作者QQ:1095737364 QQ群:123300273 欢迎加入!
1.模式定义:
解释器模式是类的行为模式。给定一个语言之后,解释器模式可以定义出其文法的一种表示,并同时提供一个解释器。客户端可以使用这个解释器来解释这个语言中的句子。
2.模式特点:
解释器模式在实际的系统开发中使用的非常少,因为它会引起效率、性能以及维护等问题,一般在大中型的框架型项目能够找到它的身影,比如一些数据分析工具、报表设计工具、科学计算工具等等,若你确实遇到“一种特定类型的问题发生的频率足够高”的情况,准备使用解释器模式时,可以考虑一下Expression4J、MESP(Math Expression String Parser)、Jep等开源的解析工具包(这三个开源产品都可以百度、Google中搜索到,请读者自行查询),功能都异常强大,而且非常容易使用,效率也还不错,实现大多数的数学运算完全没有问题
3.使用场景:
(1)有一个简单的语法规则,比如一个sql语句,如果我们需要根据sql语句进行rm转换,就可以使用解释器模式来对语句进行解释。
(2)一些重复发生的问题,比如加减乘除四则运算,但是公式每次都不同,有时是a+b-c*d,有时是a*b+c-d,等等等等个,公式千变万化,但是都是由加减乘除四个非终结符来连接的,这时我们就可以使用解释器模式。
(3)当有一个语言需要解释执行,并且可以将该语言中的句子表示为一个抽象语法树的时候,可以考虑使用解释器模式。
(4)语法相对应该比较简单,太复杂的语法不合适使用解释器模式;
(5)效率要求不是很高,对效率要求很高的情况下,不适合使用解释器模式。
(6)重复发生的问题可以使用解释器模式,例如,多个应用服务器,每天产生大量的日志,需要对日志文件进行分析处理,由于各个服务器的日志格式不同,但是数据要素是相同的,按照解释器的说法就是终结符表达式都是相同的,但是非终结符表达式就需要制定了。在这种情况下,可以通过程序来一劳永逸地解决该问题。
4.模式实现:
下面就以一个示意性的系统为例,讨论解释器模式的结构。系统的结构图如下所示:
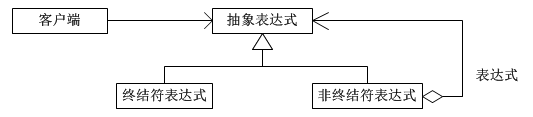
模式所涉及的角色如下所示:
(1)抽象表达式(Expression)角色:
声明一个所有的具体表达式角色都需要实现的抽象接口。这个接口主要是一个interpret()方法,称做解释操作。
(2)终结符表达式(Terminal Expression)角色:
实现了抽象表达式角色所要求的接口,主要是一个interpret()方法;文法中的每一个终结符都有一个具体终结表达式与之相对应。比如有一个简单的公式R=R1+R2,在里面R1和R2就是终结符,对应的解析R1和R2的解释器就是终结符表达式。
(3)非终结符表达式(Nonterminal Expression)角色:
文法中的每一条规则都需要一个具体的非终结符表达式,非终结符表达式一般是文法中的运算符或者其他关键字,比如公式R=R1+R2中,“+"就是非终结符,解析“+”的解释器就是一个非终结符表达式。
(4)环境(Context)角色:
这个角色的任务一般是用来存放文法中各个终结符所对应的具体值,比如R=R1+R2,我们给R1赋值100,给R2赋值200。这些信息需要存放到环境角色中,很多情况下我们使用Map来充当环境角色就足够了。
为了说明解释器模式的实现办法,这里给出一个最简单的文法和对应的解释器模式的实现,这就是模拟Java语言中对布尔表达式进行操作和求值。
在这个语言中终结符是布尔变量,也就是常量true和false。非终结符表达式包含运算符and,or和not等布尔表达式。这个简单的文法如下:
Expression ::= Constant | Variable | Or | And | Not
And ::= Expression 'AND' Expression
Or ::= Expression 'OR' Expression
Not ::= 'NOT' Expression
Variable ::= 任何标识符
Constant ::= 'true' | 'false'
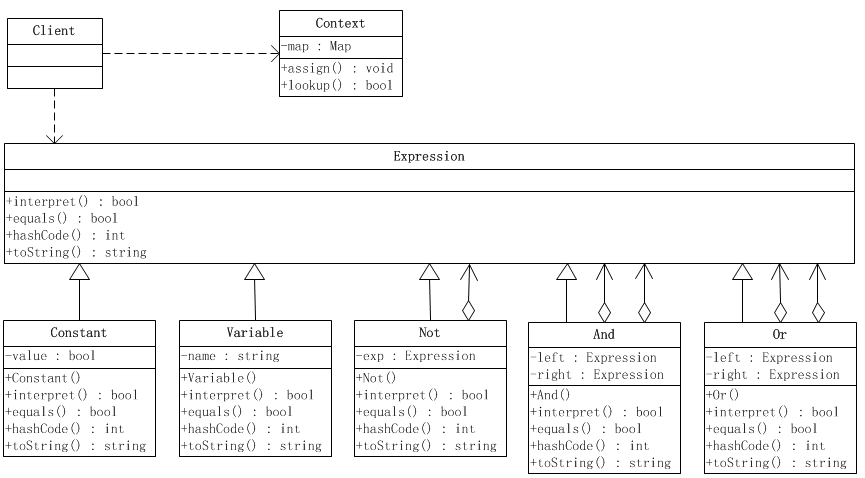
解释器模式的结构图如下所示:
源代码
[1]抽象表达式角色
public abstract class Expression { /** * 以环境为准,本方法解释给定的任何一个表达式 */ public abstract boolean interpret(Context ctx); /** * 检验两个表达式在结构上是否相同 */ public abstract boolean equals(Object obj); /** * 返回表达式的hash code */ public abstract int hashCode(); /** * 将表达式转换成字符串 */ public abstract String toString(); }
[2]一个Constant对象代表一个布尔常量
