走上比较规则的架构发展之路的一个起点。
P6 相对于之前的架构加入了很多新的技术:
- 预测执行(Speculation)和乱序执行!!!
- 14级流水线,第一代奔腾的流水线只有 5 级,P6 的 14 级在当时是最深的
- 片内的 L2 cache!!!
- 物理地址扩展,达到最大36位,理论上这个位宽最大可以支持到 64G 的内存(虽然制程的地址空间还是只能用到 4G)
- 寄存器重命名!!!
- MMX 和 SSE 指令集扩展,开始 SIMD 的思路了
以上这些都是现代处理器中非常重要的设计。
更重要的是从这里开始,奠定了 Intel 沿着摩尔定律发展的 Tick-Tock 架构演进道路:
- Tick 改进制程工艺,微架构基本不做大改,重点在把晶体管的工艺水平往上提升
- Tock 改进微架构设计,保持工艺水平不变,重点在用更复杂、更高级的架构设计
然后就是一代 Tick 再一代 Tock,交替演进。
P6 的末尾阶段,首次出现了双核,当时的双核还是基本上像是把两个单核用胶水粘在一起的感觉。
Core

最早的名字里面带 Core 这个牌子的处理器是 Core Duo,它的架构代号是 Yonah,其实还是算是个 NetBurst 的改版,只是跟后期的 NetBurst 走向了不同的发展道路,虽然名字上有 Core 但不是 Core 架构。主要的设计目标是面向移动平台,因此很多设计都是偏向低功耗,高能效的。
再后来的 Core 2 Duo 才是采用 Core 架构的新一代处理器,全线 65nm,然后微架构在 Yonah 之上做了比较大的改动。
Core 架构把 NetBurst 做深了的流水线级数又砍下来了,主频虽然降下来了(而且即使后来工艺提升到 45nm 之后也没有超过 NetBurst 的水平),但是却提高了整个流水线中的资源利用率,所以性能还是提升了;把奔腾4上曾经用过的超线程也砍掉了;对各个部分进行了强化,双核共享 L2 cache 等等。
从 Core 架构开始是真的走向多核了,就不再是以前“胶水粘的”伪双核了,这时候已经有最高 4 核的处理器设计了。
Nehalem

Core 从 65nm 改到 45nm 之后,基于 45nm 又推出了新一代架构叫 Nehalem,这一代的提升引入了相当多的新技术,算是个非常重要的里程碑。
Core 这个名字变成了桌面 PC 以及笔记本处理器的系列名,后面架构继续更新,然而 Core(酷睿) 这个名字就留下来了,然后系列开始细分,这个架构推出了第一代的 i7。
相对上一代的主要改进:
- 引入了片内 4-12 MB 的 L3 cache!!!
- 重新加入超线程(奔腾4时代有,后来砍掉了,这一代开始重新引入)
- Intel Turbo Boost 1.0!!!
- 分支预测器分级!!!
- 二级的 TLB
- 每个核上有 3 个整数 ALU, 2 个向量 ALU and 2 个 AGU
- 采用 Intel QPI 来代替原来的前端总线!!!
- PCIE 和 DMI 控制器直接做到片内了,不再需要北桥
- IMC(集成内存控制器),内存控制也从北桥移到了片内
- 第二代的 Intel 虚拟化技术
- 流水线加到 20 到 24 级
- 其他指令扩展升级等等
相对上一代的性能:
- 同等功耗下,10-25% 的单线程性能提升,20-100% 的多线程性能提升!!!
