概述
Doris现在支持Broker load/routine load/stream load/mini batch load等多种导入方式。
spark load主要用于解决初次迁移,大量数据迁移doris的场景,用于提升数据导入的速度。
导入方式
所有导入方式都支持 csv 数据格式。其中 Broker load 还支持 parquet 和 orc 数据格式。
- Broker load
通过 Broker 进程访问并读取外部数据源(如 HDFS)导入到 Doris。用户通过 Mysql 协议提交导入作业后,异步执行。通过 SHOW LOAD 命令查看导入结果。 - Stream load
用户通过 HTTP 协议提交请求并携带原始数据创建导入。主要用于快速将本地文件或数据流中的数据导入到 Doris。导入命令同步返回导入结果。 - Insert
类似 MySQL 中的 Insert 语句,Doris 提供 INSERT INTO tbl SELECT ...; 的方式从 Doris 的表中读取数据并导入到另一张表。或者通过 INSERT INTO tbl VALUES(...); 插入单条数据。 - Multi load
用户通过 HTTP 协议提交多个导入作业。Multi Load 可以保证多个导入作业的原子生效。 - Routine load
用户通过 MySQL 协议提交例行导入作业,生成一个常驻线程,不间断的从数据源(如 Kafka)中读取数据并导入到 Doris 中。
导入执行流程:

Label 和 原子性:
Doris 对所有导入操作保证原子性,要么全部成功要么全部失败,不会出现只导数一部分的情况。每一个导数作业会用户指定或者系统自动生成一个label。label在一个database中唯一,导入成功之后就不能再重复使用了,导入失败则可以重复使用。
同步和异步:
Doris 目前的导入方式分为两类,同步和异步。
同步:
用户直接根据创建任务的返回结果判定是否成功导入。 同步类型的导入方式有: Stream load,Insert。
具体操作步骤如下:
- 用户(外部系统)创建导入任务。
- Doris 返回导入结果。
- 用户(外部系统)判断导入结果,如果失败可以再次提交导入任务。
异步:
导入任务会被异步执行,用户在创建成功后,需要通过轮询的方式发送查看命令查看导入作业的状态。如果创建失败,则可以根据失败信息,判断是否需要再次创建。
异步的话就是不知道最终结果,需要轮训获取执行结果,类比肯德基点餐,每次拿小纸条去询问是否做餐完毕。
异步类型的导入方式有:Broker load,Multi load。
- 用户(外部系统)创建导入任务。
- Doris 返回导入创建结果。
- 用户(外部系统)判断导入创建结果,成功则进入4,失败回到重试创建导入,回到1。
- 用户(外部系统)轮询查看导入任务,直到状态变为 FINISHED 或 CANCELLED。
至于重试次数不应该无限制重试,外部系统在有限次数重试并失败后,保留失败信息(记录日志,存入MySQL),大部分多次重试均失败问题都是使用方法问题或数据本身问题。
内存限制:
既然涉及到导数就必须限制每个任务的内存使用,这个和CK 相比是优点, CK 只有全局控制内存,没有单个任务级别控制内存使用。
一个导入任务会分布到多个BE上面执行, 内存参数限制的是每个BE节点的内存限制,而不是整个集群的内存限制。
较小的内存限制可能会影响导入效率,因为导入流程可能会因为内存达到上限而频繁的将内存中的数据写回磁盘。而过大的内存限制可能导致当导入并发较高时,系统OOM。所以,需要根据需求,合理的设置导入的内存限制。
最佳实践:
- 选择合适的导入方式:根据数据源所在位置选择导入方式。例如:如果原始数据存放在 HDFS 上,则使用 Broker load 导入。
- 确定导入方式的协议:如果选择了 Broker load 导入方式,则外部系统需要能使用 MySQL 协议定期提交和查看导入作业。
- 确定导入方式的类型:导入方式为同步或异步。比如 Broker load 为异步导入方式,则外部系统在提交创建导入后,必须调用查看导入命令,根据查看导入命令的结果来判断导入是否成功。
