线性表
线性表的定义
- 是一种线性数据结构
- 这种数据结构是同一数据类型构成
- 除第一个结点无前驱结点,其他结点都有前驱结点,且有且只有一个直接前驱结点
- 除最后一个结点无后驱结点,其他结点都有后驱结点,且有且只有一个直接后驱结点-
顺序存储
- 用一组地址连续的存储单元依次存储线性表的数据元素
- 用一维数组表示顺序表的顺序存储
- 这个表的长度是可变的,因此数组容量要设置的大(data[MAXLEN])
datatype data[MAXLEN];
int last;
//data[MAXLEN]其中MAXLEN表示一个根据实际情况定义一个足够大的整数
//last表示表中的实际元素可能达不到MAXLEN那么多,需要last来记录当前线性表中的最后一个元素
通常把上面元素封装到一个结构体中作为线性表的类型:
typedef struct {
datatype data[MAXLEN];
int last;
//data[MAXLEN]其中MAXLEN表示一个根据实际情况定义一个足够大的整数
//last表示表中的实际元素可能达不到MAXLEN那么多,需要last来记录当前线性表中的最后一个元素
}SeqList
//类型为SeqList的顺序表
顺序表的基本运算
顺序表的空间分配及初始化- 为顺序表分配空间
- 设置last初值为-1(表示空表)
将顺序表的空间分配到堆内存区,并初始化为一个空表
SeqList *CreateSeqList(){
SeqList *Lq;//创建名为Lq的顺序表指针
Lq=new SeqList;//为顺序表分配SeqList类型的内存空间(C语言写法:Lq=(SeqList *)malloc(sizeof(SeqList)))
Lq->last=-1;//初始化表空
return Lq;//返回指向顺序表的指针Lq
}
此时顺序表中只有一个指针Lq,该顺序表未有名字
如果顺序表在主函数中定义了,则顺序表的空间就会被分配到栈内存区
void main (){
SeqList L;//L是顺序表类型的结构体变量,而非指针
InitList(&L);//调用函数InitList()初始化顺序表
}
顺序表L在栈内存区已分配空间,初始化函数只需要设置好last初值即可
void InitSeqList(SeqList *Lq){
Lq->last=-1;//初始化顺序表为空
}
顺序表的插入运算(条件:表不能满且位置不能出错误[比第一个位置还小或者最后一个位置还要大])- 在第i个位置上插入一个值为x的新元素
- 插入后原表长度为n的表长加1
- an到ai之间的所有结点依次后移,为新元素让出第i个位置
- 将新结点x插入到第i个位置。
- 修改last指针(相当于修改表长)使它指向最后一个元素位置
int InsertList (SeqList *Lq,int i, datatpye x){
