微服务框架下,一个服务依赖于很多服务。在高并发访问下,系统所依赖的服务的稳定性对系统的影响非常大,依赖有很多不可控的因素,比如网络连接变慢,资源突然繁忙,暂时不可用,服务脱机等,一个被调用服务出问题可能导致调用者不能正常调用其他服务。我们要构建稳定、可靠的分布式系统,就必须要有一套容错方法来应对这些情况。
Hystrix是Netflix开源的一款容错框架,包含常用的容错方法:线程池隔离、信号量隔离、熔断(Circuit Breaker)、降级回退(Fallback),还支持请求缓存(Request Caching)、请求合并(Request Collapsing)等。应用场景如网关服务调用订单服务、商品服务、用户服务。
Hystrix is a latency and fault tolerance library designed to isolate points of access to remote systems, services and 3rd party libraries, stop cascading failure and enable resilience in complex distributed systems where failure is inevitable.
1 基本概念


public class GetOrderCommand extends HystrixCommand<List> { OrderService orderService; public GetOrderCommand(String name){ super(Setter.withGroupKey(HystrixCommandGroupKey.Factory.asKey("ThreadPoolTestGroup")) .andCommandKey(HystrixCommandKey.Factory.asKey("testCommandKey")) .andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey(name)) .andCommandPropertiesDefaults( HystrixCommandProperties.Setter() .withExecutionTimeoutInMilliseconds(5000) ) .andThreadPoolPropertiesDefaults( HystrixThreadPoolProperties.Setter() .withMaxQueueSize(10) //配置队列大小 .withCoreSize(2) // 