- 制定 Label 生成策略:Label 生成策略需满足,每一批次数据唯一且固定的原则。这样 Doris 就可以保证 At-Most-Once。
- 程序自身保证 At-Least-Once:外部系统需要保证自身的 At-Least-Once,这样就可以保证导入流程的 Exactly-Once。
通用系统配置
FE 配置
以下配置属于 FE 的系统配置,可以通过修改 FE 的配置文件 fe.conf 来修改配置。
- max_load_timeout_second 和 min_load_timeout_second
这两个配置含义为:最大的导入超时时间,最小的导入超时时间,以秒为单位。默认的最大超时时间为3天, 默认的最小超时时间为1秒。用户自定义的导入超时时间不可超过这个范围。该参数通用于所有的导入方式。
- desired_max_waiting_jobs
在等待队列中的导入任务个数最大值,默认为100。当在 FE 中处于 PENDING 状态(也就是等待执行的)导入个数超过该值,新的导入请求则会被拒绝。
此配置仅对异步执行的导入有效,当异步执行的导入等待个数超过默认值,则后续的创建导入请求会被拒绝。
- max_running_txn_num_per_db
这个配置的含义是说,每个 Database 中正在运行的导入最大个数(不区分导入类型,统一计数)。默认的最大导入并发为 100。当当前 Database 正在运行的导入个数超过最大值时,后续的导入不会被执行。如果是同步导入作业,则导入会被拒绝。如果是异步导入作业。则作业会在队列中等待。
BE 配置
以下配置属于 BE 的系统配置,可以通过修改 BE 的配置文件 be.conf 来修改配置。
- push_write_mbytes_per_sec
BE 上单个 Tablet 的写入速度限制。默认是 10,即 10MB/s。通常 BE 对单个 Tablet 的最大写入速度,根据 Schema 以及系统的不同,大约在 10-30MB/s 之间。可以适当调整这个参数来控制导入速度。
- write_buffer_size
导入数据在 BE 上会先写入一个 memtable,memtable 达到阈值后才会写回磁盘。默认大小是 100MB。过小的阈值可能导致 BE 上存在大量的小文件。可以适当提高这个阈值减少文件数量。但过大的阈值可能导致 RPC 超时,见下面的配置说明。
- tablet_writer_rpc_timeout_sec
导入过程中,发送一个 Batch(1024行)的 RPC 超时时间。默认 600 秒。因为该 RPC 可能涉及多个 memtable 的写盘操作,所以可能会因为写盘导致 RPC 超时,可以适当调整这个超时时间来减少超时错误(如 send batch fail 错误)。同时,如果调大 write_buffer_size 配置,也需要适当调大这个参数。
- streaming_load_rpc_max_alive_time_sec
在导入过程中,Doris 会为每一个 Tablet 开启一个 Writer,用于接收数据并写入。这个参数指定了 Writer 的等待超时时间。如果在这个时间内,Writer 没有收到任何数据,则 Writer 会被自动销毁。当系统处理速度较慢时,Writer 可能长时间接收不到下一批数据,导致导入报错:TabletWriter add batch with unknown id。此时可适当增大这个配置。默认为 600 秒。
- load_process_max_memory_limit_bytes 和 load_process_max_memory_limit_percent
这两个参数,限制了单个 Backend 上,可用于导入任务的内存上限。分别是最大内存和最大内存百分比。load_process_max_memory_limit_percent 默认为 80,表示对 Backend 总内存限制的百分比(总内存限制 mem_limit 默认为 80%,表示对物理内存的百分比)。即假设物理内存为 M,则默认导入内存限制为 M * 80% * 80%。
-
load_process_max_memory_limit_bytes 默认为 100GB。系统会在两个参数中取较小者,作为最终的 Backend 导入内存使用上限。
