一:问题的引出与复现
在一个风和日丽的工作日,公司运营发现系统的任务数据没有推送执行,整个流程因此停住了。我立马远程登陆服务器,查看日志,好家伙,系统在疯狂的打印相同的一段日志:c.d.d.j.i.e.LeaderElectionService [traceId=] - Elastic job: leader node is electing, waiting for 100 ms at server '192.168.0.6'
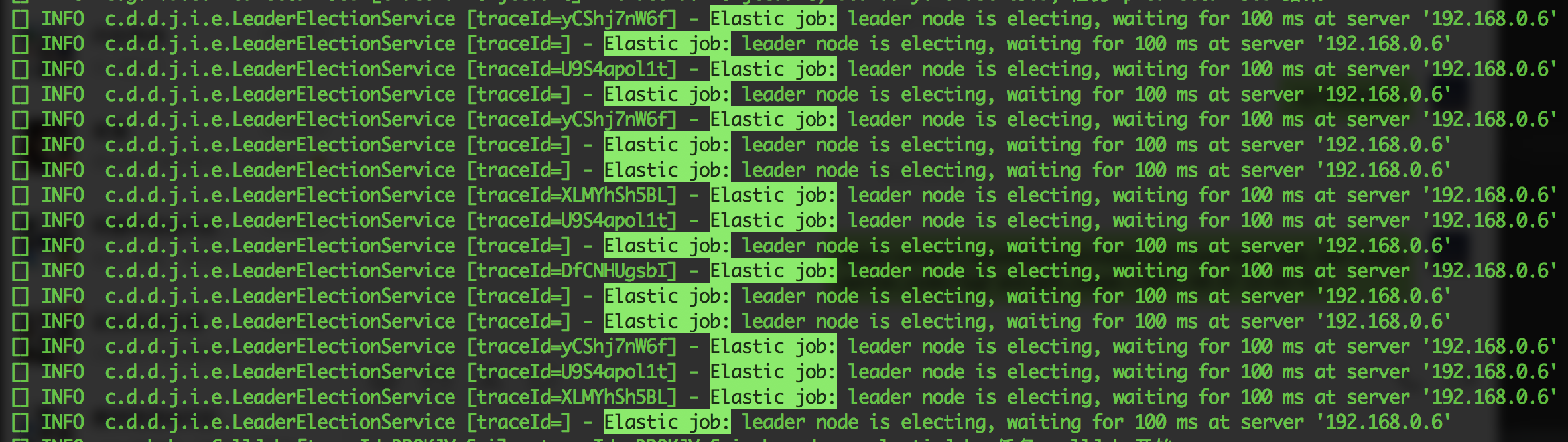
第一反应就是基建出问题了,无奈和运营商量,准备重启项目服务,重启后,问题立刻解决,业务也正常运行了。
有句话说得好,你觉得可能再次出现的问题,一定会再次出现。忘记了多少天后(开发初期,业务很紧张,这个问题没有时间及时去处理),又有别的定时任务也不执行了,出现的问题也是一模一样。
同一个问题在生产出现了两次,已经必须要去解决了,首先去网上搜索下,也有网友遇到过这种问题,但是下面的回复却是说:”Elastic job正在选举主节点,等它选完就正常了。“
先说下当时生产正在用的就是 com.dangdang.elastic-job-core,是当当网开源的一个分布式调度的组件,在上家公司三个机器节点做的集群用了很长时间也重来没有遇到这个问题,
当时就纳闷了,难道是有什么配置设置的不对,导致它无法正常选主吗?
然后花了点时间,自己搭了一个项目,准备去仔细分析debug下它的源码,在这儿就发现,每次远程debug的时候,一两分钟后,项目日志就会复现 c.d.d.j.i.e.LeaderElectionService [traceId=] - Elastic job: leader node is electing, waiting for 100 ms at server '192.168.0.6' 。
因此大胆猜测,因为debug导致Elastic job和注册中心心跳链接超时了,而生产环境的系统也可能因为网络抖动或者IO的压力,导致这个问题。
二:ElasticJob简单使用
2020年6月,经过Apache ShardingSphere社区投票,接纳ElasticJob为其子项目。目前ElasticJob的四个子项目已经正式迁入Apache仓库。
http://shardingsphere.apache.org/elasticjob/index_zh.html 最新的3.x版本在开源社区的帮助下,相比之前已经有了很大的优化,当然经过测试,也完美解决了选主的问题。
大致翻阅一下官方文档,下面就准备接入测试下。
引入maven依赖
<dependency> <groupId>org.apache.shardingsphere.elasticjob</groupId> <artifactId>elasticjob-lite-core</artifactId> <version>${latest.release.version}</version> </dependency>
# Spring 命名空间,可以与 Spring 容器配合使用
<dependency>
<groupId>org.apache.shardingsphere.elasticjob</groupId>
<artifactId>elasticjob-lite-spring-namespace</artifactId>
<version>3.0.0-beta</version>
</dependency>
# zk的版本要求3.6.0 以上
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.6.2</version>
</dependency>
elasticjob.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:elasticjob="http://shardingsphere.apache.org/schema/elasticjob" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://shardingsphere.apache.org/schema/elasticjob http://shardingsphere.apache.org/schema/elasticjob/elasticjob.xsd "> <elasticjob:zookeeper id="regCenter2" server-lists="${zkHost}" namespace="${elastic.job.namespace}" base-sleep-time-milliseconds="${elastic.job.baseSleepTimeMilliseconds}" max-sleep-time-milliseconds="${elastic.job.maxSleepTimeMilliseconds}" max-retries="${elastic.job.maxRetries}"/>
<elasticjob:job id="apacheTestJob" job-ref="apacheTestJob" registry-center-ref="regCenter2" sharding-total-count="${apacheTestJob.shardingTotalCount}" cron="${apacheTestJob.cron}" failover="${apacheTestJob.failover}" description="${apacheTestJob.description}" disabled="${apacheTestJob.disabled}" overwrite="${apacheTestJob.overwrite}" job-executor-service-handler-type="SINGLE_THREAD"/> <bean id="apacheTestJob" class="com.yxy.nova.elastic.job.ApacheTestJob" /> </beans>
可配置属性:
| 属性名 | 是否必填 |
|---|---|
| id | 是 |
| class | 否 |
| job-ref | 否 |
| registry-center-ref | 是 |
| tracing-ref | 否 |
| cron | 是 |
| sharding-total-count | 是 |
| sharding-item-parameters | 否 |
| job-parameter | 否 |
| monitor-execution | 否 |
| failover | 否 |
| misfire | 否 |
| max-time-diff-seconds | 否 |