配置线程池里的线程数 ) ); } @Override protected List run() throws Exception { return orderService.getOrderList(); } public static class UnitTest { @Test public void testGetOrder(){ // new GetOrderCommand("hystrix-order").execute(); Future<List> future =new GetOrderCommand("hystrix-order").queue(); } } }
每个服务对应的commond都有单独的线程池来负责执行。这样当调用者调用多个服务时,某个服务发生异常不会影响调用者对其他服务的调用。
Commond可同步或异步执行:execute()、queue()、observe()、toObservable()
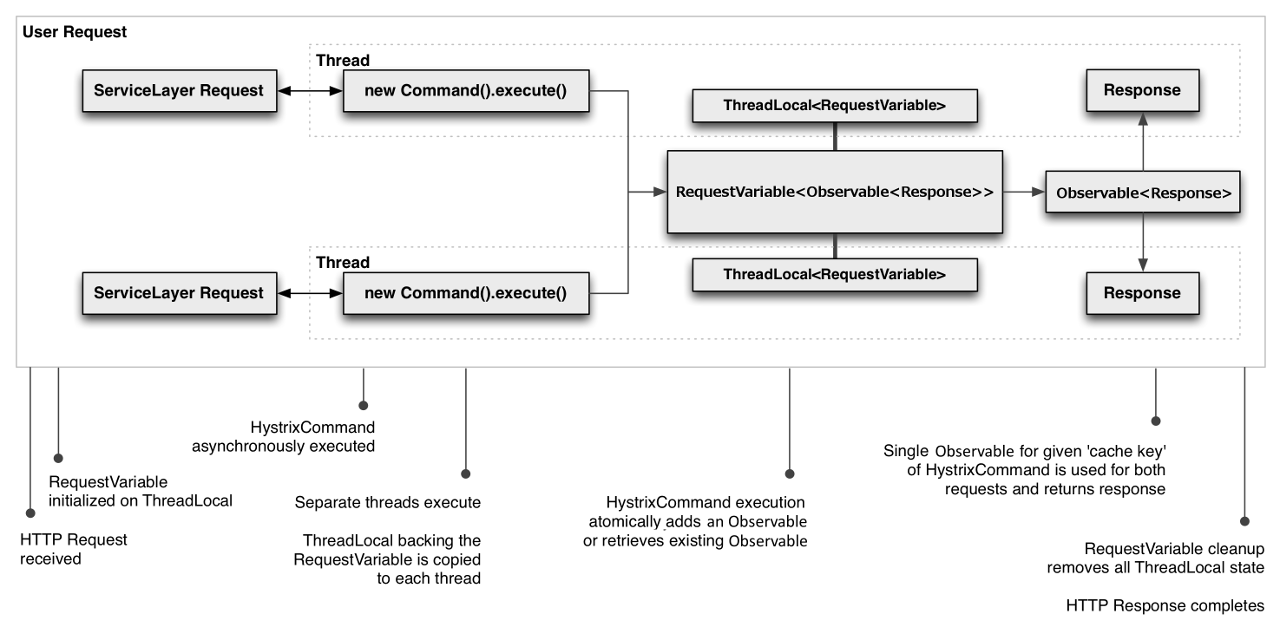
2 内部执行流程
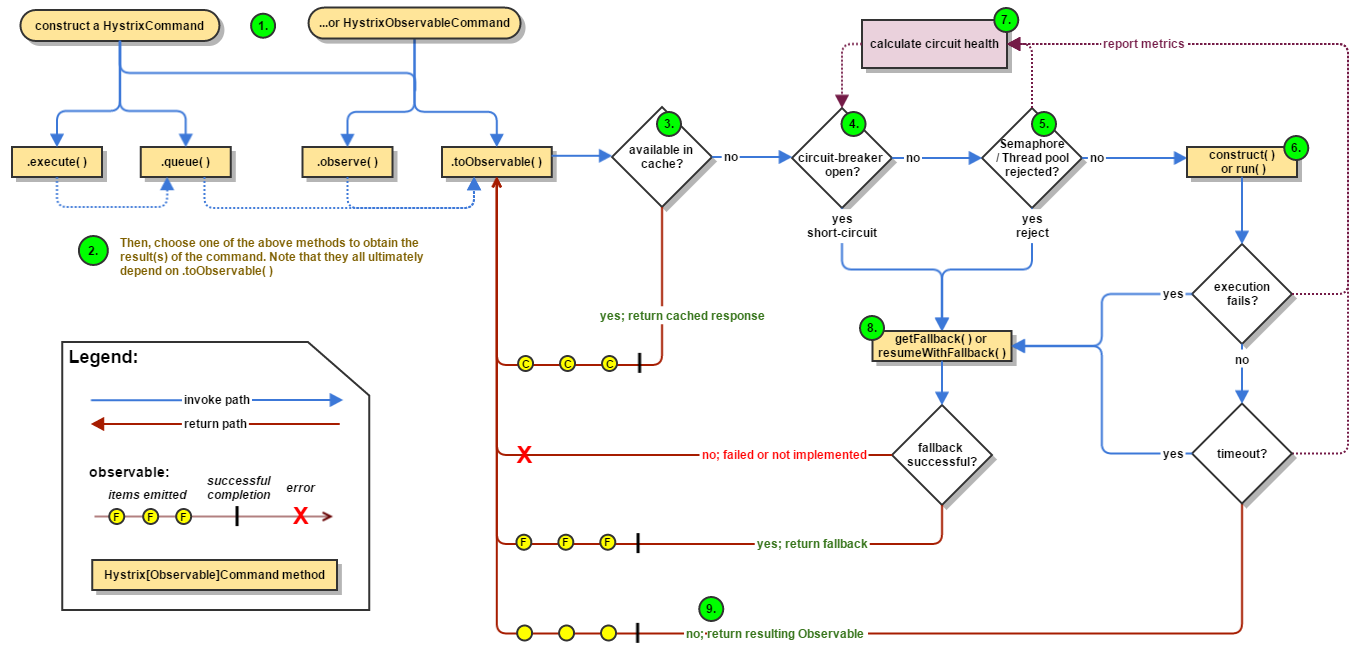
3 容错技术
3.1 依赖隔离(Dependency Isolation)
依赖隔离是指采用某种处理方式使得对一个依赖的调用阻塞时不影响调用方对其他依赖的调用。
显然,最简单的方式是每次调用都起一个新线程执行调用处理,这理论上是可行的,但实际上不会被采用,因为很耗费资源(频繁创建线程、可创建线程数有限等)。解决:仍采用多线程,但需要进一步改造——限制可创建的线程数,有线程池、信号量方式。
3.1.1 线程池隔离
每个依赖的服务的Client(如订单服务的OrderClient)都被包装成HystrixCommand或HystrixObservableCommand。
commond相当于是目标服务的Client的代理,每个服务对应一个commond,每个common内部有个线程池,用来负责执行对目标服务的调用。这样的优点之一是:在调用者方面,一个服务调用阻塞(如超时)时不会影响对其他服务的调用,将影响范围限制在了一个服务内;通过线程池大小控制并发能力。
the isolation provided by thread pools allows for the always-changing and dynamic combination of client libraries and subsystem performance characteristics to be handled gracefully without causing outages.