public class Constant extends Expression{ private boolean value; public Constant(boolean value){ this.value = value; } @Override public boolean equals(Object obj) { if(obj != null && obj instanceof Constant){ return this.value == ((Constant)obj).value; } return false; } @Override public int hashCode() { return this.toString().hashCode(); } @Override public boolean interpret(Context ctx) { return value; } @Override public String toString() { return new Boolean(value).toString(); } }
[3]一个Variable对象代表一个有名变量
public class Variable extends Expression { private String name; public Variable(String name){ this.name = name; } @Override public boolean equals(Object obj) { if(obj != null && obj instanceof Variable) { return this.name.equals( ((Variable)obj).name); } return false; } @Override public int hashCode() { return this.toString().hashCode(); } @Override public String toString() { return name; } @Override public boolean interpret(Context ctx) { return ctx.lookup(this); } }
[4]代表逻辑“与”操作的And类,表示由两个布尔表达式通过逻辑“与”操作给出一个新的布尔表达式的操作
public class And extends Expression { private Expression left,right; public And(Expression left , Expression right){ this.left = left; this.right = right; } @Override public boolean equals(Object obj) { if(obj != null && obj instanceof And) { return left.equals(((And)obj).left) && right.equals(((And)obj).right); } return false; } @Override public int hashCode() { return this.toString().hashCode(); } @Override public boolean interpret(Context ctx) { return left.interpret(ctx) && right.interpret(ctx); } @Override public String toString() { return "(" + left.toString() + " AND " + right.toString() + ")"; } }
[5]代表逻辑“或”操作的Or类,代表由两个布尔表达式通过逻辑“或”操作给出一个新的布尔表达式的操作
public class Or extends Expression { private Expression left,right; public Or(Expression left , Expression right){ this.left = left; this.right = right; } @Override public boolean equals(Object obj) { if(obj != null && obj instanceof Or) { return this.left.equals(((Or)obj).left) && this.right.equals(((Or)obj).right); } return false; } @Override public int hashCode() { return this.toString().hashCode(); } @Override public boolean interpret(Context ctx) { return left.interpret(ctx) || right.interpret(ctx); } @Override public String toString() { return "(" + left.toString() + " OR " + right.toString() + ")"; } }