- 同等性能下功耗降低 30%
- 15-20% 的 clock-to-clock(不知道这个词应该怎么翻译) 性能提升
工艺提升到 32nm 的 Westmere 后,推出了第一代的 i5 和 i3。
Xeon 系列也从 Westmere 开始推出了第一代 E 命名的 E7-x8xx 系列。
Sandy Bridge
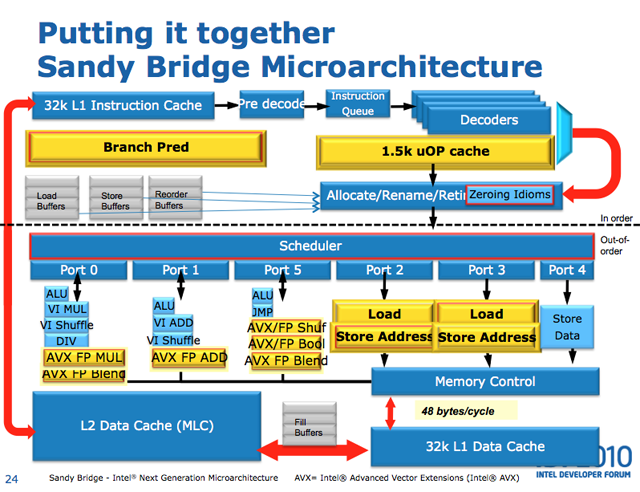
32nm 的下一代 Tock 是 Sandy Bridge,二代 Core i 系列以及第一代 Xeon E3、E5 系列也基于这个架构:
- Intel Turbo Boost 2.0
- 增大了 L1 和 L2 cache
- 共享的 L3 cache 也同时支持片上的核芯显卡
- IMC 强化成了 GMCH(integrated graphics and memory controller),片上显卡共用主存作为它的显存
- 每个核上的运算部件增强
- 分支预测增强
- 微操作译码部分新增了一个 cache(uop cache)
- 14 到 19 级指令流水线!!!(长度区别基于上面那个 uop cache 是否命中)
- 多个核间、核芯显卡、cache 间用了环状总线(ring bus)
- Intel Quick Sync Video,支持视频的硬解码
- 其他指令扩展升级等等
Ring Bus:
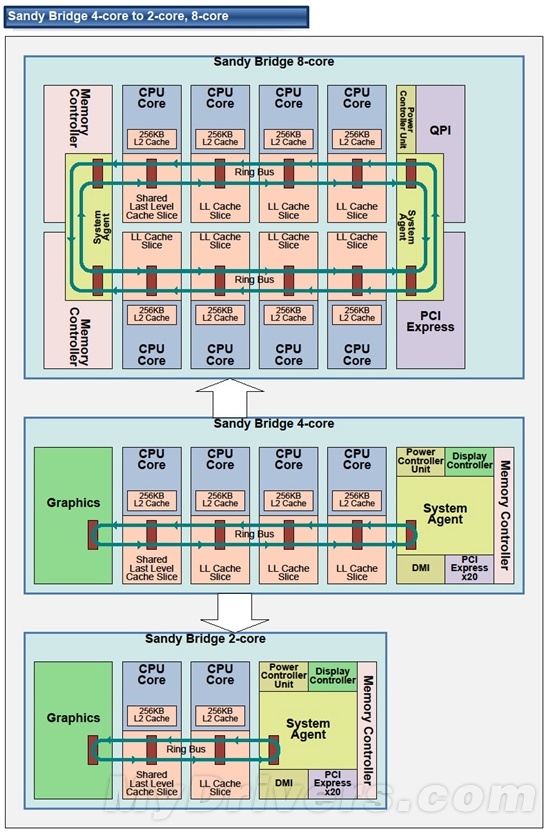
真是令人惊叹的操作啊。
这个故事教育我们,cache 这个思路很多地方都能用到!!!
这个简单的想法能起到的效果可不简单~~
相对上一代的性能:
- 11.3% 的 clock-to-clock 性能提升
- 2 倍的显示性能提升(…这个不用想都知道会很多…)
Tick 到 22nm 的下一代架构叫 Ivy Bridge,三代 Core i 系列和二代 Xeon E 系列:
- 16 位浮点指令
- 片内硬件随机数生成器
- PCIE 3.0
- 其他各个部分都做了很多提升
Haswell

22nm 的 Tock 到了 Haswell,四代 Core i 系列和三代 Xeon E 系列:
- 每个核内的部分进一步升级,更多的 ALU、各种带宽增加等等
- 支持 DDR4 内存
- 提供部分雷电接口(Thunderbolt)支持
- 完整集成电压调节器(FIVR),把主板上的一部分电源控制做到了片内
- 更高级的功耗控制系统,增加了 L6 和 L7 两级 CPU 睡眠状态
- 其他指令扩展升级等等
相对上一代的性能:
- 8% 的向量运算能力提升
- 5% 的单线程性能和 6% 的多线程性能
好像提的不是很多,Intel 开始挤牙膏了
14nm 的 Tick 到了 Broadwell,五代 Core i 系列和四代 Xeon E 系列。各种指令集升级、支持了很多新功能特性。
Skylake
14nm 的 Tock 到了 Skylake,进入 XXlake 时代,六代 Core i 系列。
一系列指令集升级、新功能特性等等。上一代加入的 FIVR 这里又拿掉了,其他包括雷电 3.0 等等好多升级什么的。
从比较粗粒度的架构图来看,Skylake 的架构基本上跟前面那张 Haswell 的没什么差别,大概就是寄存器什么的数字上往上涨了一些,所以图这里就不贴了。
(当然细节上肯定还是有挺多升级的)
挤牙膏啊挤牙膏,疯狂挤牙膏
这个阶段的微架构除了升级指令、加上更多扩展功能以外,不像 Nehalem 和 Sandy Bridge 那时候能有更多革新的设计了,而且由于制程已经达到了很小的程度,再往下可能很快就要碰到工艺极限了,所以摩尔定律开始放缓,性能很难有特别大的提升了。
所以 Intel 开始从 Tick-Tock 两步升级战略转变到 Process-Architecture-Optimization 的三步升级战略,分别是提升工艺制程,升级微架构,然后再在微架构基础上进行优化。
其实这个三步战略从上面 Haswell 时代就已经开始了,Broadwell 前面还有个 refresh 的 Haswell 升级版,i3/i5/i7 4x20 系列。
Skylake 优化版的下一代是 Kaby Lake,即七代 Core i 系列。相比 Skylake 提升了主频,频率切换更快,提升了显示核心等等。
Kaby Lake 继续优化到了 Coffee Lake,八代 Core i 系列。这个系列的 i3 提到了 4 核,i5、i7 都从 6 核开始起步,然后继续提升主频,各种优化等等。
What’s new!