int j;
if(Lq->last==MAXLEN) return (-1);//顺序表已经满了,不能插入
if(i<1||i>Lq->last+1) return (0);//插入的位置不对,该位置i不能插入
for(j=Lq->last;j>i-1;i--){//结点从最后一个位置移动到i位置
Lq->data[j+1]=Lq->data[j];
Lq->data[i-1]=x;//新元素插入
Lq->last++;//last指针始终指向最后一个元素
return (1);
}
}
在顺序表插入元素操作平均需要移动表中一半的元素,时间复杂度O(n)
顺序表的删除运算(表不能为空且删除位置不能小于第一个位置)- 将第i个元素从线性表中删除,使表长减一
- 将ai+1到an之间的结点依次向前移动
- 修改last指针使用保持指向最后一个元素
int DeleteList(SeqList *Lq,int i){
int j;
if(Lq->last==-1) return(-1);//表为空不能进行删除操作
if(i<1||i>Lq->last+1) return(0);//删除位置不正确,该位置不能删除
for(j=1;j<Lq->last;j++){
Lq->data[j-1]=Lq->Lq->data[j];
Lq->last--;
return(1);
}
}
在顺序表删除元素操作平均需要移动表中一半的元素,时间复杂度O(n)
-
按值查找- 从第一个元素a1开始依次与x进行比较,直到找到一个与x相等的数据元素,并且返回它在存储表的下标或者序号
int LocationSeqList(SeqList *Lq, datatype x){ int i=0; while(i<=Lq->last&&Lq->data[i]!=x) i++; if(i>Lq->last) return(-1); else return i;//返回的存储的位置 }
平均比较次数为(n+1)/2,时间复杂度为O(1)。
总结:
- 插入要检查插入的位置是否正确(小于第一个位置和大于最大存储容量)
- 删除要检查表是否为空,位置是否正确(小于第一个位置和大于最大存储容量)
线性表的链式存储
链式存储的特点:
- 用任意的一组存储单元存储线性表的存储元素,存储单元可以连续也可以不连续。
- 单向链表的每个结点由一个数据域和一个指针域组成
- 单向链表的存储必须从头指针开始存储
- 我们关心的是逻辑结构,对每个结点的实际地址我们都是不关心的。
头指针和头结点
头指针:
- 指向第一个结点的指针,如果链表有头结点,则是指向头结点的指针
- 它具有标志作用,标志的链表,常用它冠以链表的名字,表示某链表的第一个结点的地址放到了头指针变量上
- 无论链表是否为空,它都不能为空(若头指针为NULL表示当前链表为空表)