-
label_keep_max_second
设置导入任务记录保留时间。已经完成的( FINISHED or CANCELLED )导入任务记录会保留在 Doris 系统中一段时间,时间由此参数决定。参数默认值时间为3天。该参数通用与所有类型的导入任务。
批量删除
使用delete 语句的方式删除时,每执行一次delete 都会生成一个新的数据版本,如果频繁删除会严重影响查询性能,并且在使用delete 方式删除时,是通过生成一个空的rowset来记录删除条件实现,每次读取都要对删除跳条件进行过滤,同样在条件较多时会对性能造成影响。
所以批量删除解决的是传统delete语句,删除性能很差,具体为啥普通 delete性能很差, 根本原因是delete操作会生成多个版本,并且Doris采取, 记录删除条件的方式,然后在查询时过滤删除条件实现,所以普通 delete性能很差。
数据导入有三种合并方式:
- APPEND: 数据全部追加到现有数据中
- DELETE: 删除所有与导入数据key 列值相同的行
- MERGE: 根据 DELETE ON 的决定 APPEND 还是 DELETE
原理:
批量删除只能使用到 unique模型, 本质上还是通过逻辑删除实现
通过增加 DELETE_SIGN 隐藏列,该列是一个bool类型,replace 的隐藏列,当标记为删除时将该值标记为 true,比如刚开始这些KEY 对应的这个字段为 false , 当发生delete的时候, 该字段会变更为 true
具体使用手段如下, select * 时把该字段屏蔽掉,并且自动加上 DELETE_SIGN != true 过滤掉已经删除的数据
具体涉及到的流程如下:
- 导入 将隐藏列设置为 delete 语句
- 读取 所有存在隐藏列的加上 DELETE_SIGN != true
- Cumulative Compaction 将隐藏列看作正常的列处理,Compaction逻辑没有变化
- Base Compaction 将标记为删除的行的删掉,以减少数据占用的空间
stream load:
stream load 的写法在在header 中的 columns 字段增加一个设置删除标记列的字段, 示例 -H "columns: k1, k2, label_c3" -H "merge_type: [MERGE|APPEND|DELETE]" -H "delete: label_c3=1"
stream load 导入是顺序执行的, 其他导入不是顺序执行,其他的若要支持 merge, 则必须是保证顺序执行,这样才能保证 delete 不会把后面新插入的数据,误删除掉;其他的导数方式需要结合 load sequence 使用。
broker load:
在PROPERTIES 处设置删除标记列的字段
LOAD LABEL db1.label1
(
[MERGE|APPEND|DELETE] DATA INFILE("hdfs://abc.com:8888/user/palo/test/ml/file1")
INTO TABLE tbl1
COLUMNS TERMINATED BY ","
(tmp_c1,tmp_c2, label_c3)
SET
(
id=tmp_c2,
name=tmp_c1,
)
[DELETE ON label=true]
)
WITH BROKER 'broker'
(
"username"="user",
"password"="pass"
)
PROPERTIES
(
"timeout" = "3600"
);
routine load
启动批量删除支持
批量删除只支持 unique引擎, 并且必须指定详细的 unique key
- 通过在fe 配置文件中增加enable_batch_delete_by_default=true 重启fe 后新建表的都支持批量删除,此选项默认为false
- 对于没有更改上述fe 配置或对于以存在的不支持批量删除功能的表,可以使用如下语句: ALTER TABLE tablename ENABLE FEATURE "BATCH_DELETE" 来启用批量删除。本操作本质上是一个schema change 操作,操作立即返回,可以通过show alter table column 来确认操作是否完成。
