Support Vector Machines for classification
To whet your appetite for support vector machines, here’s a quote from machine learning researcher Andrew Ng:
“SVMs are among the best (and many believe are indeed the best) ‘off-the-shelf’ supervised learning algorithms.”

Professor Ng covers SVMs in his excellent Machine Learning MOOC, a gateway for many into the realm of data science, but leaves out some details, motivating us to put together some notes here to answer the question:
“What are the support vectors in support vector machines?”
We also provide python code using scikit-learn’s svm module to fit a binary classification problem using a custom kernel, along with code to generate the (awesome!) interactive plots in Part 3.
This post consists of three sections:
- Part 1 sets up the problem from a geometric point of view and then shows how it can be framed as an optimization problem.
- Part 2 transforms the optimization problem and uncovers the support vectors in the process.
- Part 3 discusses how kernels can be used to separate non-linearly separable data.
Part 1: Defining the margin
Maximizing the margin
The figure below is a binary classification problem (points labeled yi=±1) that is linearly separable.
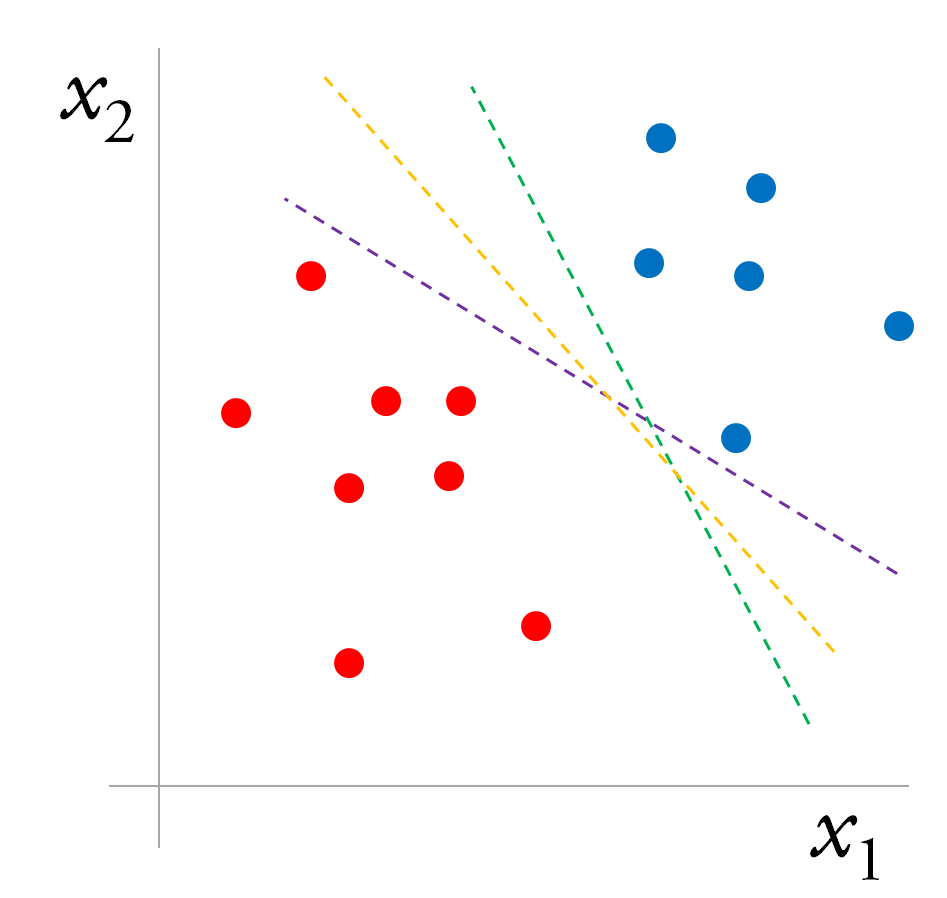
There are many possible decision boundaries that would perfectly separate the two classes, but an SVM will choose the line in 2-d (or “hyperplane”, more generally) that maximizes the margin around the boundary.
