Large Pose 3D Face Reconstruction from a Single Image via Direct Volumetric CNN Regression
该文献采用一个新型的VRN网络对任意的面部姿势和表情的2D图片进行3D面部重建,并绕过3D可变模型的构造(在训练期间)和拟合(在测试期间)。
volumetric representation
文献中是通过CNN回归来预测3D面部的顶点,直接对所有的3D面部点进行预测的话不利于VRN的学习。该文献中将mesh转换为voxel,变成一个192*192*200的矩阵。这样就比较适合CNN。我们先看看mesh和voxel的区别:下面的第一张图是mesh,可以看出就是一个曲面;第二张是voxel,可以看出人脸是由很多个立方体构成的。
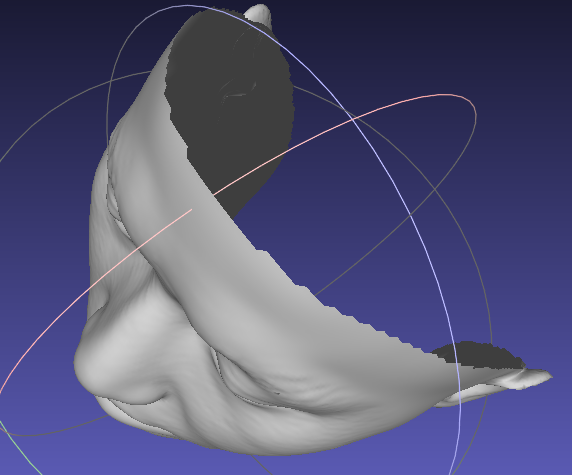

作者给出了voxel转成obj的脚本,运行出来是这样的:

这是一个封闭的曲面。这就有个问题了,由CNN预测出来的3D人脸的顶点是不固定的,也就是我们还需要进行一步对齐,将一个固定顶点的模板对齐到CNN预测出来的3D人脸。 mesh转voxel可以用binvox这个工具。
Volumetric Regression Networks(VRN)
该网络由两个Hourglass Networks构成(HN网络),两个NH的结构类似,第二个NH对第一个NH的输出进行优化。
[...这里有一些插图待处理..]
论文提出了三种方案,第一种是直接从图片重建,第二种是加入了人脸特征点,第三种是多任务(重建+人脸特征点预测)。效果最好的是第二种方法。
Reference:
[1] https://blog.csdn.net/linmingan/article/details/79359218