示意图:
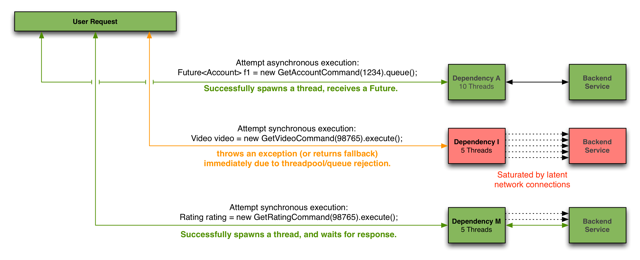
线程池技术本质上与数据库等的连接池类似,一方面用于复用线程/连接以免重复创建线程/连接、另一方面用于限制对服务端的并发访问数。这里的线程池隔离与数据库连接池的区别在于:前者由于要对接多个后端服务而后者专为一个后端服务(数据库),故前者需要为每个服务对应一个线程池而后者只需要一个连接池,两者本质上是一样的。(其实很多技术本质上是一样的,透过现象看本质!)
3.1.2 信号量隔离
此模式使用的场景是被调用的依赖是不耗时的操作时(如从当前进出内存取数据等而非进行RPC)。该模式下每次调用commond时直接用当前线程来执行对目标服务的调用,因此实际上是做不到依赖隔离的——当前服务同时调用多个服务时一个服务的阻塞会影响对其他服务的调用。其主要作用是控制对一个依赖的并发调用个数,所以称counter更贴切。
线程池隔离与信号量隔离的区别:

THREAD— it executes on a separate thread and concurrent requests are limited by the number of threads in the thread-pool。(HystrixCommand推荐用此)SEMAPHORE— it executes on the calling thread and concurrent requests are limited by the semaphore count。(HystrixOvservableCommand推荐用此)
3.2 断路器(Circuit Breaker)
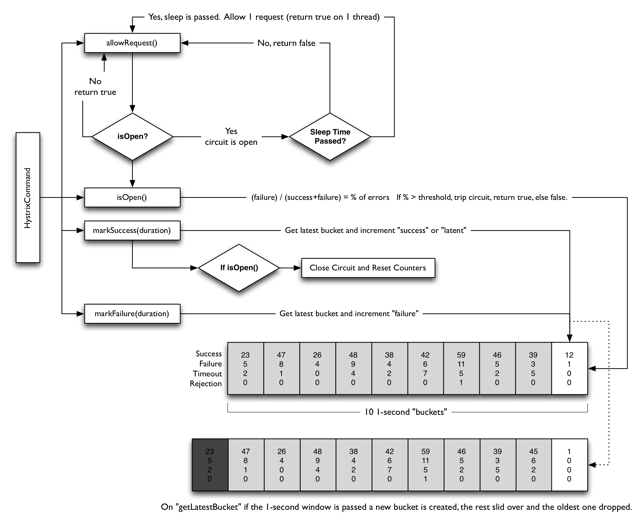
6个核心参数:
1、circuitBreaker.enabled
是否启用熔断器,默认是TURE。
2、circuitBreaker.forceOpen
熔断器强制打开,始终保持打开状态。默认值FLASE。
3、circuitBreaker.forceClosed
