集成学习与随机森林
假设我们现在提出了一个复杂的问题,并抛给几千个随机的人,然后汇总他们的回答。在很多情况下,我们可以看到这种汇总后的答案会比一个专家的答案要更好。这个称为“群众的智慧”。同理,如果我们汇总一组的预测器(例如分类器与回归器)的预测结果,我们可以经常获取到比最优的单个预测器要更好的预测结果。这一组预测器称为一个集成,所以这种技术称为集成学习,一个集成学习算法称为一个集成方法。
举一个集成方法的例子,我们可以训练一组决策树分类器,每个都在训练集的一组不同的随机子集上进行训练。在做决策时,我们可以获取所有单个决策树的预测结果,然后根据各个结果对每个类别的投票数,最多票的类别获胜。这种集成决策树称为随机森林。尽管它非常简单,不过它是当前最强大的机器学习算法之一。
我们之前在机器学习项目流程里介绍过,我们一般会在接近项目末尾的时候使用集成方法。在我们已经有了几个非常好的预测器之后,要尝试将它们组合,可能会形成一个更好的预测器。实际上,在机器学习比赛中,获胜的解决方案一般都引入了好几个集成方法。
在这章我们会讨论几个最流行的集成方法,包括bagging,boosting,以及stacking。同时我们也会介绍随机森林。
投票分类器
假设我们训练了几个分类器,每个都能达到80%以上的准确率。假设这些分类器可能是逻辑回归分类器、SVM分类器、随机森林分类器、以及KNN分类器等等,如下图所示:
一个非常简单,但是能创建一个更好的分类器的办法是:聚合每个分类器预测的类别,然后选其中投票最多的类别。如下图所示,这种多数投票分类器称为一个硬投票(hard voting)分类器。
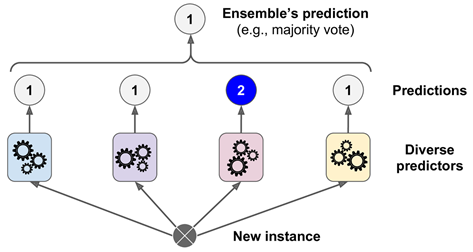
令人出乎意料的是,这种投票分类器经常可以比单个最优分类器的准确度要更高。而且,即使每个分类器都是一个弱学习者(weak learner,也就是说它的预测能力仅比随机猜稍微高一点),集成的结果仍可以是一个强学习者(strong learner,能达到高准确率)。
这个是怎么可能呢?下面我们用一个类比来帮助解释一些原理。假设我们有一个稍微不太公平的硬币,它有51%的几率面朝上,49%的几率面朝下。如果我们抛1000次,我们一般或多或少会得到510次面朝上,490次面朝下,所以“面朝上更多“。如果我们使用数学计算,就会发现,对于“面朝上更多”这个事件,在抛了1000次硬币后,它的概率接近于75%。我们抛的次数越多,这个几率越高(例如,抛10000次,“面朝上更多”这个事件的概率可达97%)。这个可由大数定律解释:只要我们保持抛硬币,面朝上的概率会愈接近它的自然概率(51%)。下图展示的是10组抛硬币(此硬币为前面提到的不公平硬币)的结果。我们可以看到,在抛硬币的次数增加后,面朝上的概率接近51%。最终10组都会接近51%的面朝上结果:
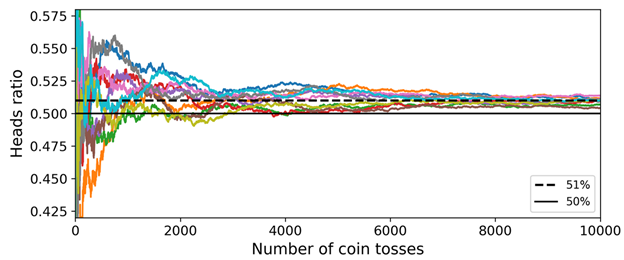
类似,假设我们构造了一个集成,包含1000个分类器,这些分类器每个单独的正确率仅有51%。如果我们使用投票最多的类别作为预测结果,我们可能能获取75%的准确率。这就好比1000个分类器中,“面朝上更多“的概率。不过这个成立的条件在于:所有的分类器都是完全独立的,它们产生的错误也都是不相关的。这种情况很明显在机器学习中不是这么回事,因为它们都是在同一个数据集上进行的训练。它们更有可能产生同样类型的错误,所以也会有很多票投给错误的类别,并最终降低了集成的准确率。
集成学习在预测器互相之间(尽可能地)独立时表现最好。其中一个办法就是使用完全不同的算法训练不同的分类器。这个可以增加它们产生不同类型错误的几率,提升集成的准确度。
下面的代码创建并训练一个投票分类器,由3个不同的分类器组成:
from sklearn.model_selection import train_test_split from sklearn.datasets import make_moons from sklearn.ensemble import RandomForestClassifier from sklearn.ensemble import VotingClassifier from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC # compose moon data X, y = make_moons(n_samples=500, noise=0.30, random_state=42) X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42) log_clf = LogisticRegression() rnd_clf = RandomForestClassifier() svm_clf = SVC() voting_clf = VotingClassifier( estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)], voting='hard' ) voting_clf.fit(X_train, y_train)
我们看一下每个分类器在测试集上的准确率:
from sklearn.metrics import accuracy_score for clf in (log_clf, rnd_clf, svm_clf, voting_clf): clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(clf.__class__.__name__, accuracy_score(y_test, y_pred)) >LogisticRegression 0.864 RandomForestClassifier 0.888 SVC 0.888 VotingClassifier 0.896
可以看到投票分类器性能比单个分类器有稍微一点点提升。
如果所有的分类器都能估计每个类别的概率(例如,它们都有一个predict_proba()方法),我们就可以告诉sk-learn使用软投票(sort voting)。软预测会先获取所有各个分类器对某条数据的预测类别概率,然后计算各个类别概率的平均值,取其中最高的类别概率作为输出的类别。一般软投票会比硬投票的性能更好,因为它会给与那些高度自信的投票更多的权重。在使用时仅需要将voting=”hard” 改为 voting=“soft”即可,同时还要确保所有的分类器都能预测类别的概率。默认情况下SVC是不支持预测类别的概率的,所以我们需要将它的probability超参数设置为True(这样会让SVC类使用交叉验证来估计类别的概率,但是训练速度会下降,并且它会增加一个predict_proba() 方法)。如果我们修改前面的方法,指定投票为软投票(soft voting):
svm_clf = SVC(probability=True) voting_clf = VotingClassifier( estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)], voting='soft' ) for clf in (log_clf, rnd_clf, svm_clf, voting_clf): clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(clf.__class__.__name__, accuracy_score(y_test, y_pred)) >LogisticRegression 0.864 RandomForestClassifier 0.88 SVC 0.888 VotingClassifier 0.912
可以看到准确率提升到了91.2%。
以上便是投票分类器,接下来我们会继续介绍投票分类器里的两种方法:Bagging与 Pasting。