多标签分类
到现在为止,我们看到的模型与数据都是将一条数据分类为一个类别。在某些情况下,我们可能需要分类器为每条数据输出多个类别。例如,假设有一个人脸识别分类器,如果它在同一张图片上认出了多张人脸的话,它应该输出什么呢?显然,它应该为每个它认出的人脸打上一个标志。
假设这个人脸识别分类器已经被训练了可以认出3张脸,小明、小红与小强。当输入一张图片时,假设上面有小明与小强,则分类器应该输出[1, 0, 1]。这种输出多个二进制标识的分类系统称为多标签分类系统(multilabel classification system)。
我们暂时不会深入人脸识别,但是我们可以看一个简单的例子,作为展示:
from sklearn.neighbors import KNeighborsClassifier y_train_large = (y_train >= 7) y_train_odd = (y_train % 2 == 1) y_multilabel = np.c_[y_train_large, y_train_odd] knn_clf = KNeighborsClassifier() knn_clf.fit(X_train, y_multilabel)
这个代码创建一个 y_multilabel 数组,对每条数据,包含两个目标类别:第一个表示的是这个手写数字是不是一个较大的数(7,8,9),第二个类别表示的是它是否是一个奇数。之后我们创建了一个KNeighborsClassifier 实例(KNN支持多标签分类,当然,不是所有的分类器都支持),然后使用多类别的数组进行训练。最后我们使用模型做预测,可以看到它输出了多个类别:
knn_clf.predict([X_train[0]])
>array([[False, True]])
y[0]
>5
可以看到第一条数据是数字5,它分类的结果正确。
我们有多种方法用于评估一个多标签分类器,使用哪个指标完全取决于项目的需求。例如,其中一个方法是对每个单独的label衡量它的F1分数(或者任何其他二元分类器里提到的衡量指标),然后对这些分数就平均。如下所示:
y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_multilabel, cv=3) f1_score(y_multilabel, y_train_knn_pred, average="macro") >0.976410265560605
这个的前提是:假设所有的类别都是同等重要到。但是在实际项目中可能并不是这样的。假设我们的图片数据中,小明的图片比小红与小强的多的多,那么我们可能要给小明的分数更多的权重。一个简单的方法是:给每个类别的权重等同于这个类别的数据量。使用时只需要在上述代码中设置 average="weighted" 即可。
多输出分类
最后要介绍的一种分类任务是多输出分类(multioutput-multiclass classification,有时候也简称multioutput classification)。它其实就是多标签分类的一般形式,并且每个label都可以是多个类别(也就是说,它包含2种以上可能的值)。
举个例子,假设我们现在要构造一个系统,用于移除图片中的噪点。它会输入一张噪点图片,然后输出一张干净的图片,以像素强度的像素点矩阵表示(与MNIST图片表示的方法一样)。需要注意的是,这个分类器输出的是多个label(每个像素点一个类别),并且每个label可以有多个值(像素点的像素强度从0到255)。这就是一个multioutput classification system 的例子。
开始我们可以通过给MNIST图片增加噪点(加到像素点强度中)来创建训练集与测试集,使用NumPy的randint() 方法。而目标图片就是原始图片:
noise = np.random.randint(0, 100, (len(X_train), 784)) X_train_mod = X_train + noise noise = np.random.randintnt(0, 100, (len(X_test), 784)) X_test_mod = X_test + noise y_train_mod = X_train y_test_mod = X_test
我们先看一张测试图:

左边是包含噪点的输入图,右边是干净的目标图。然后我们训练一个分类器用于清理这张图:
knn_clf.fit(X_train_mod, y_train_mod)
clean_digit = knn_clf.predict([X_test_mod[0]])
原图与预测图分别如下所示(左边为预测图),结果看起来还是很令人满意的:
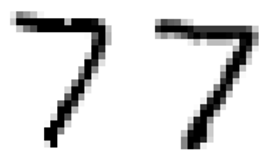
至此,我们已经介绍完了分类问题,希望大家现在已经能够很好地做到以下几点:
- 如何为分类任务选择衡量指标
- 选择合适的precision/recall tradeoff
- 不同分类器之间的对比
- 针对不同的任务构,造表现良好的分类系统