转自:https://yq.aliyun.com/articles/51753
摘要: 写在前面 explain对我们优化sql语句是非常有帮助的。可以通过explain+sql语句的方式分析当前sql语句。 例子 EXPLAIN SELECT dt,method,url FROM app_log WHERE id=11789 table 显示这一行数据属于哪张表,若在查询中为select起了别名,则显示别名。
写在前面
explain对我们优化sql语句是非常有帮助的。可以通过explain+sql语句的方式分析当前sql语句。
例子
EXPLAIN SELECT dt,method,url FROM app_log WHERE id=11789

table
显示这一行数据属于哪张表,若在查询中为select起了别名,则显示别名。
EXPLAIN SELECT dt,method,url FROM app_log AS temp WHERE id=11789

type
在表里查到结果所用的方式。包括(性能有差——>高): All | index | range | ref | eq_ref | const,system | null |
all:全表扫描,MySQL 从头到尾扫描整张表查找行。
EXPLAIN SELECT dt,method,url FROM app_log AS temp LIMIT 100

注意:这里虽然使用limit但并不能改变全表扫描。
index:按索引扫描表,虽然还是全表扫描,但优点是索引是有序的。
EXPLAIN SELECT id FROM app_log AS temp LIMIT 100

range:以范围的方式扫描索引。比较运算符,以及in的type都是range。
EXPLAIN SELECT * FROM app_log AS temp WHERE id>100 LIMIT 199

ref:非唯一性索引访问
EXPLAIN SELECT * FROM app_log AS temp WHERE dt='2015-01-02' LIMIT 199

eq_ref:使用唯一性索引查找(主键或唯一索引)
EXPLAIN SELECT * FROM app_log JOIN app_details_log USING(id)

先全表扫描了app_details_log表,然后在对app_log进行eq_ref查找。因为app_log的id字段是主键。如果此时删除app_log的id为主键,则都会进行全表扫描。
const:常量,在整个查询过程中这个表最多只会有一条匹配的行,比如主键 id=1 就肯定只有一行,只需读取一次表数据便能取得所需的结果,且表数据在分解执行计划时读取。
EXPLAIN SELECT * FROM app_log WHERE id=11790

注意:system 是 const 类型的特例,当表只有一行时就会出现 system 。
null:在优化的过程已经得到结果,不再需要访问表或索引。例如表中并不存在id=1000的记录。
EXPLAIN SELECT * FROM app_log WHERE id=1000

possible_keys
可能被用到的索引。
EXPLAIN SELECT * FROM app_log WHERE id>100 LIMIT 100 ;

Key
查询过程中实际用到的索引,例子如上图,实际用的索引列为主键列。
key_len
索引字段最大可能使用的长度。例如上图中,Key_len:4,因为主键是int类型,长度为4.
ref
指出对key列所选择的索引的查找方式,常见的有const,func,null,具体字段名。当key列为null,即不使用索引时,此值也为null.
rows
mysql估计需要扫描的行数,只是一个估算。
Extra
这个显示其他的一些信息,但对优化sql也非常的重要。
using Index:此查询使用了覆盖索引(Convering Index),即通过索引就能返回结果,无需访问表。弱没显示“Using Index”表示读取了表数据。
EXPLAIN SELECT id FROM app_log;

因为 id 为主键索引,索引中直接包含了 id 的值,所以无需访问表,直接查找索引就能返回结果。
using where:mysql从存储引擎收到行后再进行“后过滤(Post-filter)”。后过滤:先读取整行数据,再检查慈航是否符合where的条件,符合就留下,不符合便丢弃。检测是在读取行后进行的,所以叫后过滤。
EXPLAIN SELECT id FROM app_log WHERE id>100 LIMIT 100;

using temporary:使用到临时表,在使用临时表的时候,Extra为这个值。
using filesort:若查询所需的排序与使用的索引的排序一直,因为索引已排序,因此按索引的顺序读取结果返回,否则,在取到结果后,还需要按查询所需的顺序对结果进行排序,这时就会出现using filesort。
EXPLAIN SELECT id FROM app_log WHERE id>100 GROUP BY dt;
![]()
一个优化的例子
我需要对app_log的表按时间进行分组,显示每个小时的人数。
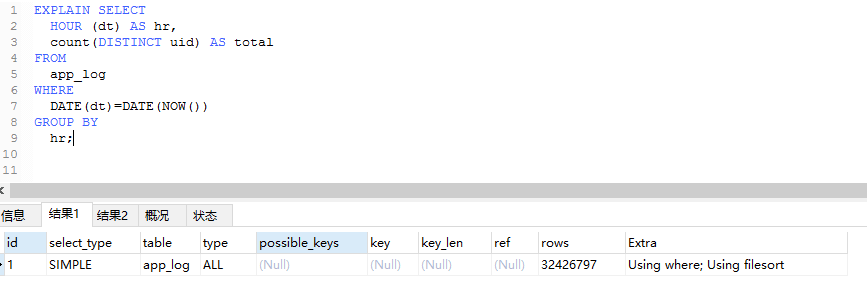