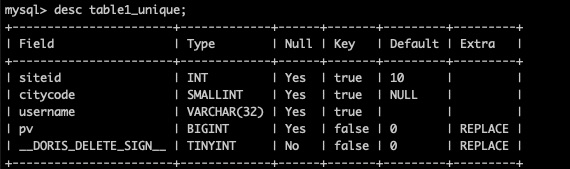
如何确定已经生效 , SET show_hidden_columns=true
desc tablename 如下出现了 DORIS_DELETE_SIGN 列则说明是支持批量删除的
使用示例:
-
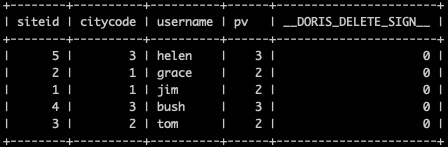
正常导入数据:
curl --location-trusted -u 'root:xxxx' -H "column_separator:," -H "columns: siteid, citycode, username, pv" -H "merge_type: APPEND" -T ./table1_data http://172.26.xx.143:8030/api/rtdw_bm/table1_unique/_stream_load
merge_type: APPEND 是默认行为 可以不设置
-
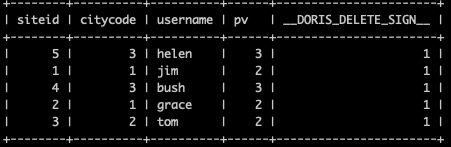
将与导入数据key 相同的数据全部删除, 以下本质就是 和 table1_data 文件中的数据做对比, 把按照 UNIQUE KEY 一样的数据置为逻辑删除,也就是 DORIS_DELETE_SIGN = 1
curl --location-trusted -u 'root:xxxx' -H "column_separator:," -H "columns: siteid, citycode, username, pv" -H "merge_type: DELETE" -T ./table1_data http://172.26.xxx.143:8030/api/rtdw_bm/table1_unique/_stream_load
执行完毕效果如下:
-
将导入数据中与site_id=1 的行的key列相同的行, 主要行为是 merge 也就是根据 delete: 指定的条件进行逻辑删除,其他的新增插入
curl --location-trusted -u 'root:xxxxx' -H "column_separator:," -H "columns: siteid, citycode, username, pv" -H "merge_type: MERGE" -H "delete: siteid=1" -T ./table1_data http://172.26.xxx.143:8030/api/rtdw_bm/table1_unique/_stream_load

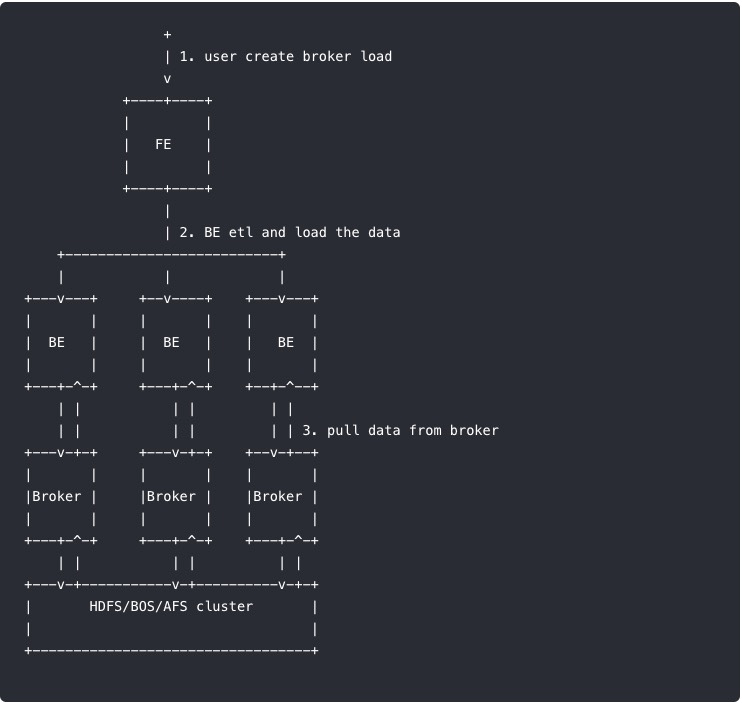
Broker Load
Broker load 是一个异步的导入方式,支持的数据源取决于 Broker 进程支持的数据源。
用户需要通过 MySQL 协议 创建 Broker load 导入,并通过查看导入命令检查导入结果。
适用场景:
1、 源数据在 Broker 可以访问的存储系统中,如 HDFS。
2、 数据量在 几十到百GB 级别。对于大数据量场景时间较长,异步方式可以提高用户体验度。
原理:
创建导入:
LOAD LABEL db_name.label_name
(data_desc, ...)
WITH BROKER broker_name broker_properties
[PROPERTIES (key1=value1, ... )]
* data_desc:
DATA INFILE ('file_path', ...)
[NEGATIVE]
INTO TABLE tbl_name
[PARTITION (p1, p2)]
[COLUMNS TERMINATED BY separator ]
[(col1, ...)]
[PRECEDING FILTER predicate]
[SET (k1=f1(xx), k2=f2(xx))]
[WHERE predicate]
* broker_properties:
(key1=value1, ...)