Intuitively, we can be very confident about the labels of points that fall far from the boundary, but we’re less confident about points near the boundary.
Formulating the margin with geometry
Any point x lying on the separating hyperplane satisfies:
w⋅x+b=0
w is the vector normal to the plane, and b is a constant that describes how much the plane is shifted relative to the origin. The distance of the plane from the origin is b/∥w∥.
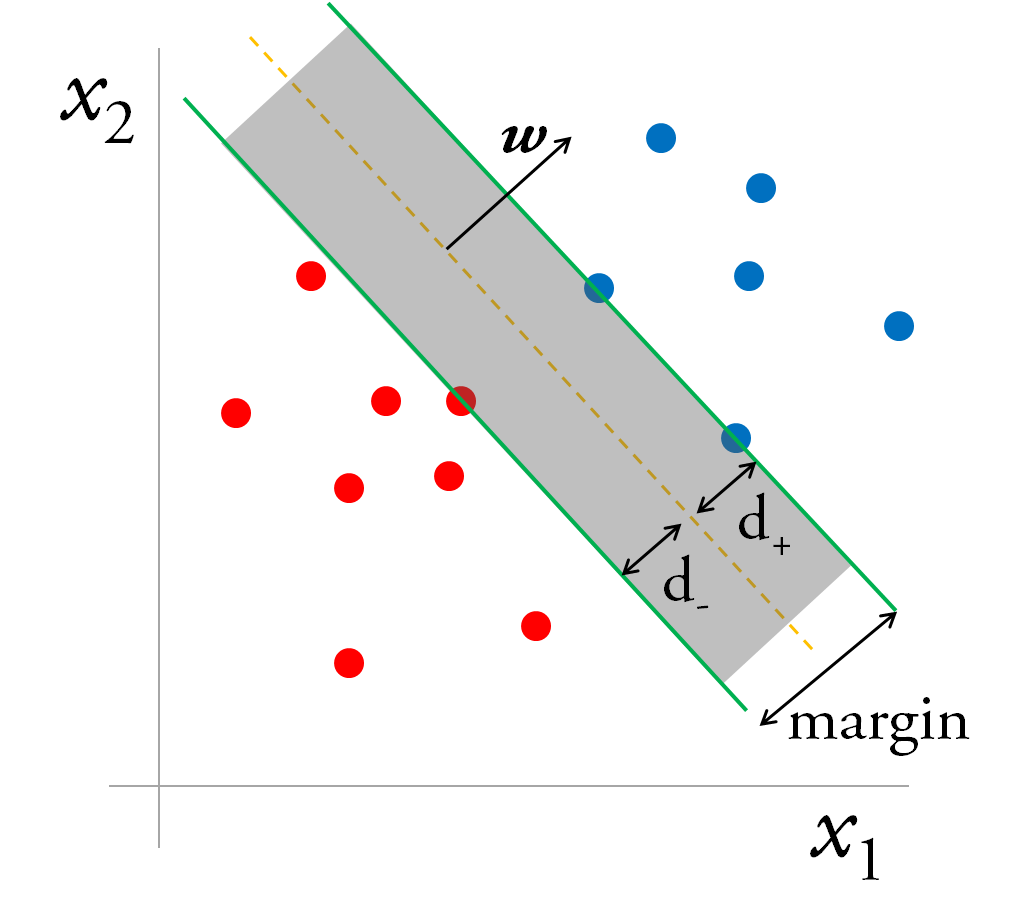
Now draw parallel planes on either side of the decision boundary, so we have what looks like a road, with the decision boundary as the median, and the additional planes as gutters. The margin, i.e. the width of the road, is (d++d−) and is restricted by the data points closest to the boundary, which lie on the gutters.