[6]代表逻辑“非”操作的Not类,代表由一个布尔表达式通过逻辑“非”操作给出一个新的布尔表达式的操作
public class Not extends Expression { private Expression exp; public Not(Expression exp){ this.exp = exp; } @Override public boolean equals(Object obj) { if(obj != null && obj instanceof Not) { return exp.equals( ((Not)obj).exp); } return false; } @Override public int hashCode() { return this.toString().hashCode(); } @Override public boolean interpret(Context ctx) { return !exp.interpret(ctx); } @Override public String toString() { return "(Not " + exp.toString() + ")"; } }
[7]环境(Context)类定义出从变量到布尔值的一个映射
public class Context { private Map<Variable,Boolean> map = new HashMap<Variable,Boolean>(); public void assign(Variable var , boolean value){ map.put(var, new Boolean(value)); } public boolean lookup(Variable var) throws IllegalArgumentException{ Boolean value = map.get(var); if(value == null){ throw new IllegalArgumentException(); } return value.booleanValue(); } }
[8]客户端类
public class Client { public static void main(String[] args) { Context ctx = new Context(); Variable x = new Variable("x"); Variable y = new Variable("y"); Constant c = new Constant(true); ctx.assign(x, false); ctx.assign(y, true); Expression exp = new Or(new And(c,x) , new And(y,new Not(x))); System.out.println("x=" + x.interpret(ctx)); System.out.println("y=" + y.interpret(ctx)); System.out.println(exp.toString() + "=" + exp.interpret(ctx)); } }
运行结果如下:

5.优缺点:
(1)解释器模式的优点
[1]易于实现语法:在解释器模式中,一条语法规则用一个解释器对象来解释执行,对于解释器的实现来讲,功能就变得比较简单,只需要考虑这一条语法规则的实现就好了,其它的都不用管。
[2]易于扩展新的语法:正是由于采用一个解释器对象负责一条语法规则的方式,使得扩展新的语法非常容易,扩展了新的语法,只需要创建相应的解释器对象,在创建抽象语法树的时候使用这个新的解释器对象就可以了。
(2)解释器模式的缺点
[1]引起类膨胀:每个语法都要产生一个非终结符表达式,语法规则比较复杂时,就可能产生大量的类文件,为维护带来了非常多的麻烦。
[2]采用递归调用方法:每个非终结符表达式只关心与自己有关的表达式,每个表达式需要知道最终的结果,必须一层一层地剥茧,无论是面向过程的语言还是面向对象的语言,递归都是在必要条件下使用的,它导致调试非常复杂。想想看,如果要排查一个语法错误,我们是不是要一个一个断点的调试下去,直到最小的语法单元。
[3]效率问题:解释器模式由于使用了大量的循环和递归,效率是个不容忽视的问题,特别是用于解析复杂、冗长的语法时,效率是非常低的。
6.注意事项
尽量不要在重要的模块中使用解释器模式,否则维护会是一个很大的问题。在项目中可以使用shell、JRuby、Groovy等脚本语言来代替解释器模式,弥补Java编译型语言的不足。我们在一个银行的分析型项目中就采用JRuby进行运算处理,避免使用解释器模式的四则运算,效率和性能各方面表现良好。
解释器模式真的是一个比较少用的模式,因为对它的维护实在是太麻烦了,想象一下,一坨一坨的非终结符解释器,假如不是事先对文法的规则了如指掌,或者是文法特别简单,则很难读懂它的逻辑。解释器模式在实际的系统开发中使用的很少,因为他会引起效率、性能以及维护等问题。