| reconcile-interval-minutes | 否 |
| job-sharding-strategy-type | 否 |
| job-executor-service-handler-type | 否 |
| job-error-handler-type | 否 |
| job-listener-types | 否 |
| description | 否 |
| props | 否 |
| disabled | 否 |
| overwrite | 否 |
1:cron 定时执行的表达式
2:sharding-total-count 总的分片数
3:job-sharding-strategy-type 分片策略
可以看它内置的三种策略,说明比较详细,默认的是 平均分片策略。
下面再说说如何自定义分片策略,ElasticJob加载分片策略使用的是JDK的spi (Service Provider Interface)加载的。
要使用SPI比较简单,只需要按照以下几个步骤操作即可:
- 在META-INF/services目录下创建一个以"接口全限定名"为命名的文件,内容为实现类的全限定名
- 接口实现类所在的jar包在classpath下
- 主程序通过java.util.ServiceLoader动态状态实现模块,它通过扫描META-INF/services目录下的配置文件找到实现类的全限定名,把类加载到JVM
- SPI的实现类必须带一个无参构造方法
首先自定义一个策略类MyJobShardingStrategy,实现 JobShardingStrategy
package com.nova.elastic.job; import org.apache.shardingsphere.elasticjob.infra.handler.sharding.JobInstance; import org.apache.shardingsphere.elasticjob.infra.handler.sharding.JobShardingStrategy; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; public class MyJobShardingStrategy implements JobShardingStrategy { /** * Sharding job. * * @param jobInstances all job instances which participate in sharding * @param jobName job name * @param shardingTotalCount sharding total count * @return sharding result */ @Override public Map<JobInstance, List<Integer>> sharding(List<JobInstance> jobInstances, String jobName, int shardingTotalCount) { Map<JobInstance, List<Integer>> result = new HashMap<>(); List<Integer> shardingItems = new ArrayList<>(shardingTotalCount + 1); for (int i=0; i<shardingTotalCount; i++) { shardingItems.add(i); } result.put(jobInstances.get(0), shardingItems); return result; } /** * Get type. * * @return type */ @Override public String getType() { return "MY_TEST"; } }
然后我们只需要在自己项目的resources下,建一个META-INF/services的文件夹,再创建以 a接口的全限定名(org.apache.shardingsphere.elasticjob.infra.handler.sharding.JobShardingStrategy),内容则为”com.nova.elastic.job.MyJobShardingStrategy“

这样ElasticJob的主程序通过java.util.ServiceLoader就可以把我们自定义的策略类加载好。
最后就可以在xml中,job-sharding-strategy-type="MY_TEST", 配置使用自定义的分片策略。
三:存在的问题
我模拟了 1 台作业服务器且分片总数为2,则分片结果为:1=[0,1],然后我再自己的调度任务中打印了 shardingContext,
2021-06-08 16:33:35.029 [] INFO c.y.n.e.j.ApacheTestJob [traceId=] - ShardingContext(jobName=apacheTestJob-no-repeat, taskId=apacheTestJob-no-repeat@-@0,1@-@READY@-@172.16.0.4@-@23146, shardingTotalCount=2, jobParameter=, shardingItem=0, shardingParameter=null) 2021-06-08 16:33:35.029 [] INFO c.y.n.e.j.ApacheTestJob [traceId=] - ShardingContext(jobName=apacheTestJob-no-repeat, taskId=apacheTestJob-no-repeat@-@0,1@-@READY@-@172.16.0.4@-@23146, shardingTotalCount=2, jobParameter=, shardingItem=1, shardingParameter=null)
可以看到,在这种配置条件下,ApacheTestJob 是同时执行两次,只有 shardingItem 有区别,那么这样就会存在一个问题,我job的代码逻辑就会执行两次,只不过每次的shardingItem不同而已。
如果业务逻辑需要查询数据库,那么这样就select了多次,在数据库有瓶颈的系统下,效率肯定低。
反之,如果在这个配置下,调度任务只被调度一次,但是 ShardingContext 可以保存一个 shardingItem的列表,这样就可以解决多次查询数据库的问题。
这也是用了这两种ElasticJob后,感受到的最大的区别。
不知道有没有正在使用 shardingsphere.elasticjob的小伙伴,你们的系统是如何使用的?有没有存在相同的疑惑?又是如何解决这个问题的?