- 单向链表不能随机存取存储的元素,在单向链表中存取第i个元素必须从头指针开始寻找,其寻找的时间复杂度为O(n)
头结点: 它是为了操作统一和方便设立的,放在第一元素的结点之前(数据域一般无意义,可以存链表的长度)
- 有了它,对于第一个元素结点前插入删除第一个结点,其操作与其他操作结点就统一了
- 头结点不是链表必须的
单链表可以使用结构指针表示:
typedef struct linkNode{//定义结点的结构体
datatype data;
struct linkNode *next;
}LinkNode,*LinkList// 定义结点类型LinkNode,定义结点指针类型LinkList,它是指向LinkNode类型结点的指针
为了增加程序的可读性,通常将标识一个链表的头指针说明为LinkList类型的变量。
如LinkList L,当L有定义时,值要么是NULL,表示是一个空表,要么就是第一个结点的地址,即链表的头指针,将操作中用到指向某结点的指针变量说明为LinkNode*类型。
单链表的创建
在链表的头部插入结点建立线性链表- 链表和顺序表不一样,它是一种动态管理的存储结构
- 链表中的每一个结点占用的存储空间不是预先分配的
- 它的存储空间是在运行时,系统根据需求生成的
- 建立链表必须从空表开始,每读入一个数据元素则要申请一个结点,然后插入链表的头部
LinkNode *CreateLinkList()//建立链表
{
LinkNode *head,*s;
int x;
int z=1 ,n=0;
head=NULL;
printf('
建立链表');
printf('
请逐个输入整数,结束标记为-1
');
while(z){
printf(' 输入:');
scanf('%d',&x);
if(x!=-1){//输入的数据不等于-1就构造结点
s=new LinkNode;
n++;
s->data=x;//建立链表必须从空表开始,每读入一个数据元素则要申请一个结点,然后插入链表的头部
s->next=head;
head=s;
}
else z=0;
}
return head;
}
在线性表的尾部插入结点建立线性链表- 头插法读入的数据简单,但是读入的数据元素与生成的链表中元素的顺序相反的,如果希望顺序一样就需要用到尾插法
- 每次将新结点插入链表的尾部,所以需要加入一个指针p用来始终指向链表的尾结点,以便于能够将新结点插入链表的尾部
- 初始状态头指针H=NULL,尾指针p=NULL
- 按线性表中的元素的顺序依次读入数据元素,不是结束的标志就一直申请结点,将新的结点插入到p所指结点的后面,然后p指向新结点
LinkNode *CreateLinkList(){//建立链表
LinkNode *head,*s,*p;
int x;
int z=1 ,n=0;
head=NULL;
printf('
