一、Hbase基本原理
1、hbase基本介绍
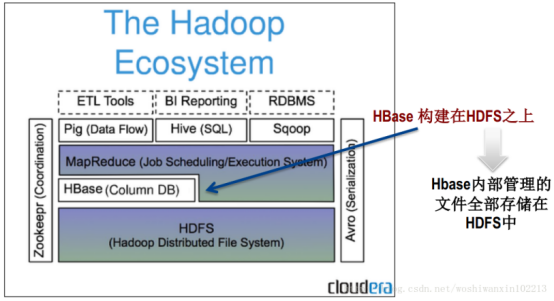
HBASE是一个分布式的,面向列的开源数据库。Hbase的存储是基于hadoop的。因为Hadoop实现了一个分布式文件系统(HDFS),基于hadoop意味着hbase与生俱来的超强的扩展性和吞吐量,hbase采用的是key、value的存储方式。意味着即使随着数据量增大,也几乎不会导致查询的性能下降。
2、hbase存储方式
hbase将数据按列簇分别存储,而并非简单的列式存储;首先了解几个概念:行式存储、列式存储、列簇式存储。
A.行式存储:会将一行数据存储在一起,一行数据写完之后再接着写下一行数据。eg:mysql等关系型数据库;
行式存储在获取一行数据时很高效,但是如果某个查询只需要读取表中指定列对应的数,那么行式存储会先取出一行行的数据,再在每一行数据中截取待查找目标列。因此会导致大量的内存占用
B.列式存储:列式存储理论上会将一列数据存储在一起,不同列的数据分别接种存储。eg:kudu 、 parquet on HDFS;
列式存储查找与行式存储,恰恰相反,对于只查找某些列数据的请求非常高效,但是对于获取一行的请求就比较差;
因为同一列的数据通常都具有相同的数据类型,因此列式存储具有天然的高压缩特性
C.列簇式存储:列簇式存储介于行式存储和列式存储之间;如果一张表只设置一个列簇,这个列簇包含所有的列,hbase中一个列簇的数据是存储在一起的,因此这种设计模式就等同于行式存储;如果一张表的每一列都属于一个唯一的列簇,那么就相当于列式存储。