The half-spaces bounded by the planes on the gutters are:
w⋅x+b≥+a, for yi=+1
w⋅x+b≤−a, for yi=−1
These two conditions can be put more succinctly:
yi(w⋅x+b)≥a,∀i
Some arithmetic leads to the equation for the margin:
d++d−=2a/∥w∥
Without loss of generality, we can set a=1, since it only sets the scale (units) of b and w. So to maximize the margin, we have to maximize 1/∥w∥. However, this is an unpleasant (non-convex) objective function. Instead we minimize ∥w∥2, which is convex.
The optimization problem
Maximizing the margin boils down to a constrained optimization problem: minimize some quantity f(w), subject to constraints g(w,b). This optimization problem is particularly nice because it is convex; the objective ∥w∥2 is convex, as are the constraints, which are linear.
In other words, we are faced with a quadratic programming problem. The standard format of the optimization problem for the separable case is
Before we address how to solve this optimization problem in Part 2, let’s first consider the case when data is non-separable.
Soft margin SVM: the non-separable problem and regularization
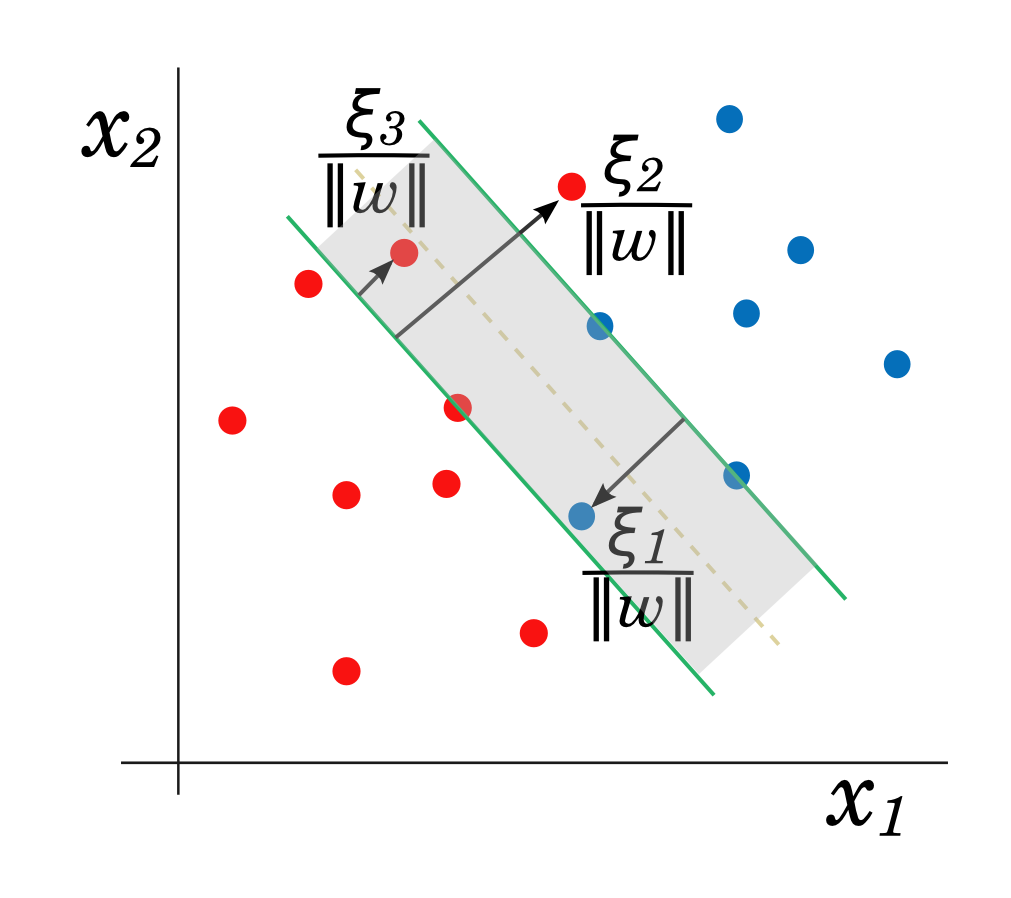
For non-separable data, we relax the constraints in (1) while penalizing misclassified points via a cost parameter C and slack variables ξi that define the amount by which data points are on the wrong side of the margin.
