简单的多任务demo:


1 import time 2 import threading 3 4 def sing(): 5 for i in range(5): 6 print("------正在唱歌-------") 7 time.sleep(1) 8 9 10 def dance(): 11 for i in range(5): 12 print("------正在跳舞-------") 13 time.sleep(1) 14 15 16 def main(): 17 target1 = threading.Thread(target=sing) 18 target2 = threading.Thread(target=dance) 19 target1.start() 20 target2.start() 21 22 23 if __name__ == '__main__': 24 main() 25 ''' 26 ------正在唱歌------- 27 ------正在跳舞------- 28 ------正在唱歌------- 29 ------正在跳舞------- 30 ------正在跳舞------- 31 ------正在唱歌------- 32 ------正在唱歌------- 33 ------正在跳舞------- 34 ------正在唱歌------- 35 ------正在跳舞------- 36 '''

任务数大于cpu核数是并发!
任务数小于cpu核数是并行!
我们的电脑上基本上属于并发的!
现在所有的多任务基本上都是假的多任务!基本都是并发。而不是并行。
上面的多任务的实现是用threading 模块中的Thread() 类实现的!
查看正在运行的线程数量:
threading 模块中的enumerate()可以返回所有的线程,是个列表。
线程的执行是没有顺序的。
1 import time 2 import threading 3 4 def sing(): 5 for i in range(5): 6 print("------正在唱歌-------") 7 time.sleep(1) 8 9 10 def dance(): 11 for i in range(5): 12 print("------正在跳舞-------") 13 time.sleep(1) 14 15 16 def main(): 17 target1 = threading.Thread(target=sing) 18 target2 = threading.Thread(target=dance) 19 target1.start() 20 target2.start() 21 22 print(threading.enumerate()) # 它是个列表,里面放的是线程对象 23 24 25 26 27 if __name__ == '__main__': 28 main() 29 ''' 30 ------正在唱歌------- 31 ------正在跳舞------- 32 [<_MainThread(MainThread, started 9608)>, <Thread(Thread-2, started 14892)>, <Thread(Thread-1, started 13340)>] 33 ------正在唱歌------- 34 ------正在跳舞------- 35 ------正在唱歌------- 36 ------正在跳舞------- 37 ------正在跳舞------- 38 ------正在唱歌------- 39 ------正在跳舞------- 40 ------正在唱歌------- 41 '''
如果创建Thread的时候执行的函数结束,就是这个线程结束了!
如下来验证上述观点:
1 import time 2 import threading 3 4 def sing(): 5 for i in range(5): 6 print("------正在唱歌-------") 7 time.sleep(1) 8 9 10 def dance(): 11 for i in range(10): 12 print("------正在跳舞-------") 13 time.sleep(1) 14 15 16 def main(): 17 target1 = threading.Thread(target=sing) 18 target2 = threading.Thread(target=dance) 19 target1.start() 20 target2.start() 21 22 while True: 23 time.sleep(1) 24 print(threading.enumerate()) # 它是个列表,里面放的是线程对象 25 26 27 if __name__ == '__main__': 28 main() 29 ''' 30 ------正在唱歌------- 31 ------正在跳舞------- 32 ------正在跳舞------- 33 [<Thread(Thread-1, started 1092)>, <_MainThread(MainThread, started 2780)>, <Thread(Thread-2, started 14820)>] 34 ------正在唱歌------- 35 ------正在唱歌------- 36 ------正在跳舞------- 37 [<Thread(Thread-1, started 1092)>, <_MainThread(MainThread, started 2780)>, <Thread(Thread-2, started 14820)>] 38 ------正在跳舞------- 39 ------正在唱歌------- 40 [<Thread(Thread-1, started 