1.概述
人在获取图像时,并不是像计算机逐个像素去读,一般是扫一眼物体,大致能得到需要的信息,如形状,颜色,特征。怎么让机器也有这项能力呢,稀疏编码来了。
定义:
稀疏自编码器(Sparse Autoencoder)可以自动从无标注数据中学习特征,可以给出比原始数据更好的特征描述。在实际运用时可以用稀疏编码器发现的特征取代原始数据,这样往往能带来更好的结果。
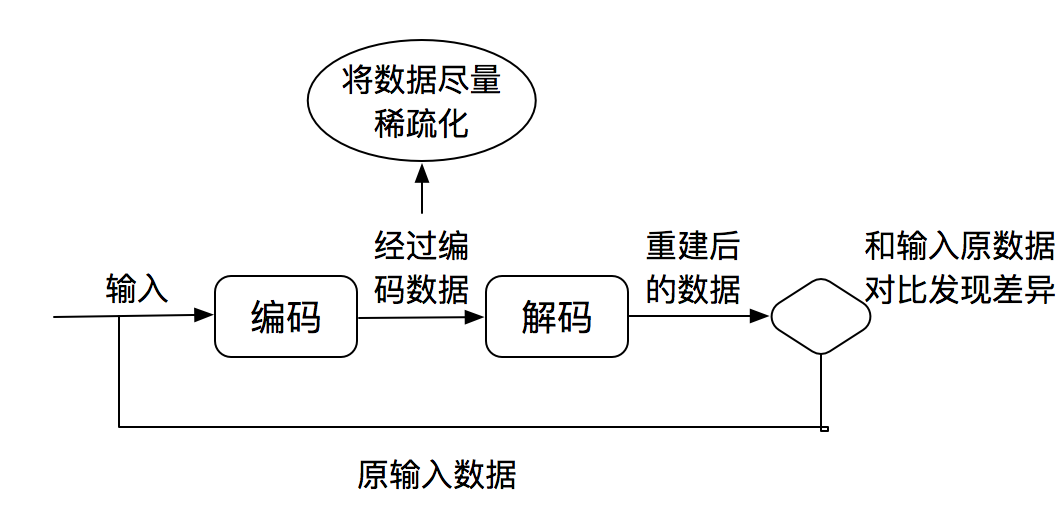
上图就是稀疏编码的一半流程,清晰的说明了稀疏编码的过程。
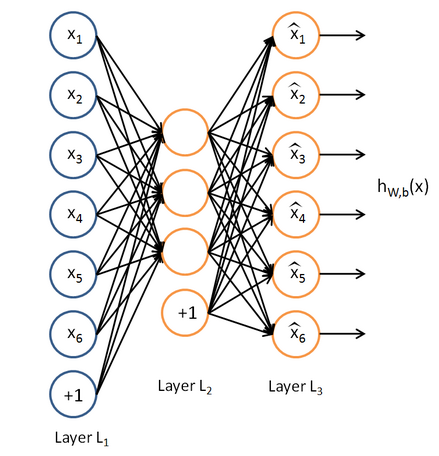
自编码器要求输出尽可能等于输入,并且它的隐藏层必须满足一定的稀疏性,即隐藏层不能携带太多信息。所以隐藏层对输入进行了压缩,并在输出层中解压缩。整个过程肯定会丢失信息,但训练能够使丢失的信息尽量少。通过引入惩罚机制和BP算法解决最小化信息丢失问题。
2.代码实现
#coding=utf-8
'''
Created on 2016年12月3日
@author: chunsoft
'''
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 导入 MNIST 数据
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/tmp/data/", one_hot=True)
# 参数
learning_rate = 0.01 #学习速率
training_epochs = 20 #训练批次
batch_size = 256 #随机选择训练数据大小
display_step = 1 #展示步骤
examples_to_show = 10 #显示示例图片数量
# 网络参数
#我这里采用了三层编码,实际针对mnist数据,隐层两层,分别为256,128效果最好
n_hidden_1 = 512 #第一隐层神经元数量
n_hidden_2 = 256 #第二
n_hidden_3 = 128 #第三
n_input = 784 #输入
#tf Graph输入
X = tf.placeholder("float", [None,n_input])
#权重初始化
weights = {
'encoder_h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'encoder_h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'encoder_h3': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_3])),
'decoder_h1': tf.Variable(tf.random_normal([n_hidden_3, n_hidden_2])),
'decoder_h2': tf.Variable(tf.random_normal([n_hidden_2, n_hidden_1])),
'decoder_h3': tf.Variable(tf.random_normal([n_hidden_1, n_input])),
}
#偏置值初始化
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'encoder_b3': tf.Variable(tf.random_normal([n_hidden_3])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b2': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b3': tf.Variable(tf.random_normal([n_input])),
}
# 开始编码
def encoder(x):
#sigmoid激活函数,layer = x*weights['encoder_h1']+biases['encoder_b1']
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['encoder_h3']),
biases['encoder_b3']))
return layer_3
# 开始解码
def decoder(x):
#sigmoid激活函数,layer = x*weights['decoder_h1']+biases['decoder_b1']
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['decoder_h3']),
biases['decoder_b3']))
return layer_3
# 构造模型
encoder_op = encoder(X)
encoder_result = encoder_op
decoder_op = decoder(encoder_op)
#预测
y_pred = decoder_op
#实际输入数据当作标签
y_true = X
# 定义代价函数和优化器,最小化平方误差,这里可以根据实际修改误差模型
cost = tf.reduce_mean(tf.pow(y_true-y_pred, 2))
optimizer = tf.train.RMSPropOptimizer(learning_rate).minimize(cost)
# 初始化变量
init = tf.initialize_all_variables();
# 运行Graph
with tf.Session() as sess:
sess.run(init)
#总的batch
total_batch = int(mnist.train.num_examples/batch_size)
# 开始训练
for epoch in range(training_epochs):
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, c = sess.run([optimizer, cost], feed_dict={X: batch_xs})
# 展示每次训练结果
if epoch % display_step == 0:
print("Epoch:", '%04d' % (epoch+1),
"cost=", "{:.9f}".format(c))
print("Optimization Finished!")
# Applying encode and decode over test set
#显示编码结果和解码后结果
encodes = sess.run(
encoder_result, feed_dict={X: mnist.test.images[:examples_to_show]})
encode_decode = sess.run(
y_pred, feed_dict={X: mnist.test.images[:examples_to_show]})
# 对比原始图片重建图片
f, a = plt.subplots(2, 10, figsize=(10, 2))
for i in range(examples_to_show):
a[0][i].imshow(np.reshape(mnist.test.images[i], (28, 28)))
a[1][i].imshow(np.reshape(encode_decode[i], (28, 28)))
f.show()
plt.draw()
plt.waitforbuttonpress()