话说 Kaby Lake 和 Coffee Lake 这个时代,Intel 又推出了新的 Core i 系列,命名为 Core i9,第一代的桌面版 Core i9 是 Skylake 架构(Skylake-X),第一代笔记本版 i9 是 Coffee Lake 架构。
那么本该在这个时候推出的第五代 Xeon,也就是 E3/E5/E7 的 xxxx v5 版呢?
Skylake 的第五代 Xeon 摆脱了原本的系列名,而是重新改成了 Bronze、Silver、Gold、Platinum 4 个系列(一股浓浓的网络游戏装备风,说不定再下次改名就可能改名叫稀有、史诗、传说什么的,→_→)。青铜和白银系列支持双路(原本的 E5-24xx、E7-28xx 系列),黄金系列支持四路(原本的 E5-46xx、E7-48xx 系列),白金系列支持八路(原本的 E7-88xx 系列)。
这里还有个重要变动,Intel 沿用了很多年的 Ring Bus 片内总线从 Skylake-X 开始改掉了!前面说 Sandy Bridge 开始,微架构设计上已经全面采用了 Ring Bus,其实最早到 Nehalem 时代的 Xeon 系列就已经开始用上 Ring Bus了,主要用于解决多核(非常非常多的核)之间的共享、扩展等等的问题。