1092)>, <_MainThread(MainThread, started 2780)>, <Thread(Thread-2, started 14820)>] 41 ------正在唱歌------- 42 [<Thread(Thread-1, started 1092)>, <_MainThread(MainThread, started 2780)>, <Thread(Thread-2, started 14820)>] 43 ------正在跳舞------- 44 [<Thread(Thread-1, started 1092)>, <_MainThread(MainThread, started 2780)>, <Thread(Thread-2, started 14820)>] 45 ------正在跳舞------- 46 [<_MainThread(MainThread, started 2780)>, <Thread(Thread-2, started 14820)>] 47 ------正在跳舞------- 48 [<_MainThread(MainThread, started 2780)>, <Thread(Thread-2, started 14820)>] 49 ------正在跳舞------- 50 [<_MainThread(MainThread, started 2780)>, <Thread(Thread-2, started 14820)>] 51 ------正在跳舞------- 52 [<_MainThread(MainThread, started 2780)>, <Thread(Thread-2, started 14820)>] 53 ------正在跳舞------- 54 [<_MainThread(MainThread, started 2780)>, <Thread(Thread-2, started 14820)>] 55 [<_MainThread(MainThread, started 2780)>] 56 [<_MainThread(MainThread, started 2780)>] 57 [<_MainThread(MainThread, started 2780)>] 58 [<_MainThread(MainThread, started 2780)>] 59 '''
我们可以通过threading 中的enumrate() 得到的列表的个数来判断子线程是否执行完毕!
什么时候创建子线程,什么时候运行子线程?
它们都是从start() 开始的,执行到start 的时候创建子线程!并且开始执行子线程。
证明如下:
1 import time 2 import threading 3 4 def sing(): 5 for i in range(5): 6 print("------正在唱歌-------") 7 time.sleep(1) 8 9 def main(): 10 print(threading.enumerate()) 11 target1 = threading.Thread(target=sing) 12 print(threading.enumerate()) 13 target1.start() 14 print(threading.enumerate()) 15 16 if __name__ == '__main__': 17 main() 18 ''' 19 [<_MainThread(MainThread, started 12700)>] 20 [<_MainThread(MainThread, started 12700)>] 21 ------正在唱歌------- 22 [<Thread(Thread-1, started 14500)>, <_MainThread(MainThread, started 12700)>] 23 ------正在唱歌------- 24 ------正在唱歌------- 25 ------正在唱歌------- 26 ------正在唱歌------- 27 '''
调用threading.Thread() 类的时候,只是创建了一个普通的对象。
而thread.start() 是真实创建线程并开始执行。
到此,我们知道了一下几点:
1,线程的执行没有顺序,(可通过sleep 达到我们所期望的要求)
2,线程的创建和执行都是从start() 之后开始的,线程的结束是对应的函数执行完毕,结束子线程!
3,默认主线程会等子线程先执行完毕。
通过继承Thread类完成创建线程:
从上面我们知道,我们可以通过threading.Thread()中的target 可以指定一个函数名,从而实现一个线程的创建(真实创建和执行是start)。
但是,我们现在要创建的线程比较的复杂,不是简单的函数就能完成的,这时我们要通过继承threading.Thread() 这个类,然后我们必须要重写run() 方法
Thread() 类的两种使用方式 :
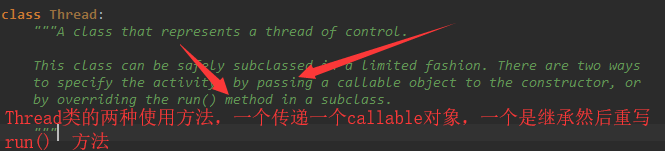
继承 Thread的使用方式:
1 # -*- coding:utf8 -*- 2 #Author: ZCB 3 4 import threading 5 import time 6 7 class MyThread(threading.Thread): 8 def run(self): 9 for i in range(3): 10 time.sleep(1) 11 print("I am "+self.name) 12 13 if __name__ == '__main__': 14 thread1 = MyThread() 15 thread1.start() 16 17 ''' 18 输出: 19 I am Thread-1 20 I am Thread-1 21 I am Thread-1 22 '''