通过上面你可以看到type一个为all,一个为range。为all的查询需要23+s,而下面的则只需要0.3s。通过rows也能看出优化后,表扫描的行数变化。
假设有下面的 SELECT 语句,正打算用 EXPLAIN 来检测:
EXPLAIN SELECT tt.TicketNumber, tt.TimeIn, tt.ProjectReference, tt.EstimatedShipDate, tt.ActualShipDate, tt.ClientID, tt.ServiceCodes, tt.RepetitiveID, tt.CurrentProcess, tt.CurrentDPPerson, tt.RecordVolume, tt.DPPrinted, et.COUNTRY, et_1.COUNTRY, do.CUSTNAME FROM tt, et, et AS et_1, do WHERE tt.SubmitTime IS NULL AND tt.ActualPC = et.EMPLOYID AND tt.AssignedPC = et_1.EMPLOYID AND tt.ClientID = do.CUSTNMBR;
在这个例子中,先做以下假设:
- 要比较的字段定义如下:
Table Column Column Type ttActualPCCHAR(10)ttAssignedPCCHAR(10)ttClientIDCHAR(10)etEMPLOYIDCHAR(15)doCUSTNMBRCHAR(15) - 数据表的索引如下:
Table Index ttActualPCttAssignedPCttClientIDetEMPLOYID(primary key)doCUSTNMBR(primary key) tt.ActualPC的值是不均匀分布的。
在任何优化措施未采取之前,经过 EXPLAIN 分析的结果显示如下:
table type possible_keys key key_len ref rows Extra et ALL PRIMARY NULL NULL NULL 74 do ALL PRIMARY NULL NULL NULL 2135 et_1 ALL PRIMARY NULL NULL NULL 74 tt ALL AssignedPC, NULL NULL NULL 3872 ClientID, ActualPC range checked for each record (key map: 35)
由于字段 type 的对于每个表值都是 ALL,这个结果意味着MySQL对所有的表做一个迪卡尔积;这就是说,每条记录的组合。这将需要花很长的时间,因为需要扫描每个表总记录数乘积的总和。在这情况下,它的积是 74 * 2135 * 74 * 3872 = 45,268,558,720 条记录。
在这里有个问题是当字段定义一样的时候,MySQL就可以在这些字段上更快的是用索引(对 ISAM 类型的表来说,除非字段定义完全一样,否则不会使用索引)。在这个前提下,VARCHAR 和 CHAR是一样的除非它们定义的长度不一致。由于 tt.ActualPC 定义为 CHAR(10),et.EMPLOYID 定义为 CHAR(15),二者长度不一致。
为了解决这个问题,需要用 ALTER TABLE 来加大 ActualPC 的长度从10到15个字符:
mysql> ALTER TABLE tt MODIFY ActualPC VARCHAR(15);
现在 tt.ActualPC 和 et.EMPLOYID 都是 VARCHAR(15)
了。再来执行一次 EXPLAIN 语句看看结果:
table type possible_keys key key_len ref rows Extra tt ALL AssignedPC, NULL NULL NULL 3872 Using ClientID, where ActualPC do ALL PRIMARY NULL NULL NULL 2135 range checked for each record (key map: 1) et_1 ALL PRIMARY NULL NULL NULL 74 range checked for each record (key map: 1) et eq_ref PRIMARY PRIMARY 15 tt.ActualPC 1
这还不够,它还可以做的更好:现在 rows 值乘积已经少了74倍。这次查询需要用2秒钟。
第二个改变是消除在比较 tt.AssignedPC = et_1.EMPLOYID 和 tt.ClientID = do.CUSTNMBR 中字段的长度不一致问题:
mysql> ALTER TABLE tt MODIFY AssignedPC VARCHAR(15), -> MODIFY ClientID VARCHAR(15);
现在 EXPLAIN 的结果如下:
table type possible_keys key key_len ref rows Extra et ALL PRIMARY NULL NULL NULL 74 tt ref AssignedPC, ActualPC 15 et.EMPLOYID 52 Using ClientID, where ActualPC et_1 eq_ref PRIMARY PRIMARY 15 tt.AssignedPC 1 do eq_ref PRIMARY PRIMARY 15 tt.ClientID 1
这看起来已经是能做的最好的结果了。
遗留下来的问题是,MySQL默认地认为字段tt.ActualPC 的值是均匀分布的,然而表 tt 并非如此。幸好,我们可以很方便的让MySQL分析索引的分布:
mysql> ANALYZE TABLE tt;
到此为止,表连接已经优化的很完美了,EXPLAIN 的结果如下:
table type possible_keys key key_len ref rows Extra tt ALL AssignedPC NULL NULL NULL 3872 Using ClientID, where ActualPC et eq_ref PRIMARY PRIMARY 15 tt.ActualPC 1 et_1 eq_ref PRIMARY PRIMARY 15 tt.AssignedPC 1 do eq_ref PRIMARY PRIMARY 15 tt.ClientID 1
请注意,EXPLAIN 结果中的 rows 字段的值也是MySQL的连接优化程序大致猜测的,请检查这个值跟真实值是否基本一致。如果不是,可以通过在 SELECT 语句中使用 STRAIGHT_JOIN 来取得更好的性能,同时可以试着在FROM
分句中用不同的次序列出各个表。