一、内置函数补充:
1、数据结构相关(24):
列表和元祖(2):list、tuple
list:将一个可迭代对象转化成列表(如果是字典,默认将key作为列表的元素)。
tuple:将一个可迭代对象转换成元祖(如果是字典,默认将key作为元祖的元素)。


l = list((1,2,3)) print(l) l = list({1,2,3}) print(l) l = list({'k1':1,'k2':2}) print(l) tu = tuple((1,2,3)) print(tu) tu = tuple([1,2,3]) print(tu) tu = tuple({'k1':1,'k2':2}) print(tu)
相关内置函数(2):reversed、slice
***** reversed:将一个序列翻转,并返回此翻转序列的迭代器。
*** slice:构造一个切片对象,用于列表的切片。
ite = reversed(['a',2,3,'c',4,2]) for i in ite: print(i) li = ['a','b','c','d','e','f','g'] sli_obj = slice(3) #按个数切 print(li[sli_obj]) sli_obj = slice(0,7,2) #加步长切 print(li[sli_obj])
字符串相关(9):str、format、bytes、bytearry、memoryview、ord、chr、ascii、repr
str:将数据转换成字符串。
** format:与具体数据相关,用于计算各种小数,精算等。
#字符串可以提供的参数,指定对齐方式,<是左对齐, >是右对齐,^是居中对齐 print(format('test', '<20')) print(format('test', '>20')) print(format('test', '^20')) #整形数值可以提供的参数有 'b' 'c' 'd' 'o' 'x' 'X' 'n' None >>> format(3,'b') #转换成二进制 '11' >>> format(97,'c') #转换unicode成字符 'a' >>> format(11,'d') #转换成10进制 '11' >>> format(11,'o') #转换成8进制 '13' >>> format(11,'x') #转换成16进制 小写字母表示 'b' >>> format(11,'X') #转换成16进制 大写字母表示 'B' >>> format(11,'n') #和d一样 '11' >>> format(11) #默认和d一样 '11' #浮点数可以提供的参数有 'e' 'E' 'f' 'F' 'g' 'G' 'n' '%' None >>> format(314159267,'e') #科学计数法,默认保留6位小数 '3.141593e+08' >>> format(314159267,'0.2e') #科学计数法,指定保留2位小数 '3.14e+08' >>> format(314159267,'0.2E') #科学计数法,指定保留2位小数,采用大写E表示 '3.14E+08' >>> format(314159267,'f') #小数点计数法,默认保留6位小数 '314159267.000000' >>> format(3.14159267000,'f') #小数点计数法,默认保留6位小数 '3.141593' >>> format(3.14159267000,'0.8f') #小数点计数法,指定保留8位小数 '3.14159267' >>> format(3.14159267000,'0.10f') #小数点计数法,指定保留10位小数 '3.1415926700' >>> format(3.14e+1000000,'F') #小数点计数法,无穷大转换成大小字母 'INF' #g的格式化比较特殊,假设p为格式中指定的保留小数位数,先尝试采用科学计数法格式化,得到幂指数exp,如果-4<=exp<p,则采用小数计数法,并保留p-1-exp位小数,否则按小数计数法计数,并按p-1保留小数位数 >>> format(0.00003141566,'.1g') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留0位小数点 '3e-05' >>> format(0.00003141566,'.2g') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留1位小数点 '3.1e-05' >>> format(0.00003141566,'.3g') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留2位小数点 '3.14e-05' >>> format(0.00003141566,'.3G') #p=1,exp=-5 ==》 -4<=exp<p不成立,按科学计数法计数,保留0位小数点,E使用大写 '3.14E-05' >>> format(3.1415926777,'.1g') #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留0位小数点 '3' >>> format(3.1415926777,'.2g') #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留1位小数点 '3.1' >>> format(3.1415926777,'.3g') #p=1,exp=0 ==》 -4<=exp<p成立,按小数计数法计数,保留2位小数点 '3.14' >>> format(0.00003141566,'.1n') #和g相同 '3e-05' >>> format(0.00003141566,'.3n') #和g相同 '3.14e-05' >>> format(0.00003141566) #和g相同 '3.141566e-05'
**** bytes:用于不同编码之间的转化。
s = '你好' bs = s.encode('utf-8') print(bs) s1 = bs.decode('utf-8') print(s1) b1 = bytes(s,encoding='utf-8') print(b1) s2 = b1.decode('utf-8') print(s2) b2 = '你好'.encode('gbk') b3 = b2.decode('gbk') print(b3.encode('utf-8'))
bytearry:返回一个新字节数组。这个数组里的元素是可变的,并且每个元素的值范围:0 <= x < 256
ret = bytearray('alex',encoding='utf-8') print(id(ret)) print(ret) print(ret[0]) ret[0] = 65 print(ret) print(id(ret))
memoryview:
ret = memoryview(bytes('你好',encoding='utf-8')) print(len(ret)) print(ret) print(bytes(ret[:3]).decode('utf-8')) #你 print(bytes(ret[3:]).decode('utf-8')) #好