其中的self.name 是线程的名字。
这种适合的是一个线程里面做的事情比较复杂,可以多个函数来做事情。
也许你可能会觉得调用的时候应该用thread1.run() 。
这里我们看官方文档中的内容: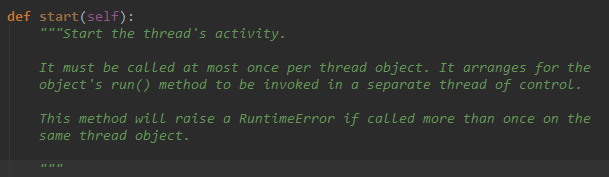
它主要介绍了start() 的用法,它说的是对于每一个线程对象,必须用start() 调用,
start()复杂的调用run() 方法。
而且,如果一个线程对象调用多次start() 会抛出 RuntimeError 异常。
如果用继承方式使用多线程的话,此时的传参要注意:
1 # -*- coding:utf8 -*- 2 #Author: ZCB 3 4 import threading 5 import time 6 7 class MyThread(threading.Thread): 8 def __init__(self,args =None,kwargs=None): 9 super().__init__(args = None,kwargs=None) 10 self.name = kwargs["name"] 11 self.age = kwargs["age"] 12 self.list = args[0] 13 14 def run(self): 15 self.test() 16 17 def test(self): 18 print("Name :{},Age:{}".format(self.name,self.age)) 19 for i in self.list: 20 print(i,end=" ") 21 22 23 if __name__ == '__main__': 24 thread1 = MyThread(args=([1,2,3,4,5],) ,kwargs={"name":"tom","age":18}) 25 thread1.start() 26 for i in range(5,11): 27 print(i ,end=" ") 28 29 ''' 30 输出: 31 Name :tom,Age:18 32 5 6 7 8 9 10 1 2 3 4 5 33 '''
前面第一种多线程的使用中,如果需要传递参数:
1 # -*- coding:utf8 -*- 2 #Author: ZCB 3 4 import threading 5 import time 6 7 def test(ls,dt): 8 for i in ls: 9 print(i,end=" ") 10 print("Name: {} Age: {}".format(dt["name"],dt["age"])) 11 12 def main(): 13 ls = [1,2,3,4,5] 14 dt = {"name":"tom","age":18} 15 a = [1,2,3,4,5] 16 thread1 = threading.Thread(target=test,args=(ls,dt)) 17 thread1.start() 18 19 if __name__ == '__main__': 20 main() 21 print("I am Main_Thread!") 22 for i in range(6,11): 23 print(i)
1 # -*- coding:utf8 -*- 2 #Author: ZCB 3 4 import threading 5 import time 6 7 def test(ls,name,age): 8 for i in ls: 9 print(i,end=" ") 10 print("Name: {} Age: {}".format(name,age)) # 注意,如果是用kwargs 传递字典的话,要用字典的key 做形参 11 12 def main(): 13 ls = [1,2,3,4,5] 14 dt = {"name":"tom","age":18} 15 a = [1,2,3,4,5] 16 thread1 = threading.Thread(target=test,args=(ls,),kwargs=dt) 17 thread1.start() 18 19 if __name__ == '__main__': 20 main() 21 print("I am Main_Thread!") 22 for i in range(6,11): 23 print(i)
总结本质上都是通过args 和kwargs 来传参的。
多线程共享全局变量:
首先,说下如果想要操作全局变量,到底什么时候加global ,什么时候不用加:
1 # -*- coding:utf8 -*- 2 #Author: ZCB 3 4 ############################全局变量相关############################### 5 6 # num = 15 7 # def test(): 8 # global num #此时操作的num 为全局变量 9 # num +=1 10 # test() 11 # print(num) # 此时为16 12 13 14 # num = [1,2,3] 15 # def test(): 16 # num.append(4) #此时操作的num 是全局变量 17 # test() 18 # print(num) #此时为 【1 2 3 4 】 19 20 # num = [1,2,3] 21 # def test(): 22 # num +=[4,5] #此时操作的num 就不是全局变量了 ,不能这样写,会报错 23 # test() 24 # print(num) 25 26 num = [1,2,3] 27 def test(): 28 global num 29 num +=[4,5] #此时操作的num 就不是全局变量了 ,不能这样写,会报错 30 test() 31 print(num) 32 33 #那么问题来了,操作全局变量的时候,到底什么时候加global , 34 #记住,当指针没发生变化的时候,不用加,发生变化必须加 35 36 ############################全局变量相关###############################