熔断器强制关闭,始终保持关闭状态。默认值FLASE。
4、circuitBreaker.errorThresholdPercentage
设定错误百分比,默认值50%,例如一段时间(10s)内有100个请求,其中有55个超时或者异常返回了,那么这段时间内的错误百分比是55%,大于了默认值50%,这种情况下触发熔断器-打开。
5、circuitBreaker.requestVolumeThreshold
默认值20。意思是至少有20个请求才进行errorThresholdPercentage错误百分比计算。比如一段时间(10s)内有19个请求全部失败了。错误百分比是100%,但熔断器不会打开,因为requestVolumeThreshold的值是20.。
6、circuitBreaker.sleepWindowInMilliseconds
半开试探休眠时间,默认值5000ms。当熔断器开启一段时间之后比如5000ms,会尝试放过去一部分流量进行试探,确定依赖服务是否恢复。
3.3 降级回退(Fallback)
即指定在调用目标服务失败时进行怎样的处理,通常是返回个默认值。
3.4 请求合并(Request Collapsing)
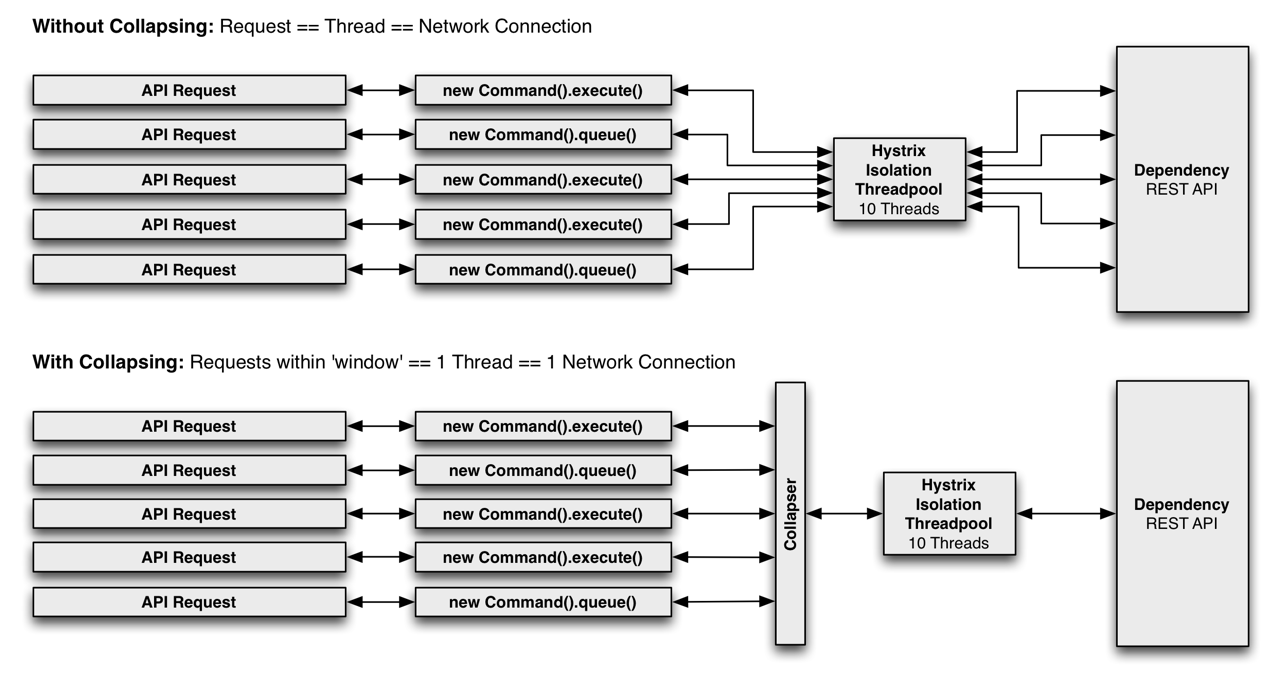
3.5 请求缓存(Request Caching)
4 弊端
牛逼吹了一堆,实际使用时发现的弊端。
关于熔断功能:熔断有connectionTimeout、readTimeout,前者为建立连接过程的超时时间、后者为连接成功后发起请求到收到调用结果的超时时长。启用熔断后,发起服务调用时,若达到了任一个超时时间则调用方会认为服务不可用,然而若达到了readTimeout,实际上可能被调用服务已经在执行,而调用方却认为服务不可用了,这就会造成不同服务间的数据不一致,除非调用方在认为服务不可用时对被调用服务进行回滚(分布式事务等)。因此readTimeout是个很重要的参数,定太短了会导致不同服务上的数据不一致,然而这个参数通常不好定,特别是服务调用链很长时更难以确定该设什么值。