LOAD LABEL db1.label1
(
DATA INFILE("hdfs://abc.com:8888/user/palo/test/ml/file1")
INTO TABLE tbl1
COLUMNS TERMINATED BY ","
(tmp_c1,tmp_c2)
SET
(
id=tmp_c2,
name=tmp_c1
),
DATA INFILE("hdfs://abc.com:8888/user/palo/test/ml/file2")
INTO TABLE tbl2
COLUMNS TERMINATED BY ","
(col1, col2)
where col1 > 1
)
WITH BROKER 'broker'
(
"username"="user",
"password"="pass"
)
PROPERTIES
(
"timeout" = "3600"
);
注意事项:
1、 多张表导入也是支持的, 保证多个表导入的原子性
2、 timeout 导入超时时间,由于是异步执行,当超时时作业状态会被改为 CANCELLED,默认超时时间是 4小时
3、 max_filter_ratio 可以设置容忍率 ,容忍部分数据失败
4、merge_type 数据的合并类型,一共支持三种类型APPEND、DELETE、MERGE 其中,APPEND是默认值,表示这批数据全部需要追加到现有数据中,DELETE 表示删除与这批数据key相同的所有行,MERGE 语义 需要与delete 条件联合使用,表示满足delete 条件的数据按照DELETE 语义处理其余的按照APPEND 语义处理
查看导入结果 :
show load order by createtime desc limit 1\G
取消导入:
HELP CANCEL LOAD
性能分析
可以在提交 LOAD 作业前,先执行 set is_report_success=true 打开会话变量 ,打开后可以在 Doris 管理界面的 querys中查看 profile信息

实操:
1, 创建一个Doris表
CREATE TABLE `t10_unique` (
`name` varchar(32) NULL DEFAULT "" COMMENT "",
`age1` int(11) NULL DEFAULT "10" COMMENT ""
) ENGINE=OLAP
UNIQUE KEY(`name`, `age1`)
COMMENT "t10_unique"
DISTRIBUTED BY HASH(`name`) BUCKETS 10
PROPERTIES (
"replication_num" = "1",
"in_memory" = "false",
"storage_format" = "V2"
);
- 创建一个load任务
注意 HDFS 必须要定义到具体的文件不能是目录
(name,age) 此处指定的是 hive中的字段, 后续的 set可以设置对字段进行函数转换
此处有的 broker名字 Broker_Doris 必须每个真实集群的broker的名字。Broker 为一个独立的无状态进程。封装了文件系统接口,提供 Doris 读取远端存储系统中文件的能力。
set 属性设置: 代表获取在parquet或orc中以(tmp_c1, tmp_c2)为列名的列,映射到doris表中的(id, name)列。如果没有设置set, 则以column中的列作为映射。
也就是没有指定 set 则 以 (tmp_c1,tmp_c2) 名字赋值,没对应上的 设置默认值
有 SET 的话,则以 set中的赋值条件为准。
(tmp_c1,tmp_c2)
SET
(
id=tmp_c2,
name=tmp_c1
)
LOAD LABEL rtdw_bm.xxxxxx5