下面用程序来验证,多线程是共享全局变量的:
1 # -*- coding:utf8 -*- 2 #Author: ZCB 3 4 import threading 5 import time 6 7 num = 100 8 9 10 def test(): 11 global num 12 num +=1 13 14 def main(): 15 thread1 = threading.Thread(target=test) 16 thread1.start() 17 time.sleep(1) 18 print(num) 19 20 if __name__ == '__main__': 21 main()
输出是 101 ,这说明主线程和创建的子线程是共享全局变量的。
多线程共享全局变量的问题:
资源竞争。
当循环次数为100的时候:
1 # -*- coding:utf8 -*- 2 #Author: ZCB 3 4 import threading 5 import time 6 7 num = 0 8 9 def test01(): 10 global num 11 for i in range(100): 12 num = num +1 13 print("in test01 {}".format(num)) 14 15 def test02(): 16 global num 17 for i in range(100): 18 num = num +1 19 print("in test02 {}".format(num)) 20 21 def main(): 22 thread1 = threading.Thread(target=test01) 23 thread2 = threading.Thread(target=test02) 24 25 thread1.start() 26 thread2.start() 27 28 time.sleep(2) 29 30 print("in main {}".format(num)) 31 32 if __name__ == '__main__': 33 main() 34 ''' 35 输出: 36 in test01 100 37 in test02 200 38 in main 200 39
结果是正常的
次数为一千,一万,十万都是正常的,
但是如果循环次数为一百万的话,此时就要出错了。
1 # -*- coding:utf8 -*- 2 #Author: ZCB 3 4 import threading 5 import time 6 7 num = 0 8 9 def test01(): 10 global num 11 for i in range(1000000): 12 num = num +1 13 print("in test01 {}".format(num)) 14 15 def test02(): 16 global num 17 for i in range(1000000): 18 num = num +1 19 print("in test02 {}".format(num)) 20 21 def main(): 22 thread1 = threading.Thread(target=test01) 23 thread2 = threading.Thread(target=test02) 24 25 thread1.start() 26 thread2.start() 27 28 time.sleep(2) 29 30 print("in main {}".format(num)) 31 32 if __name__ == '__main__': 33 main() 34 ''' 35 输出: 36 in test01 1206988 37 in test02 1191407 38 in main 1191407 39 40 这里的问题是: 41 在执行num =num +1 的时候,cpu 会做很多语句 42 1,获取num 值 43 2,将num 值加1 44 2,将第二步得到的值写回到num 对应的内存中。 45 46 这里可能出现如下情况: 47 假设num = 100时, 48 对于线程1,它可能执行了前两步 但是,它还没将得到的101写回到内存, 49 此时轮到线程2来执行了,它也是执行了前两步,也没把101写回到内存, 50 此时线程1再次执行,将101写回到内存, 51 然后线程2也执行,又将101写回到内存。 52 53 所以,此时两个线程都执行了一遍,但是num 的结构确实101 , 54 而且随着次数的增加,这种可能性出现的概率就越大。 55 '''
在执行num =num +1 的时候,cpu 会做很多语句
1,获取num 值
2,将num 值加1
2,将第二步得到的值写回到num 对应的内存中。
这里可能出现如下情况:
假设num = 100时,
对于线程1,它可能执行了前两步 但是,它还没将得到的101写回到内存,
此时轮到线程2来执行了,它也是执行了前两步,也没把101写回到内存,
此时线程1再次执行,将101写回到内存,
然后线程2也执行,又将101写回到内存。
所以,此时两个线程都执行了一遍,但是num 的结果确是101 ,
而且随着次数的增加,这种可能性出现的概率就越大。
同步概念:
上述出现的问题,如何解决呢?其实,这种多线程的问题在任何的编程语言中都是存在的。它是由于操作系统导致发生的这种情况。
如何解决呢?
