现代的互联网分布式系统,只要稍微大一些,就一定逃不开3类中间件:远程调用(RPC)框架、消息队列、数据库访问中间件。Kafka 是消息队列中间件的代表产品,用 Scala 语言实现;
基本概念
首先,Kafka 中有一些基本的概念需要熟悉。
- Topic,指消息的类别,每个消息都必须有;
- Producer,指消息的产生者,或者,消息的写端;
- Consumer,指消息的消费者,或者,消息的读端;
- Producer Group,指产生者组,组内的生产者产生同一类消息;
- Consumer Group,指消费者组,组内的消费者消费同一类消息;
- Broker,指消息服务器,Producer 产生的消息都是写到这里,Consumer 读消息也是从这里读;
- Zookeeper,是 Kafka 的注册中心,Broker 和 Consumer 之间的协调器,包含状态信息、配置信息和一些 Topic 的信息;
- Partition,指消息的水平分区,一个 Topic 可以有多个分区;
- Replica,指消息的副本,为了提高可用性,将消息副本保存在其他 Broker 上。
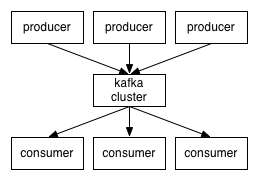
特别说明,Broker 是指单个消息服务进程,一般情况下,Kafka 是集群运行的,Broker 只是集群中的一个服务进程,而非代指整个 Kafka 服务,可以简单将 Broker 理解成服务器(Server)。Kafka 引入的术语都比较常见,从字面上理解相对直观。Kafka 的大致结构图是这样:
(Kafka 是 Pull 模式的消息队列,即 Consumer 连到消息队列服务上,主动请求新消息,如果要做到实时性,需要采用长轮询,Kafka 在0.8的时候已经支持长轮询模式。上图中 Consumer 的连接箭头方向可能会让读者误以为是 Push 模式,特此注明)
关于顺序和分区
Kafka 是一个力求保持消息顺序性的消息队列,但不是完全保证,其保证的是 Partition 级别的顺序性,如下图:

此图是 Topic 的分区 log 的示意图,可见,每个分区上的 log 都是一个有序的队列,所以,Kafka 是分区级别有序的。如果,某个 Topic 只有一个分区,那么这个 Topic 下的消息就都是有序的。
分区是为了提升消息处理的吞吐率而产生的,将一个 Topic 中的消息分成几份,分别给不同的 Broker 处理。如下图:

此图中有2个 Broker,Server 1 和 Server 2,每个 Broker 上有2个分区,总共4个分区,P0 ~ P3;有2个 Consumer Group,Consumer Group A 有2个 Consumer,Consumer Group B 有4个 Consumer。Kafka 的实现是,在稳定的情况下,维持固定的连接,每个 Consumer 稳定的消费其中某几个分区的消息,以上图举例,Consumer Group A 中的 C1 稳定消费 P0、P3,C2 稳定消费 P1、P2。这样的连接分配可能会导致消息消费的不均匀分布,但好处是比较容易保证顺序性。
维持完全的顺序性在分布式系统看来几乎是无意义的。因为,如果需要维持顺序性,那么就只能有一条线程阻塞的处理顺序消息,即,Producer -> MQ -> Consumer 必须线程上一一对应。这与分布式系统的初衷是相违背的。但是局部的有序性,是可以维持的。比如,有30000条消息,每3条之间有关联,1->2->3,4->5->6,……,但是全局范围来看,并不需要保证 1->4->7,可以 7->4->1 的顺序来执行,这样可以达到最大并行度10000,而这通常是现实中我们面对的情况。通常应用中,将有先后关系的消息发送到相同的分区上,即可解决大部分问题。
关于副本
副本是高可用 Kafka 集群的实现方式。假设集群中有3个 Broker,那么可以指定3个副本,这3个副本是对等的,对于某个 Topic 的分区来说,其中一个是 Leader,即主节点,另外2个副本是 Follower,即从节点,每个副本在一个 Broker 上。当 Leader 收到消息的时候,会将消息写一份到副本中,通常情况,只有 Leader 处于工作状态。在 Leader 发生故障宕机的时候,Follwer 会取代 Leader 继续传送消息,而不会发生消息丢失。Kafka 的副本是以分区为单位的,也就是说,即使是同一个 Topic,其不同分区的 Leader 节点也不同。甚至,Kafka 倾向于用不同的 Broker 来做分区的 Leader,因为这样能做到更好的负载均衡。
在副本间的消息同步,实际上是复制消息的 log,复制可以是同步复制,也可以是异步复制。同步复制是说,当 Leader 收到消息后,将消息写入从副本,只有在收到从副本写入成功的确认后才返回成功给 Producer;异步复制是说,Leader 将消息写入从副本,但是不等待从副本的成功确认,直接返回成功给 Producer。同步复制效率较低,但是消息不会丢;异步复制效率高,但是在 Broker 宕机的时候,可能会出现消息丢失。
关于丢消息和重复收到消息
任何一个 MQ 都需要处理丢消息和重复收到消息的,正常情况下,Kafka 可以保证:1. 不丢消息;2. 不重复发消息;3. 消息读且只读一次。当然这都是正常情况,极端情况,如 Broker 宕机,断电,这类情况下,Kafka 只能保证 1 或者 2,无法保证 3。
在有副本的情况下,Kafka 是可以保证消息不丢的,其前提是设置了同步复制,这也是 Kafka 的默认设置,但是可能出现重复发送消息,这个交给上层应用解决;在生产者中使用异步提交,可以保证不重复发送消息,但是有丢消息的可能,如果应用可以容忍,也可以接受。如果需要实现读且只读一次,就比较麻烦,需要更底层的 API 4。