建立链表');
printf('
请逐个输入整数,结束标记为-1
');
while(z){
printf(' 输入:');
scanf('%d',&x);
if(x!=-1){//输入的数据不等于-1就构造结点
s=new LinkNode;
s->data=x;//构造新结点
s->next=NULL;
if(!head) head=s;将构造好的结点插入链表的尾部
else p->next=s;
p=s;
n++;//表长加1
}
else z=0;//输入 -1就循环结束
}
return head;返回建立好的单链表头指针
}
-
上面的算法,第一个结点的处理和其他的结点的处理方式是不一样的
-
因为第一个结点插入时,链表是空的,它没有直接前驱结点,它的地址就是整个链表的起始地址,需要放在链表的头指针变量中。
-
而其他的结点插入时时有直接前驱结点的,其地址放入其直接前驱结点的指针域中。
- 因此为了方便操作,有时会在链表的头部插入一个头结点,头结点的类型与数据结点的类型一致,标识链表的头指针变量L中存放该结点的地址,这样即使是空表,头指针也不为空。
- 头结点的加入完全为了方便计算,它的数据域是无定义的,指针域中存的是第一个结点·的地址,空表即为空。
求链表的长度
思路:
- 设计一个移动指针p和计数器n
- 初始化后,p所指结点后面若还有结点,p向后移动,计数器加1
带结点的算法:
int LenList (LinkList L){
LinkNode *p=L;
int n=0;
while(p->next){
p=p->next;
n++;
}
return n;
}
不带结点的算法:
int LenList (LinkList L){
LinkNode *p=L;
int n=0;
if(p==NULL) return 0;//空表的情况
n=1;//在非空表的情况下,p所指的是第一个结点
while(p->next){
p=p->next;
n++;
}
return n;
}
上面两个算法的时间复杂度为O(n)
-
查找-
按序号查找
思路:从链表的第一个元素的结点开始,判断当前结点是否是第i个,如果是就返回该节点的指针,否则返回继续下一个直到链表结束,没有找到就返回空。
-
LinkNode *SearchList1(LinkList L,int i){
LinkNode *p=L;
int j=0;
while(p->next!=NULL&&j<i){
p=p->next;
j++;
}
if(j==i) return p;
else return NULL;
}
-
按值查找
思路:从链表的第一个元素的结点开始,判断当前结点的值是否等于x,如果是就返回该节点的指针,否则返回继续下一个直到链表结束,没有找到就返回空。
LinkNode *SearchList1(LinkList L,int i){