(
DATA INFILE("hdfs://172.24.28.65:9000/user/hive/warehouse/fff.db/t10/*")
INTO TABLE t10_unique
COLUMNS TERMINATED BY "|"
(name,age)
SET
(
name=name,
age1=age
)
where name = 'a'
)
WITH BROKER 'Broker_Doris'
("username"="yyy", "password"="yyy") PROPERTIES
(
"timeout" = "3600"
);
效果图:
select * from t10_unique;
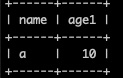
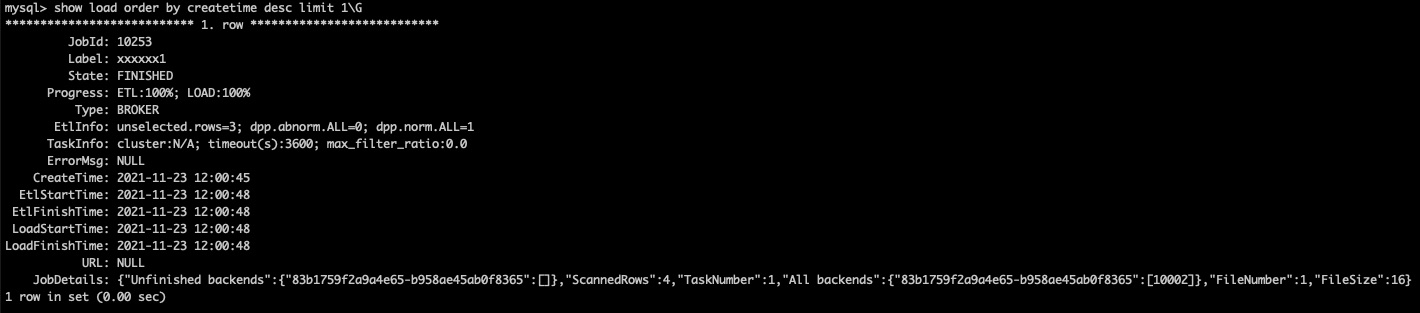
验证导入结果:
show load order by createtime desc limit 1\G
Routine Load
例行导入(Routine Load)功能为用户提供了一种自动从指定数据源进行数据导入的功能。
Stream load
基本原理
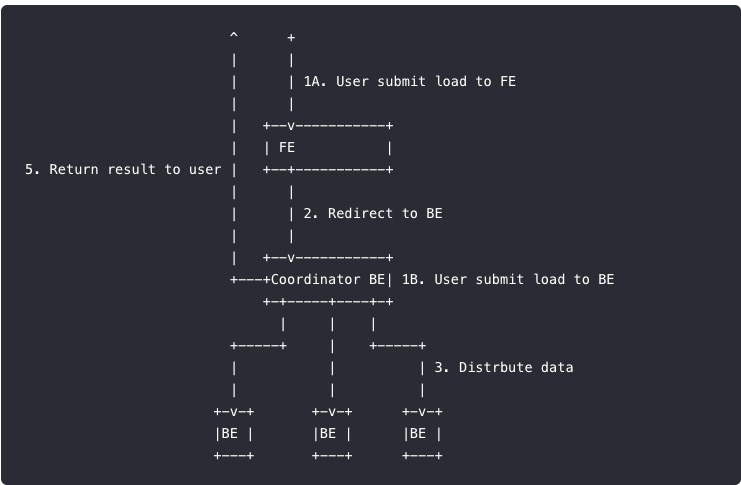
curl --location-trusted -u user:passwd [-H ""...] -T data.file -XPUT http://fe_host:http_port/api/{db}/{table}/_stream_load
Header 中支持属性见下面的 ‘导入任务参数’ 说明
格式为: -H "key1:value1"
curl --location-trusted -u root -T date -H "label:123" http://abc.com:8030/api/test/date/stream_load
导入任务参数
label : 导入任务的标识。
max_filter_ratio:导入任务的最大容忍率,默认为0容忍,取值范围是0~1。
where : 导入任务指定的过滤条件。
partition:待导入表的 Partition 信息,
columns: 待导入数据的函数变换配置,目前 Stream load 支持的函数变换方法包含列的顺序变化以及表达式变换,其中表达式变换的方法与查询语句的一致。
列顺序变换例子:原始数据有两列,目前表也有两列(c1,c2)但是原始文件的第一列对应的是目标表的c2列, 而原始文件的第二列对应的是目标表的c1列,则写法如下:
columns: c2,c1
表达式变换例子:原始文件有两列,目标表也有两列(c1,c2)但是原始文件的两列均需要经过函数变换才能对应目标表的两列,则写法如下:
columns: tmp_c1, tmp_c2, c1 = year(tmp_c1), c2 = month(tmp_c2)
其中 tmp*是一个占位符,代表的是原始文件中的两个原始列。
exec_mem_limit: 导入内存限制。默认为 2GB,单位为字节。
strict_mode: strict mode 模式的意思是:对于导入过程中的列类型转换进行严格过滤。
应用场景:
使用 Stream load 的最合适场景就是原始文件在内存中,或者在磁盘中。其次,由于 Stream load 是一种同步的导入方式,所以用户如果希望用同步方式获取导入结果,也可以使用这种导入。
curl --location-trusted -u user:password -T /home/store_sales -H "label:abc" http://abc.com:8000/api/bj_sales/store_sales/_stream_load