然而随着 CPU 的发展,核越来越多,所以一个 CPU 片内还可能有多个 Ring Bus,就像下面这样。这会有什么问题呢?
以前我们考虑多路服务器里面的 CPU 亲和性的时候,只考虑过 socket 之间的 NUMA 关系,两片 CPU 核之间会有亲和性问题。。。。。。谁想过在下面这种结构的单片 CPU 里面其实也已经是个 NUMA 结构了!!!
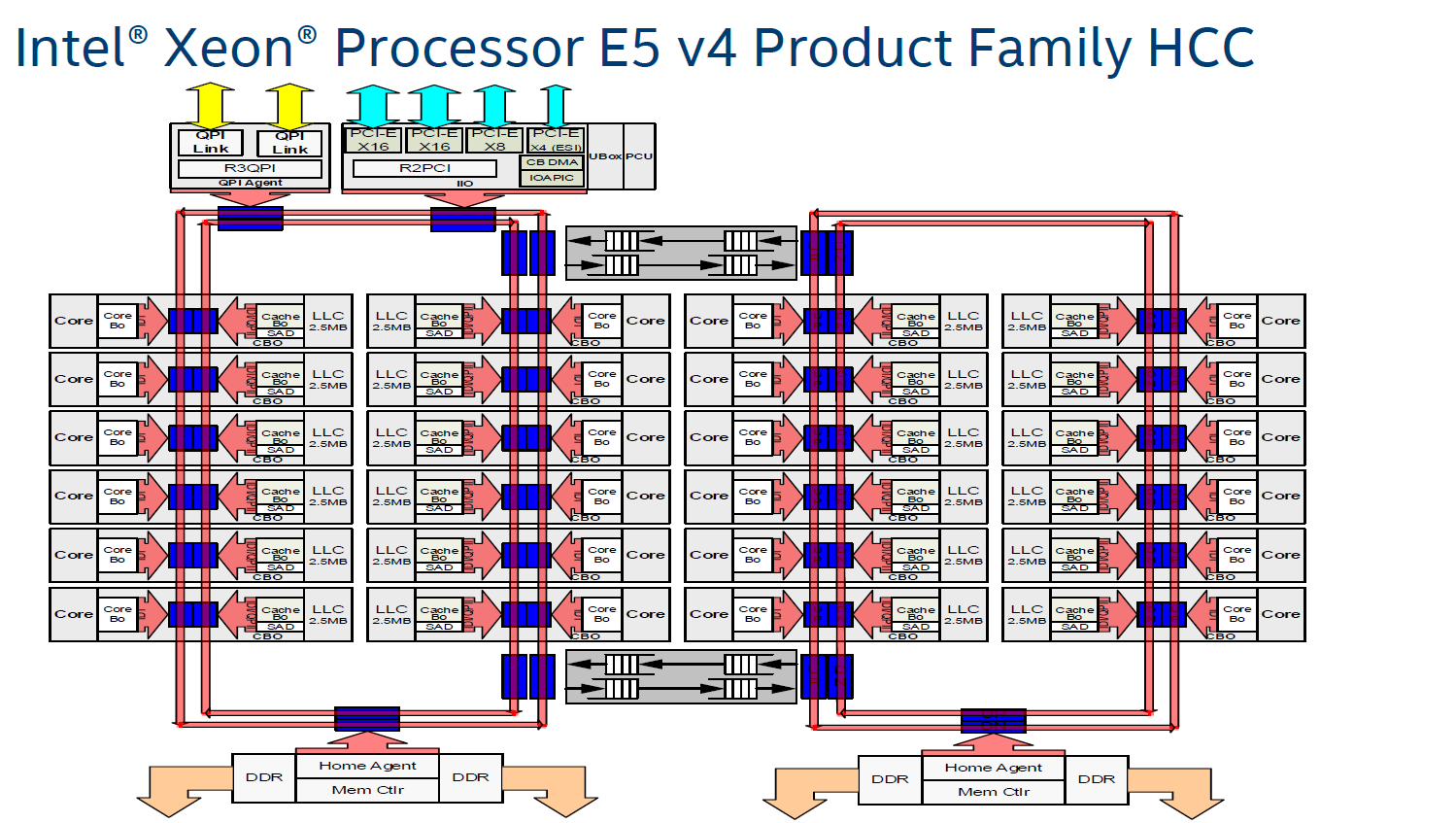
但是当核的数量持续增长,Ring Bus 的延迟也会越来越高,终究不是个办法,Intel 在 KNL 上已经试过 2D Mesh 的总线结构了,大概是效果比较好,于是从 Skylake-X 开始,之后的系列开始全面改用 Mesh 结构。
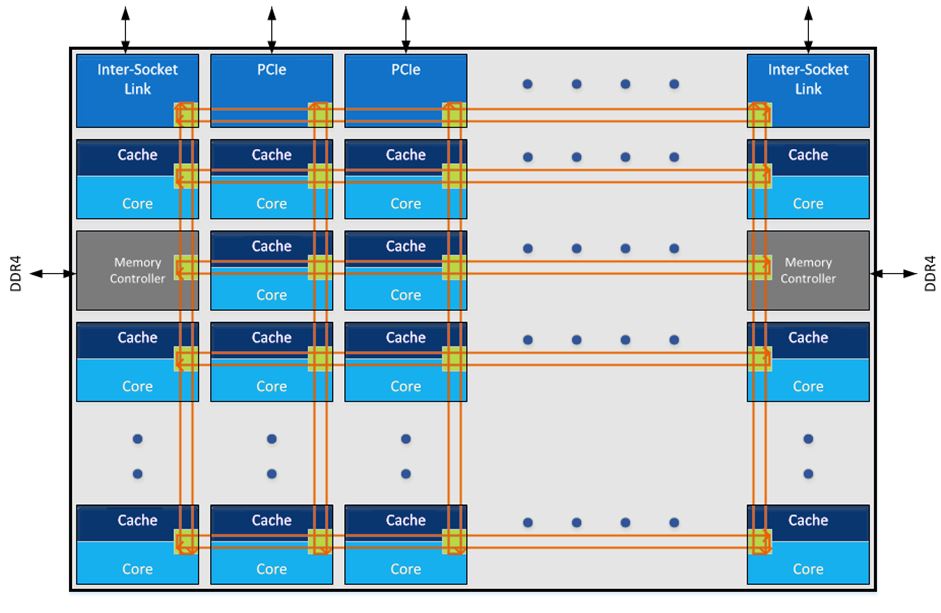
后记
emmm……所以 Platinum 8176 疯狂吊打 E5-269x v4 是妥妥的事情。毕竟微架构差了一代,而且白金版原本对应的是八路的 E7 系列,再加上 Mesh 相比 Ring Bus 解决了很多问题。
然后我就有个疑问了:话说……为啥以前我们不用 E7 呢
更新一下两个资料参考网站: