关于数据:
分为结构化数据和非结构化数据:
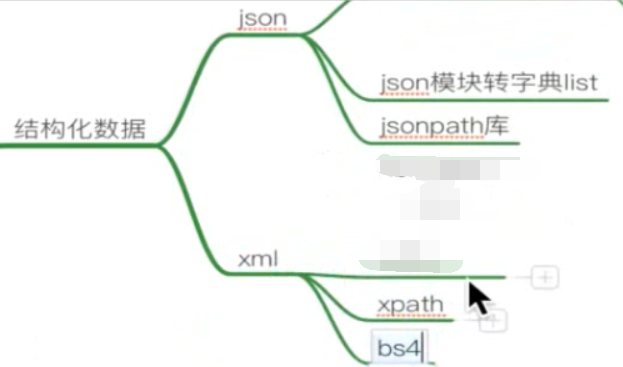

XML 和 HTML 的区别:
前者是用来传输数据的,后者是用来展示数据的。
因为HTML中有单标签,所以不是结构化的数据,而XML则都是单标签,是结构化的数据。
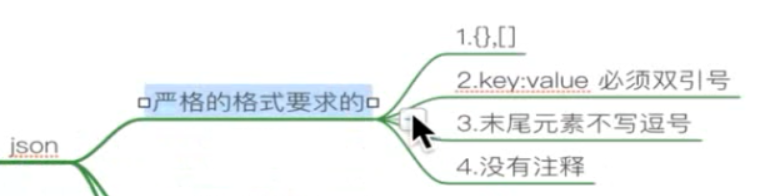
json模块 的使用:


1 import json 2 3 # python 的字典 ---> json 的字符串 4 def test01(): 5 ''' 6 json 数据解析 和字符串相关的都加上s 7 python 的字典 ---> json 的字符串 8 ''' 9 dict_01 = { 10 "name":"tom", 11 "age":18 12 } 13 ret = json.dumps(dict_01) 14 print(ret,type(ret)) #str 15 16 # json 的字符串 ---> python 的字典 17 def test02(): 18 ''' 19 json 数据解析 和字符串相关的都加上s 20 json 的字符串 ---> python 的字典 21 ''' 22 json_str =''' { 23 "name":"tom", 24 "age":"18" 25 }''' #注:json 的key value 必须是双引号 26 ret = json.loads(json_str) 27 print(ret,type(ret)) #dict 28 29 # python 的字典 ---> json 的文件 30 def test03(): 31 ''' 32 json 数据解析 33 python 的字典 ---> json 的文件 34 ''' 35 dict_01 = { 36 "name": "tom", 37 "sex":"男", 38 "age": 18 39 } 40 fp = open("01json.json",'w',encoding="utf8") 41 json.dump(dict_01,fp, ensure_ascii=False ) #ensure_ascii 这时,json 文件中的 中文就能显示了 42 fp.close() 43 44 # json 的文件 ---> python 的字典 45 def test04(): 46 ''' 47 json 数据解析 48 json 的文件 ---> python 的字典 49 ''' 50 fp = open("01json.json",'r') 51 52 dict_01 = json.load(fp) 53 print(dict_01,type(dict_01)) #{'age': 18, 'sex': '男', 'name': 'tom'} <class 'dict'> 54 fp.close() 55 56 57 if __name__ == '__main__': 58 # test01() 59 # test02() 60 # test03() 61 # test04() 62 pass
jsonpath 模块使用:
这是个第三方库,

只需要先记住 跨节点 取元素。 $..key !
1 import jsonpath 2 import json 3 4 def test(): 5 with open("1.json","r",encoding="utf8") as f: 6 json_str = f.read() 7 # print(type(json_str),json_str) 8 9 #使用jsonpath 解析json字符串 10 11 #先将json_str 转为列表 12 data_list = json.loads(json_str) 13 # print(type(data),data) #list ! 14 list_name = jsonpath.jsonpath(data_list,"$..title") #第一个参数 得是Python dict/list 15 list_score = jsonpath.jsonpath(data_list,"$..score") 16 # print(list_name) 17 # print(list_score) 18 19 result = zip(list_name,list_score) 20 print(list(result)) 21 22 #将结果 python的 list 写入到json 文件中! 23 fp = open("2.json","w",encoding="utf8") 24 json.dump(list_name,fp,ensure_ascii=False) #存入电影名字 25 # json.dump(list_score,fp,ensure_ascii=False) #存入豆瓣评分 26 27 28 29 30 if __name__ == '__main__': 31 test()
1 import re 2 3 4 def test(): 5 pattern = re.compile("a(.*?)b") #.* 后面加个问号就是非 贪婪的 6 7 data = ''' 8 ahhhhhb 9 cccc 10 dddb 11 ''' 12 ret_list = pattern.findall(data) 13 print(ret_list) 14 15 pass 16 17 18 19 20 if __name__ == '__main__': 21 test()

用的最多的还是 findall() !!!
1 import re 2 3 4 def test(): 5 #1,正则中的sub 方法 替换 substitude 6 data ="1_2_3_4" 7 pattern = re.compile( "_") 8 ret = pattern.sub('',data) #使用.sub() 来替换字符串 它比字符串的方法.replace() 爽的多。 9 print(ret) 10 11 #使用sub 还可以调换顺序 12 data2 = "hello wolrd ABC d" 13 pattern2= re.compile("(w+) (w+)") 14 ret2 = pattern2.sub(r"2 1",data2) 15 print(ret2) 16 17 #2,正则中的split 方法 分割 18 pattern3 = re.compile("[,;?]") 19 data3 = "Hello w,fdj,fdjask;df;a,?fdsjkf" 20 ret3 = pattern3.split(data3) 21 print(ret3) 22 23 24 #3,汉字 在Unicode 中有个范围! [u4e00 - u9fa5] 25 data4 = "我爱你中国,hahah .tom 我要去看电影,你去吗? " 26 pattern4 = re.compile("[u4e00-u9fa5]+") 27 ret4 = pattern4.findall(data4) 28 print(ret4) 29 30 if __name__ == '__main__': 31 test()
1 import random 2 import requests 3 import re 4 import json 5 6 USER_AGENT = [ 7 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36", 8 # IPhone 9 "Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5", 10 # IPod 11 "Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5", 12 # IPAD 13 "Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5", 14 "Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5", 15 # Android 16 "Mozilla/5.0 (Linux; U; Android 2.2.1; zh-cn; HTC_Wildfire_A3333 Build/FRG83D) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1", 17 "Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1", 18 # QQ浏览器 Android版本 19 "MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1", 20 # Android Opera Mobile 21 "Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10", 22 # Android Pad Moto Xoom 23 "Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13", 24 # BlackBerry 25 "Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+", 26 # WebOS HP Touchpad 27 "Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0", 28 # Nokia N97 29 "Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124", 30 # Windows Phone Mango 31 "Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)", 32 # UC浏览器 33 "UCWEB7.0.2.37/28/999", 34 "NOKIA5700/ UCWEB7.0.2.37/28/999", 35 # UCOpenwave 36 "Openwave/ UCWEB7.0.2.37/28/999", 37 # UC Opera 38 "Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999" 39 ] 40 41 class GuoKr: 42 def __init__(self): 43 self.base_url = "https://www.guokr.com/ask/tag/历史/" 44 self.headers = {"User-Agent":random.choice(USER_AGENT)} 45 pass 46 47 #1,发送请求 48 def send_request(self): 49 response = requests.get(self.base_url,headers = self.headers) 50 return response.content.decode("utf8") 51 52 #2,分析数据 53 def parse_data(self,data): 54 pattern = re.compile('<h2><a target="_blank" href="(.*)">(.*)</a></h2>') 55 return pattern.findall(data) 56 57 #3,保存数据 58 def write_file(self,data): 59 # with open("guoke.html","w",encoding="utf8") as f: 60 # f.write(data) 61 with open("guoke.json","w",encoding="utf8") as f: 62 json.dump(data,f,ensure_ascii=False) 63 64 65 #4,调度 66 def run(self): 67 data = self.send_request() 68 parased_data = self.parse_data(data) 69 self.write_file(parased_data) 70 71 if __name__ == '__main__': 72 GuoKr().run()