LinkNode *p=L-next;
while(p!=NULL&&p->data!=x) p=p->next;
if(p->data==x) retuen p;
else return NULL;
}
上面两个算法的时间复杂度为O(n)
插入
-
后插结点:
假如p指向线性链表的某一个结点,s指向带插入的值为x的结点,将
*s插到*p的后面。
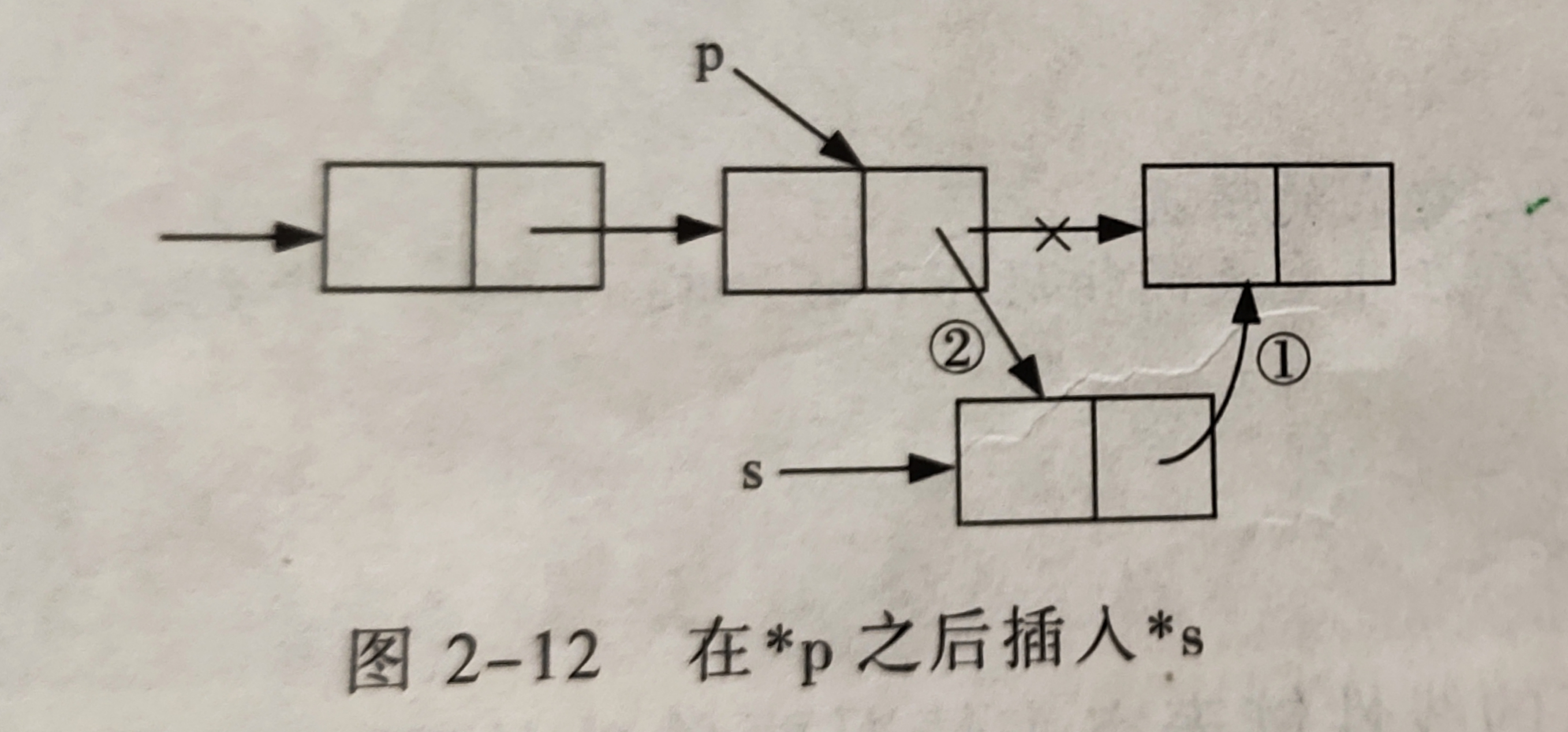
s->next=p->next;
p->next=s;
-
前插结点:
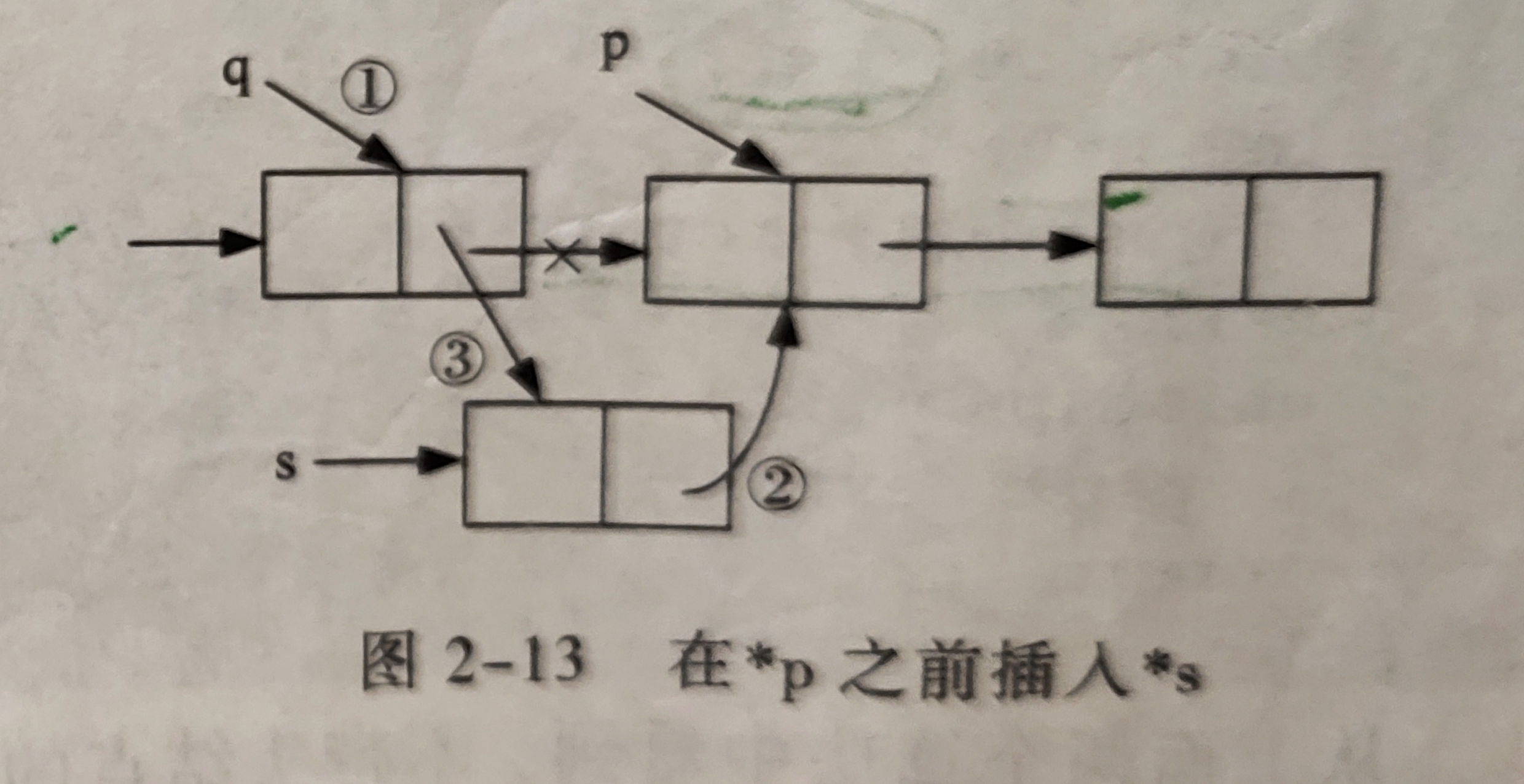
假如p指向链表中的某一个结点,s指向待插入的值为x的新结点,将
*s插入到*p的前面,与后插的不同的是:首先找到*p的前驱结点*q,然后再完成在*q之后插入*s,假如线性链表的头指针为L,算法代码如下:
q=L;
while(q->next!=p) q=q->next;//找*q的直接前驱结点
s->next=q->next;
q->next=s;
后插的操作时间复杂度为O(1),
前插由于操作要寻找*p的前驱,时间复杂度为O(n);
其实我们关心的是数据元素之间的逻辑元素,所以可以将*s插入到*p的后面,然后将p->data与s->data交换即可,这样也可以使得O(1)。
插入运算思路:
- 找到第i个结点,若不存在则结束,若存在继续下一步
- 申请一个新结点,并赋值
- 将新结点插入
void InsertList(LinkList head,int i,char x){
LinkNode *s,*p
p=head;
int j=0;
while(p!=NULL&&j<i){
j++;
p=p->next;
}
if(p!=NULL){
s=new LinkNode;
s->data=x;
s->data=p->data;
p->data=s;
n++;
}
else printf('
线性表为空或者位置超出')
}
时间复杂度为O(n)
删除
删除结点:假如p指向线性链表的某一个结点,删除*p
由图可以看出来,要实现对*p删除首先要找到*p的前驱结点*q。
q->next=p->next;
delete(p);
显然寻找*p的前驱结点时间复杂度为O(n)。
如果要删除*p的后驱结点,就可以直接完成:
s=p->next;
p->next=s->next;
delete(s);
以上操作时间复杂度O(1)。
总的算法思路:
- 如果链表为空就不能进行操作
- 查找值x的结点就必须找到它的前驱结点
- 然后将x的结点删除
LinkList DeleteList(LinkList head,char x){//删除不带头结点的单链表
LinkNode *p,*q;
if(head==Null){
printf('
链表为空!