其实,对于每个线程来说,它们不能只完成前两步,而没把最终结果写回内存,它应该是要么不做,要么就做完,这称为原子性。
银行的存取款业务肯定也得是这样。不能一个线程取钱2步,另一个也取钱2步,然后,它们两个分别写回内存。就做到取了两份钱,银行却只扣了一份。
同步就是协同步调,按预定的先后次序进行运行。如:你说完,我再说。
如何解决上述的问题呢?
用下面的东西:
互斥锁:



1 # -*- coding:utf8 -*- 2 #Author: ZCB 3 4 import threading 5 import time 6 7 num = 0 8 9 def test01(): 10 metux.acquire() 11 global num 12 for i in range(1000000): 13 num = num +1 14 print("in test01 {}".format(num)) 15 metux.release() 16 17 18 def test02(): 19 metux.acquire() 20 global num 21 for i in range(1000000): 22 num = num +1 23 print("in test02 {}".format(num)) 24 metux.release() 25 26 metux = threading.Lock() 27 28 def main(): 29 thread1 = threading.Thread(target=test01) 30 thread2 = threading.Thread(target=test02) 31 32 thread1.start() 33 thread2.start() 34 35 time.sleep(2) 36 37 print("in main {}".format(num)) 38 39 if __name__ == '__main__': 40 main() 41 ''' 42 in test01 1000000 43 in test02 2000000 44 in main 2000000 45 '''
此时,就已经解决了上述的问题了。
但是,上述的代码不好,上锁锁住的代码太多了,如果第一个锁上之后,它要执行100s ,那么第二个线程就只能等着了。
其实上锁有个原则,锁的代码越少越好。
其实,我们只需对关键的几步上锁就行了。
如下:
1 # -*- coding:utf8 -*- 2 #Author: ZCB 3 4 import threading 5 import time 6 7 num = 0 8 9 def test01(): 10 global num 11 for i in range(1000000): 12 metux.acquire() 13 num = num +1 14 metux.release() 15 16 print("in test01 {}".format(num)) 17 18 19 def test02(): 20 global num 21 for i in range(1000000): 22 metux.acquire() 23 num = num +1 24 metux.release() 25 print("in test02 {}".format(num)) 26 27 metux = threading.Lock() 28 29 def main(): 30 thread1 = threading.Thread(target=test01) 31 thread2 = threading.Thread(target=test02) 32 33 thread1.start() 34 thread2.start() 35 36 time.sleep(2) 37 38 print("in main {}".format(num)) 39 40 if __name__ == '__main__': 41 t1 = time.perf_counter() 42 main() 43 print(time.perf_counter()-t1) 44 ''' 45 in test02 1981093 46 in test01 2000000 47 in main 2000000 48 2.019051503742717 49 '''
此时,最终的结果是不变的。
上面,将锁放到 for 循环外面的用时::2.0241010994337283
上面,将锁放到 for 循环里面的用时::2.019051503742717
死锁:
程序中可能会有多个互斥锁,这时可能就出现问题了。
死锁是一种状态,就是一个线程等待对方释放锁,可是对方却也在等我释放锁。
1 # -*- coding:utf8 -*- 2 #Author: ZCB 3 4 import threading 5 import time 6 7 class MyThread1(threading.Thread): 8 def run(self): 9 # 对mutexA上锁 10 mutexA.acquire() 11 12 # mutexA上锁后,延时1秒,等待另外那个线程 把mutexB上锁 13 print(self.name+'----do1---up----') 14 time.sleep(1) 15 16 # 此时会堵塞,因为这个mutexB已经被另外的线程抢先上锁了 17 mutexB.acquire() 18 print(self.name+'----do1---down----') 19 mutexB.release() 20 21 # 对mutexA解锁 22 mutexA.release() 