问题背景
最近遇到一个比较棘手的事情:hive sql优化:
lib表(id,h,soj,noj,sp,np) --一个字典表
mitem表(md,mt,soj,noj,sp,np)--一天的数据,包含小时分区的表。
业务:
1)需要先把lib表与mitem表进行关联(关联条件是lib.soj=mitem.soj and lib.noj=mitem.noj),关联后的结果按照soj,md,mt,id,h进行分组;
2)对1)中的结果在分组的时候需要统计差值的平均值记为svalue;
3)对关联后的分区的统计后的数据,进行一次分组排序:按照soj,md,mt分组,按照svalue排序,只保留同一个分组内排序第一的记录。
其中表lib有3亿条记录,mitem表包含记录数50~150亿左右,lib与mitem关联后的记录数在6000亿条记录,之后对这个关联后的结果进行进行分组却执行了6小时后抛出异常问题。
尝试解决方案
瓶颈主要体现在在对第一次关联后的记录包含了6000亿条记录进行分组时,耗费资源,资源不足导致的问题。
尝试过的解决方案:
1)创建索引:《hive:创建索引》
针对该6000亿条记录进行创建索引,耗费了20小时后依然是在stage2失败了,此方案推翻。
2)对mitem数据按照小时粒度进行数据拆分,之后每一个小时的mitem与lib进行关联,结果耗费时间为20多个小时,依然是抛出异常。
3)对mitem数据按照小时粒度进行分区,同时对lib表按照字段soj进行分页(分10页,一页中包含的lib记录数约3000w条)《hive:某张表进行分页》
create table lib_soj as select soj from lib group by soj;--记录数约为8000条记录
create table lib_soj_page as select row_number()over(order by soj)rnum,soj from lib_soj;
create table lib_1_1000 as select t10.* from lib t10 inner join lib_soj_page t11 on t10.soj=t11.soj where t11.rnum between 1 and 1000;--记录数约为3000w条记录。
此时,拿一个小时的select * from mitem where hour='2017102412' 与一个分页中的soj进行关联,数据终于出来了,可是耗费的时间为1小时20分,那么该总体时间为1.33*24*10小时。时间实际上太长了。
4)针对2)、3)的方案我们得知,如果把mitem查分带来的效果实际上是不大,而查分lib的效果特别明显,于是想到如果把lib查分的粒度更细与一天的mitem进行关联是否可行(这里是查分为20份,一份数据约为1500w)。
测试结果,耗时3小时20分,那么总体的时间约为3.33*20小时。如果并行执行多个分页的数据相信时间上会缩短。
但是目前这个方案应该是shuffle时出现了数据偏移问题:
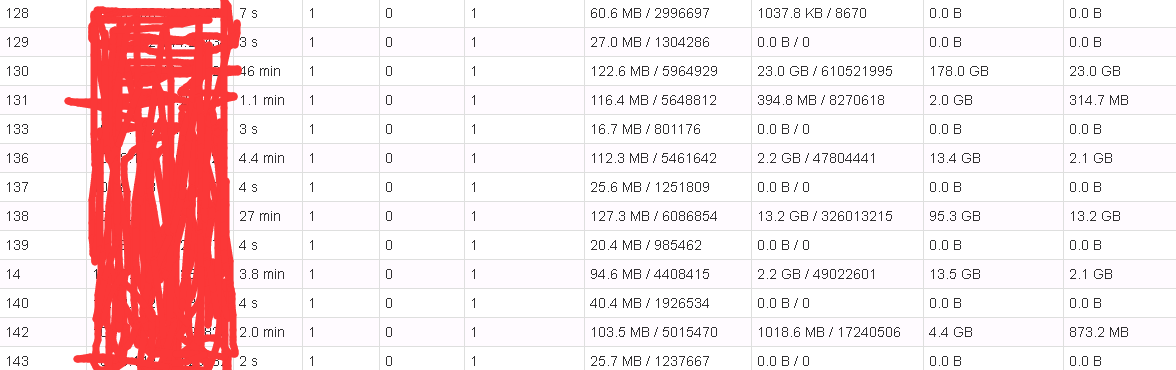
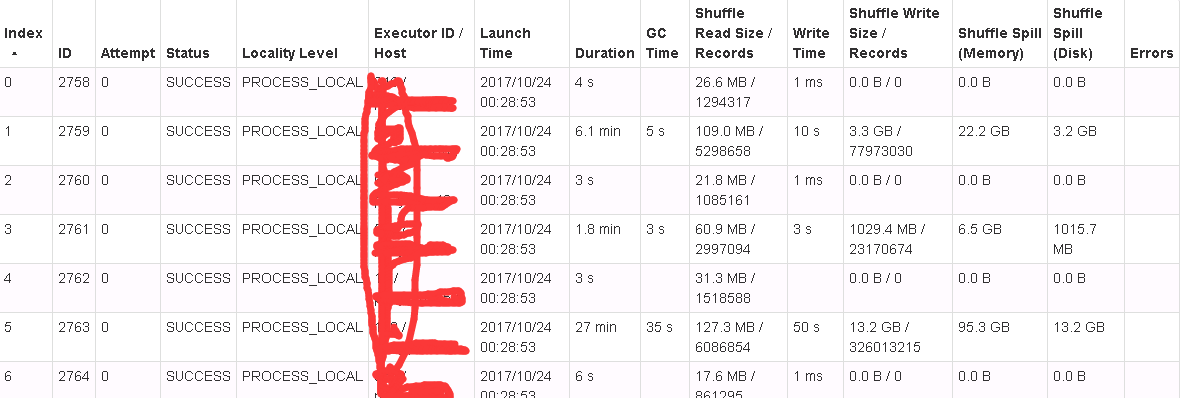
调优:
https://tech.meituan.com/spark-tuning-pro.html
提高shuffle并行度:
http://blog.csdn.net/u013939918/article/details/60956620
。