')
return head;
}
if(head->next==NULL){
if(head->next!=x){//只有一个结点,并且不是待删结点
printf('未找到待删除的结点');
return head;
}
else {
delete head;//只有一个结点并且是待删结点,释放删除的空间
return NULL;
}
}
q=head;
p=head->next;
while(p!=NULL&&p->data!=x){
q=p;
p=p->next;
}
if(p!=NULL){
q->next=p->next;
delete(p);
n--;
printf(' %c已经被删除',x);
}
else printf('未找到待删除的结点');
}
时间复杂度为O(n)
总结- 在线性链表中插入、删除一个结点得找出它的前驱结点
- 线性链表不具有按序号随机查找访问的特点、要实现这些操作必须得从头指针开始一个个的进行。
循环链表
-
特点:- 将线性单向链表的尾指针域指向头结点。
- 整个链表头尾结点相连形成一个环,就构成一个单循环链表
-
操作:- 循环链表的操作与非循环操作基本相同
- 差别在于算法中的循环条件不是判断指针是否为空(p->next==NULL)
- 应该判断指针是否为头指针:(p->next==head)
-
在循环链表中设尾指针可以简化某些操作- 线性链表只能从头指针开始遍历整个链表,对于循环链表则可以在表中任意的结点开始遍历链表
- 有时候一些操作需要是在表头表尾进行,这时可以改变一下链表的标识方法,不用头指针而是用一个指向尾结点的指针T来标识,可以让操作效率得以提高。
- 当知道循环链表的尾指针T后,在其另一端的头指针是T->next->next(表中带头结点),仅仅改变两个指针值即可,其运算时间复杂度为O(1)。
双向链表
-
单链表的缺点:
- 单链表只能顺的指针往后寻找其他结点。若要寻找结点的前驱,则需要从表头指针出发
- 为了克服以上的缺点于是就有了双向链表
-
双向链表组成:
- 双向链表有一个数据域和两个指针域组成
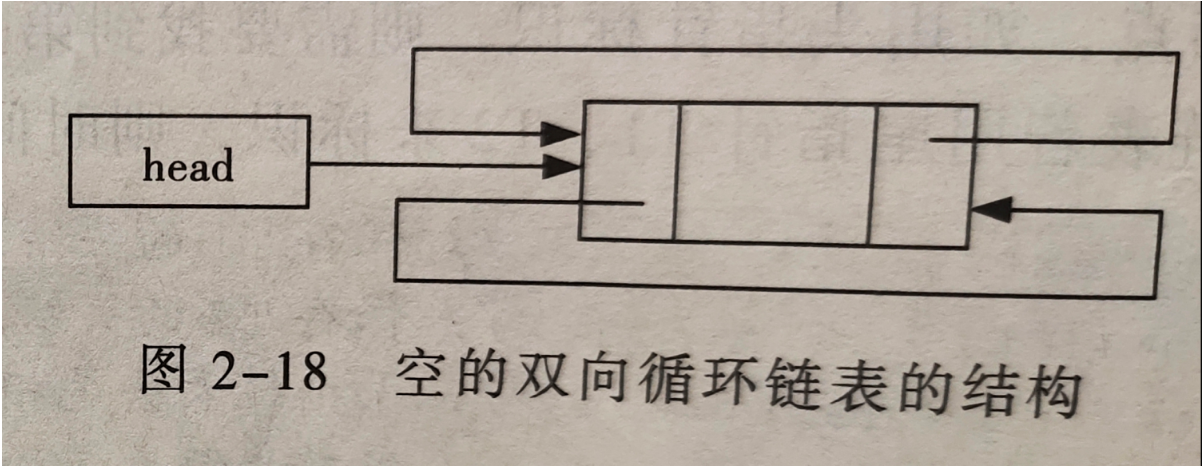
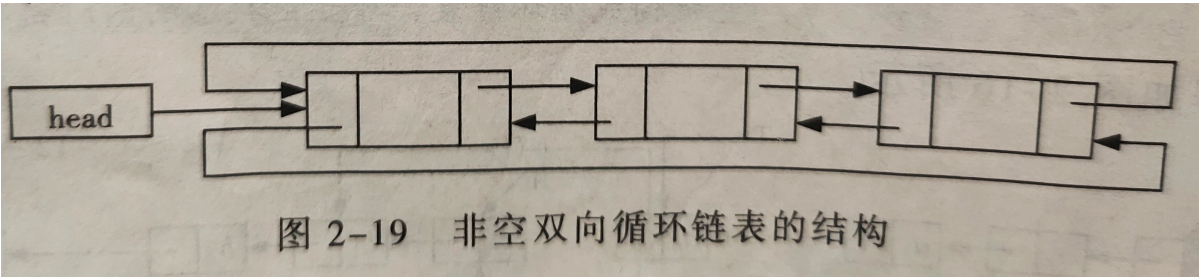

- 双向链表的描述:
struct cdlist{
datatype data;//结点的数据域
struct cdlist *front;//指向先前结点的指针
struct cdlist *rear;//指向后继结点的指针
};
-
双向链表的操作:
-
删除结点:
p->front->rear=p->rear; p->rear->front=p->front; delete p;- 插入结点:
-
p->front=q;
p->rear=q->rear;
q->rear->front=p;
q->rear=p;