A large penalty — large C — for misclassifications will lead to learning a lower bias, higher variance SVM, and vice versa for small C.
The soft margin is used in practice; even in the separable case, it can be desirable to allow tradeoffs between the size of the margin and number of misclassifications. Outliers can skew the decision boundary learned by (1) towards a model with small margins + perfect classification, in contrast to a possibly more robust model learned by (2) with large margins + some misclassified points.
Part 2: Solving the optimization problem
In Part 1, we showed how to set up SVMs as an optimization problem. In this section, we’ll see how the eponymous support vectors emerge when we rephrase the minimization problem as an equivalent maximization problem.
To recap: Given m training points that are labeled yi=±1, our goal is to maximize the margin of the hyperplane defined by w⋅x+b=0.
We’ll use the separable case (1) as our starting point, but the steps in the procedure and final result are similar for the non-separable case (also worked out in ref [3]).
The Lagrangian formulation
How do we solve this optimization problem? Minimizing a function without constraints is probably familiar: set the derivative of the function (the objective) to zero and solve.
With constraints, the procedure is similar to setting the derivative of the objective equal to zero. Instead of taking the derivative of the objective itself, however, we’ll operate on the Lagrangian L, which combines the objective and inequality constraints into one function:
We’ve just introduced additional variables αi, Lagrange multipliers, that make it easier to work with the constraints (see Wikipedia about the method of Lagrange multipliers). Note, a more general form for the Lagrangian would include another summation term in (3) to uphold equality constraints. Since there are only inequality constraints here, we’ll omit the extra term.
Constructing the dual problem
Much of the following discussion is based off ref [2], which has a nice introduction to duality in the context of SVMs.
First, let’s make the following observation:
Basically, if any constraint j is violated, i.e. gj(w)>0, then the Lagrange multiplier αj that is multiplying gj(w) can be made arbitrarily large (→∞) in order to maximize L.
On the other hand, if all the constraints are satisfied, gi(w)≤0 ∀i, then L is maximized by setting the αis that are multiplying negative quantities equal to zero. However, Lagrangian multipliers multiplying gi(w) that satisfy the constraints with equality, gi(w)=0, can be non-zero without diminishing L.
The last statement amounts to the property of “complementary slackness” in the Karush-Kuhn-Tucker conditions for the solution:
Recall from the original geometric picture: only a few points lie exactly on the margins, and those points are described by gi(w)=0 (and thus have non-zero Lagrange multipliers). The points on the margin are the support vectors.
Next, we make use of the Max-Min inequality:
This inequality is an equality under certain conditions, which our problem satisfies (convex f and g). The left side of the inequality is called the dual problem, and the right side is the primal problem.
Now we can put it all together: Observation 1 tells us that solving the right side (primal problem) of the Max-Min inequality is the same as solving the original problem. Because our problem is convex, solving the left side (dual) is equivalent to solving the primal problem by the Max-Min inequality.
Thus we’re set to approach the solution via the dual problem, which is useful for dealing with nonlinear decision boundaries.
Solving the dual problem
The dual problem to solve is maxαminw,bL(w,b,α), subject to constraints* on the Lagrange multipliers: αi≥0.
Let’s work out the inner part of the expression explicitly. We obtain minw,bL(w,b,α) by setting:
These equations for the partial derivatives give us, respectively:
w is a linear combination of the coordinates of the training data. Only the support vectors, which have non-zero αi, contribute to the sum. To predict the label for a new test point xt, simply evaluate the sign of
where b can be computed from the KKT complementarity condition (4) by plugging in the values for any support vector. The equation for the separating hyperplane is entirely determined by the support vectors.
