MapReduce是一种分布式计算模型,主要用于搜索领域,解决海量数据的计算问题
MR由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算。
两个函数的形参是key、value对,表示函数的输入信息
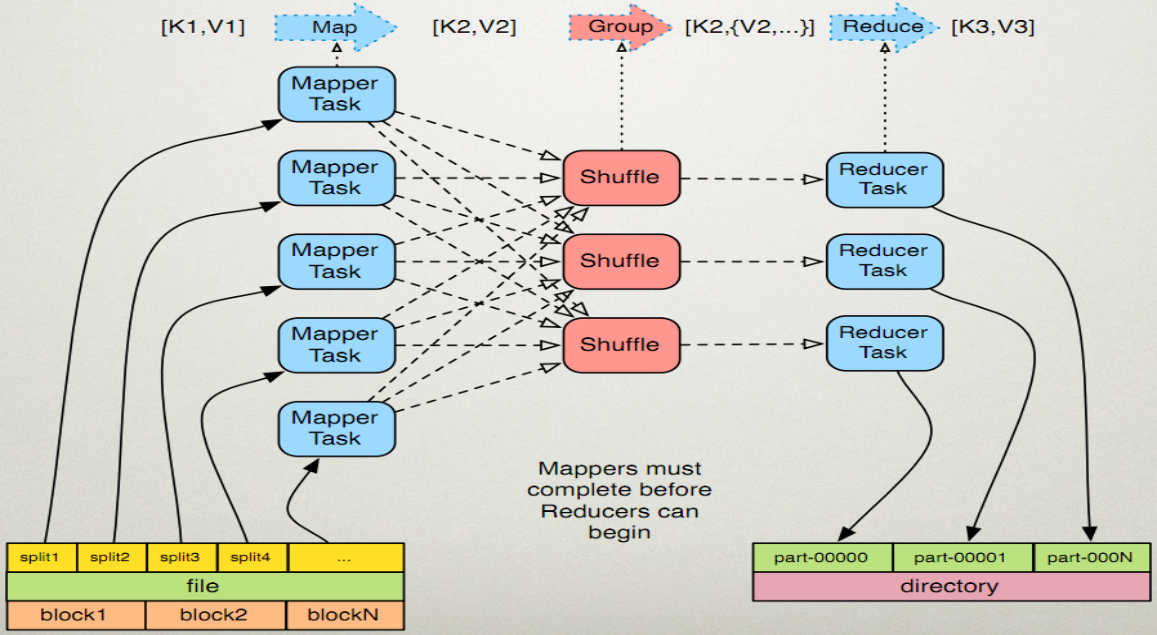
解释:一个文件按照块(每块给定具体值)分为多个split,每个split对应一个mapper,然后通过shuffle进行分组(把相同的key的value合并),最后交给reduce进行最终的合并计算 输出为part-00000名字的文件
Mappers must compiete before Reducers can begin
map必须完成后才可开始reduces工作
每一个步骤都是通过键值对的形式输入输出。
执行步骤:
1.map任务处理
-
读取输入文件内容,解析成key、value对,对输入文件的每一行,解析成key,value对,每一个键值对调用一次map函数
-
写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
-
对输出的key、value进行分区。
-
对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中。
-
(可选)分组后的数据进行归约的
2.reduce任务处理
-
对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。
-
对多个map任务的输出镜像合并、排序,写reduce函数自己的逻辑,对输入的key、value处理。转换成新的key、value输出。
-
把reduce的输出保存到文件中
自我理解:
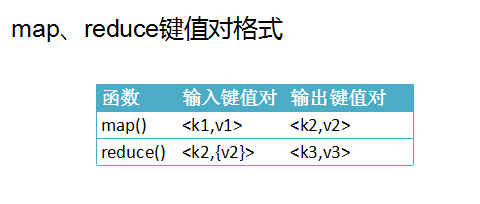
[k1,v1] Map [k2,v2] Group [k2,{v2...}] Reduce [k3,v3]
系统自动按照一行内容分解成多个k1,v1。
在Map过程内根据自己的业务逻辑需求 输出k2,v2
系统自动对k2进行分组计算 输出 k2,{v2...}
在Reduce内根据业务逻辑到处k3,v3
1、Partiton的原理及使用方法(分区)
在MapReduce进行计算时,有时需要把最终输出数据分到不同的文件中,例如:按照省份划分,需要把同一省份的数据放到一个文件中,从而得到多个文件。(得到几个文件,就需要几个Reducer任务运行)也就是说Mapper任务要划分数据,对于不同的数据分配给不同的Reducer任务运行。Mapper任务划分数据的过程就称作Partition,负责实现划分数据的类称作Partitioner。
partition是分割map每个节点的结果,按照key(k2)分别映射给不同的reduce,也是可以自定义的,这里其实可以理解成归类。
原理及作用
hadoop采用的默认的派发方式时根据散列来派发的,但是实际中,这并不能很高效或者按照我们要求的去执行任务。
例:我们想要处理后得到的文件按照一定的规律进行输出,假设有两个reducer,我们想要的最终结果中part-r-00000中存储的是“h”开头的记录的结果,part-r-00001中存储其他开头的结果,这些默认的partitioner是做不到的。
默认分区源码:
1 public class HashPartitioner<K, V> extends Partitioner<K, V> { 2 /** Use {@link Object#hashCode()} to partition. */ 3 public int getPartition(K key, V value, int numReduceTasks) { 4 return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; 5 } 6 }
(1)Partitioner是HashPartitioner的基类,如果需要定制partitioner也需要继承该类。
(2)HashPartitioner是mapreduce的默认partitioner。计算方法是 key.hashCode() & Integer.MAX_VALUE) % numReduceTasks,得到当前的目的reducer。
numReduceTasks由mapred.reduce.tasks配置节点决定的默认是1。
那现在我们虽然不知道(key.hashCode() & Integer.MAX_VALUE)值是多少但是%1我们可以知道结果就是0
使用方法
map的结果,会通过partition分发到Reducer上,哪个可以到哪个Reducer的分配过程,是由Partition规定的、
getPartition(Text key,Text value,int numPartitions)
三个参数分别是k2/v2/reducers的个数
自定义分区的使用方法