23 24 class MyThread2(threading.Thread): 25 def run(self): 26 # 对mutexB上锁 27 mutexB.acquire() 28 29 # mutexB上锁后,延时1秒,等待另外那个线程 把mutexA上锁 30 print(self.name+'----do2---up----') 31 time.sleep(1) 32 33 # 此时会堵塞,因为这个mutexA已经被另外的线程抢先上锁了 34 mutexA.acquire() 35 print(self.name+'----do2---down----') 36 mutexA.release() 37 38 # 对mutexB解锁 39 mutexB.release() 40 41 mutexA = threading.Lock() 42 mutexB = threading.Lock() 43 44 if __name__ == '__main__': 45 t1 = MyThread1() 46 t2 = MyThread2() 47 t1.start() 48 t2.start()
1 # -*- coding:utf8 -*- 2 #Author: ZCB 3 4 import threading 5 import time 6 7 def test1(): 8 lock1.acquire() 9 print("in test1") 10 time.sleep(1) 11 lock2.acquire 12 13 14 def test2(): 15 lock2.acquire() 16 print("in test2") 17 time.sleep(1) 18 lock1.acquire() 19 20 lock1 = threading.Lock() 21 lock2 = threading.Lock() 22 def main(): 23 thread1 = threading.Thread(target=test1) 24 thread2 = threading.Thread(target=test2) 25 thread1.start() 26 thread2.start() 27 28 if __name__ == '__main__': 29 main()
如何避免死锁:
有很多方法:
1,程序设计的时候要尽量避免(银行家算法)
2,添加超时时间
3,使用递归锁(当使用多个互斥锁的时候,用递归锁代替)
递归锁的实现的原理是:其实内部就是个计数器。只要是它大于0,其他人就不可能拿到这把锁。
1 # -*- coding:utf8 -*- 2 #Author: ZCB 3 4 import threading 5 import time 6 7 def test1(): 8 r_lock.acquire() #内部计数器为1 9 print("in test1") 10 time.sleep(1) 11 r_lock.acquire() #内部计数器为2 12 13 14 def test2(): 15 r_lock.acquire() 16 print("in test2") 17 time.sleep(1) 18 r_lock.acquire() 19 20 r_lock = threading.RLock() 21 22 def main(): 23 thread1 = threading.Thread(target=test1) 24 thread2 = threading.Thread(target=test2) 25 thread1.start() 26 thread2.start() 27 28 if __name__ == '__main__': 29 main()
所以,如果在一个线程中想使用多个锁的时候,可以尝试使用递归锁!
案例-多线程版udp聊天器:
1 from socket import * 2 import threading 3 4 def recvData(udp_socket): 5 while True: 6 recv_data= udp_socket.recvfrom(1024) 7 print(recv_data[0].decode("utf-8")) 8 9 def sendData(udp_socket,c_addr): 10 while True: 11 send_data = input("to client >>>") 12 udp_socket.sendto(send_data.encode("utf-8"),c_addr) 13 14 15 def main(): 16 udp_socket = socket(AF_INET,SOCK_DGRAM) 17 18 udp_socket.bind(("",9090)) 19 20 dest_ip = input("请输入ip ") 21 dest_port = int(input("请输入 port")) 22 23 c_addr = (dest_ip,dest_port) 24 thread1 = threading.Thread(target=recvData,args=(udp_socket,)) 25 thread2 = threading.Thread(target=sendData,args=(udp_socket,c_addr)) 26 27 thread1.start() 28 thread2.start() 29 30 if __name__ == '__main__': 31 main()
这里主要做的是用两个线程,一个专门管接收数据。一个专门管发送数据!