Plugging the last two equations into L leads to the dual formulation of the problem maxαLD:
The dual for the non-separable primal Lagrangian (2) — derived using the same procedure we just followed — looks just like the dual for the separable case (6), except that the Lagrange multipliers are bounded from above by the regularization constant: 0≤αi≤C. Notably, the slack variables ξi do not appear in the dual of the soft margin SVM.
The dual (called the Wolfe dual) is easier to solve because of the simpler form of its inequality constraints and is the form used in algorithms such as the Sequential Minimal Optimizationalgorithm, which is implemented in the popular SVM solver, LIBSVM. The key feature of the dual is that training vectors only appear as dot products xi⋅xj. This property allows us to generalize to the nonlinear case via the “kernel trick” discussed in Part 3 of this post.
* Some of you may be familiar with using Lagrangian multipliers to optimize some function f(x)subject to equality constraints g(x)=0, in which case the Lagrangian multipliers are unconstrained. The Karush-Kuhn-Tucker conditions generalize the method to include inequality constraints g(x)≤0, which results in additional constraints on the associated Lagrangian multipliers (as we have here).
Part 3: Kernels
Data that is not linearly separable in the original input space may be separable if mapped to a different space. Consider the following example of nonlinearly separable, two-dimensional data:
However, if we map the 2-d input data x=(x,y) to 3-d feature space by a function Φ(x)=(x,y,x2+y2), the blue and red points can be separated with a plane in the new (3-d) space. See the plot below of the decision boundary, the mapped points, as well as the the original data points in the x-y plane. Drag the figure to rotate it, or zoom in and out with your mouse wheel!
Code to generate and fit the data in this example with scikit-learn’s SVM module, as well as code to create the plot.ly interactive plots above, is available in IPython notebooks on github.
From maps to kernels
So how do we incorporate mapping the data into the formulation of the problem?
Recall that the data appears as a dot product in the dual Lagrangian (6). If we decide to train an SVM on the mapped data, then the dot product of the input data in (6) is replaced by the dot product of the mapped data: xi⋅xj→Φ(xi)⋅Φ(xj)
The kernel is simply the dot product of the mapping functions. In the example above, the inner product of the mapping function is an instance of a polynomial kernel:
In practice, we work directly with the kernel K(xi,xj) rather than explicitly computing the map of the data points**. Computing the kernel directly allows us to sidestep the computationally expensive operation of mapping data to a high dimensional space and then taking a dot product (see ref [2] for examples comparing computational times of the two methods).
Using a kernel, the second term in the objective of the dual problem (6) becomes
The kernel also appears in the evaluation of (5) to predict the classification of a test point xt:
Which functions are valid kernels to use in the kernel trick? i.e. given K(xi,xj), does some feature map Φ exist such that K(xi,xj)=Φ(xi)⋅Φ(xj) for any i, j? Mercer’s condition states that a necessary and sufficient condition for K to be a valid kernel is that it is symmetric and positive semi-definite†.
Some popular kernels are:
The optimal parameters for the degree of the polynomial p and spread of the Gaussian σ (as well as the regularization parameter) are determined by cross-validation. Computing the above kernels takes O(d) time, where d is the dimension of the input space, since we have to evaluate xi⋅xj in the polynomial kernel and xi–xj in the Gaussian kernel.
Comparing runtimes of linear and nonlinear kernels
The computational complexity for classification/prediction, i.e. at test time, can be obtained by eyeballing (5) and (8). Let d be the dimension of the input space and n be the size of the training set, and assume the number of support vectors nS is some fraction of n, nS∼O(n).
In the case of working with the linear kernel/original input space, w can be explicitly evaluated to obtain the separating hyperplane parameters, so that classification in (5) takes O(d) time. On the other hand, with the kernel trick, the hyperplane parameters are not explicitly evaluated. Assume calculating a kernel takes O(d) time, cf. the polynomial and Gaussian kernels; then test time for a nonlinear K in (8) takes O(nd) time.