2、Combiner的原理及使用方法
每个map可能会产生大量的输出,combiner的作用就是在map端 对输出先做一次合并,以减少传输到reducer的数据量。
如果不用combiner,那么所有的结果都是reduce完成,效率会相对低下,使用combiner,先完成的map会在本地聚合,从而提升速度
注意
combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果,所有Combiner只应该用于那种Reduce的输入key/value对输出key、value类型完全一致,且不影响最终结果的场景。如:求平均值等等,不能光说数据类型一致,有可能值会改变需要特别注意
原理及使用方法
Combiner在map端进行的一个reduce阶段如wordCount程序通过combiners就可以进行预先的聚合

这样到reduce就不会每个节点的每个单词输出以便,减少数据流量并减少代销,由于在wordCount中做combiners是跟reduce一样的,可以直接使用reduce类进行combiners
job.setCombinerClass(ReduerClass.class);
3、shuffle的工作原理

map和reduce本身各是一台机器且也分别是一个步骤
shuffle只是一个工作步骤,横跨map reduce两台机器的工作步骤
map端中的shuffle
首先把一个文件通过hdfs配置文件(默认一块128m)分割成文件块(block),然后进入map,一条一条输出数据,首先输出到缓冲中,(当数据达到缓冲的80%就会溢出到磁盘中),在溢出(spill)时会进行分区(partition)和排序(sort) 合并(merge)然后溢出到磁盘
分区:如果进行分区则会分成3块文件,每块文件就会对应一个reduce
注:物理分区不在缓冲区,而是在磁盘上
最终文件只有一个,所以需要合并(merge),如果有combiner则会进行一次计算
缓冲区默认值100Mb
Reduce端的shuffle
首先将map端产生的输出文件拷贝到Reduce端
然后再次合并给到Reduce计算。输出
4、Hadoop的压缩codec
hadoop中支持的压缩方式有多种,如:Gzip、bzip2、LZO等,其中Gzip是hadoop中内置支持的一种压缩方式,压缩比比较高,压缩速度也不错
MapReduce的输出进行压缩