** ord:输入字符找该字符编码的位置
** chr:输入位置数字找出其对应的字符
** ascii:是ascii码中的返回该值,不是就返回 /u 它在unicode的位置(16进制)
# ord 输入字符找该字符编码的位置 print(ord('a')) print(ord('中')) # chr 输入位置数字找出其对应的字符 print(chr(97)) print(chr(20013)) # 是ascii码中的返回该值,不是就返回/u... print(ascii('a')) print(ascii('中'))
***** repr:返回一个对象的string形式(原形毕露)。
# %r 原封不动的写出来 # name = 'taibai' # print('我叫%r'%name) print("我叫'%s'" % name) #用双引号把单引号引起来也可以 # repr 原形毕露 print(repr('{"name":"alex"}')) print('{"name":"alex"}')
数据集合(3):
dict:创建一个字典。
set:创建一个集合。
frozenset:返回一个冻结的集合,冻结后集合不能再添加或删除任何元素。
相关内置函数(8):
len:返回一个对象中元素的个数。
***** sorted:对所有课迭代的对象进行排序操作。
l = [('a',1),('c',3),('d',4),('b',2)] l1 = sorted(l,key=lambda x: x[1]) # 利用key print(l1) # 结果:[('a', 1), ('b', 2), ('c', 3), ('d', 4)] students = [('john','A',15),('jane','B',12),('dave','B',10)] l2 = sorted(students,key=lambda s: s[2]) # 按年龄排序 print(l2) # 结果:[('dave', 'B', 10), ('jane', 'B', 12), ('john', 'A', 15)] l3 = sorted(students,key=lambda s: s[2], reverse=True) # 按降序 print(l3) # 结果:[('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
enumerate:枚举,返回一个枚举对象。
print(enumerate([1,2,3,4])) for i in enumerate([1,2,3,4,5]): # (索引 + 值) print(i) for i in enumerate([1,2,3],100): #(索引从100开始 + 值) print(i)
*** all:可迭代对象中,全都是True才是Ture
*** any:可迭代对象中,有一个True就是True
# all 可迭代对象中,全都是True才是True # any 可迭代对象中,有一个True 就是True # print(all([1,2,True,0])) # print(any([1,'',0]))
***** zip:函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元祖,然后返回由这些元祖组成的列表。如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同。
拉链方法:将多个iter纵向组成一个个元祖。
l1 = [1,2,3,4] l2 = ['a','b','c',5] l3 = ('*','**',(1,2,3,4)) print(zip(l1,l2,l3)) for i in zip(l1,l2,l3): print(i) # 结果: # <zip object at 0x00A86558> # (1, 'a', '*') # (2, 'b', '**') # (3, 'c', (1, 2, 3, 4))
***** filter:过滤。
#filter 过滤 通过你的函数,过滤一个可迭代对象,返回的是True #类似于[i for i in range(10) if i > 3] # def func(x):return x%2 == 0 # ret = filter(func,[1,2,3,4,5,6,7]) # print(ret) # for i in ret: # print(i) # print(list(filter(func,[1,2,3,4,5,6,7])))
***** map:会根据提供的函数对指定序列做映射。
>>>def square(x) : # 计算平方数 ... return x ** 2 ... >>> map(square, [1,2,3,4,5]) # 计算列表各个元素的平方 [1, 4, 9, 16, 25] >>> map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # 使用 lambda 匿名函数 [1, 4, 9, 16, 25] # 提供了两个列表,对相同位置的列表数据进行相加 >>> map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10]) [3, 7, 11, 15, 19]
二、匿名函数:
为了解决那些功能很简单的需求而设计的 一句话 函数。
匿名函数的调用和正常的调用一样,函数名(参数)就可以了
#这段代码 def calc(n): return n**n print(calc(10)) #换成匿名函数 calc = lambda n:n**n print(calc(10))
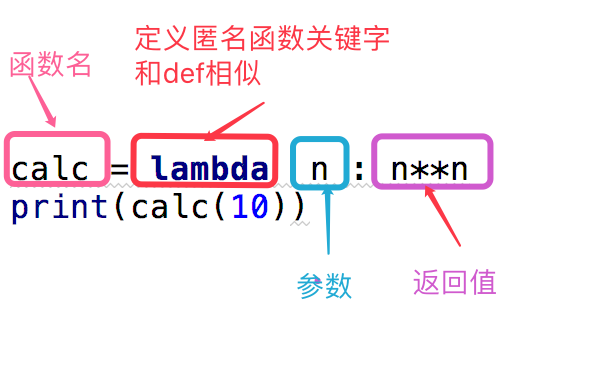
函数名 = lambda 参数 :返回值 #参数可以有多个,用逗号隔开 #匿名函数不管逻辑多复杂,只能写一行,且逻辑执行结束后的内容就是返回值 #返回值和正常的函数一样可以是任意数据类型
l=[3,2,100,999,213,1111,31121,333] print(max(l)) dic={'k1':10,'k2':100,'k3':30} print(max(dic)) print(dic[max(dic,key=lambda k:dic[k])]) res = map(lambda x:x**2,[1,5,7,4,8]) for i in res: print(i) res = filter(lambda x:x>10,[5,8,11,9,15]) for i in res: print(i)
三、递归初识:
递归就是在函数中调用函数自己,递归的最大深度是998层。
每一次函数调用都会产生一个属于它自己的名称空间,如果一直调用下去,就会造成名称空间占用太多内存的问题,于是python为了杜绝此类现象,强制的将递归层数控制在了997
def foo(n): print(n) n += 1 foo(n) foo(1)
997是python为了我们程序的内存优化所设定的一个默认值,我们当然还可以通过一些手段去修改它:
(至于实际可以达到的深度就取决于计算机的性能了)
import sys sys.setrecursionlimit(100000) # 把默认值改成10W def func(x): print(x) x += 1 func(x) func(1)
''' alex 比 wusir 大两岁 n = 4 wusir 比日天 大两岁 n = 3 日天 比太白 大两岁 n = 2 太白 24岁 n = 1 age(4) = age(3) + 2 age(3) = age(2) + 2 age(2) = age(1) + 2 age(1) = 24 ''' def age(n): if n == 1: return 24 else: return age(n-1)+2 print(age(4))