Estimating the computational complexity for training is complicated, so we defer the discussion to refs [4a, 4b] and simply state the result: training for linear kernels is O(nd) while training for nonlinear kernels using the Sequential Minimal Optimization algorithm is O(n2) to O(n3)(dependent on the regularization parameter C), making nonlinear kernel SVMs impractical for larger datasets (a couple of 10,000 samples according to scikit-learn).
** More than one mapping and feature space (dimension) may exist for a particular kernel. See section 4 of ref [1] for examples.
† See ref [2] for a simple proof in terms of the Kernel (Gram) matrix, i.e. the kernel function evaluated on a finite set of points.
Discussion
We’ve glimpsed the elegant theory behind the construction of SVMs and seen how support vectors pop out of the mathematical machinery. Geometrically, the support vectors are the points lying on the margins of the decision boundary.
How about using SVMs in practice?
In his Coursera course, Professor Ng recommends linear and Gaussian kernels for most use cases. He also provides some rules of thumb (based on the current state of SVM algorithms) for different sample sizes n and input data dimension/number of features d, restated here:
| case | method | n | d |
|---|---|---|---|
| n≪d, e.g. genomics, bioinformatics data | linear kernel SVM or logistic regression | 10 – 1000 | 10,000 |
| n intermediate, d small | Gaussian kernel SVM | 10 – 10,000 | 1 – 1000 |
| n≫d | create features, then linear kernel SVM or logistic regression | 50,000+ | 1 – 1000 |
The creators of the LIBSVM and LIBLINEAR packages also provide a user’s guide for novices, which includes a study of when to use linear instead of radial basis function kernels. They recommend linear SVMs when d and n are both large, often encountered in document classification problems where bag-of-words approaches can generate huge numbers of features (in their example n=20,000, d= 47,000).
The idea is that if the input data is already high-dimensional, then it shouldn’t be necessary to apply nonlinear transformations to it in order to obtain a separating hyperplane.
Tip: LIBLINEAR is specifically optimized for linear kernels and should be used instead of LIBSVM in the linear case.
Further reading
In addition to the many excellent written tutorials on SVMs online, we highly recommend viewing lectures 14 and 15 of Yaser Abu-Mostafa’s MOOC, Learning from Data, which cover SVMs at about the same level as this post, with the considerable added benefit of Professor Abu-Mostafa’s explanations. He also discusses the generalization performance of SVMs as a function of the number of support vectors using VC theory (also see [1]).
There is a lot more theory on SVMs that we haven’t touched upon. For example, SVMs can be framed as a penalization method [3] or “regularization network”, c.f. ridge regression, but with a hinge loss rather than squared error. Insights about the choice of a kernel have also been developed in that framework.
[1] Burges, C. J.C. (1998). A Tutorial on Support Vector Machines for Pattern Recognition. Knowledge Discovery and Data Mining 2 (2) 121-167.
[2] Ng, A. Support Vector Machines [PDF document]. Retrieved from lecture notes online: http://cs229.stanford.edu/notes/cs229-notes3.pdf
Lecture notes by Andrew Ng for a more advanced class (but still in his signature intuitive style).
[3] Hastie, T., Tibshirani, R., and Friedman, J. (2009). The Elements of Statistical Learning.
See section 12.2.1, page 420, for derivation of the dual Lagrangian for the nonseparable case.
[4a] Bottou, L. and Lin C-J., (2006). Support Vector Machine Solvers.
[4b] Chang, C-C. and Lin C-J., (2013). LIBSVM: A Library for Support Vector Machines.
[5] Ben-Hur, A. and Weston, J. (2009). A User’s Guide to Support Vector Machines. In Carugo, O. and Eisenhaber, F. (Eds.), Methods in Molecular Biology 609, 223-229.
Andrew Ng photo credit: InverseHypercube, creative commons license.