resrest库是 python实现的简单的应用的库,可以做爬虫使用
1、例程
import requests response = requests.get("https://baidu.com") print(response) # <Response [200]> print(type(response)) # <class 'requests.models.Response'> print(response.status_code) # 200
使用 resquests.get()发送get()请求,得到一个类的对象 response
2、各种请求方式
# 发送一个 HTTP POST 请求: response = requests.post("http://httpbin.org/post",data = {'key':'value'}) response = requests.delete('http://httpbin.org/delete') # 发送一个 HTTP delete 请求: response = requests.head('http://httpbin.org/get') # 发送一个 HTTP head 请求: response = requests.options('http://httpbin.org/get') # 发送一个 HTTP options 请求:
3、基本 GET请求
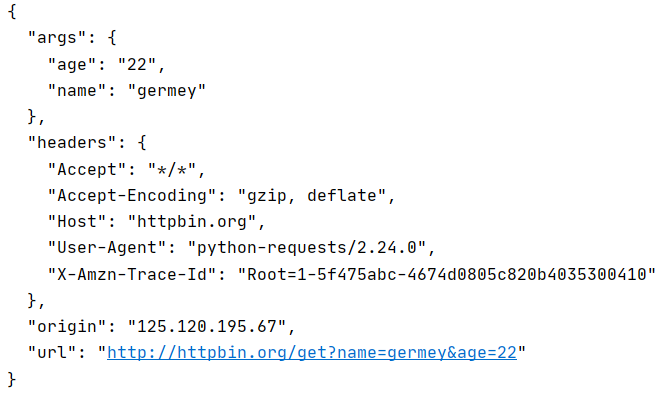
import requests response = requests.get("http://httpbin.org/get?name=germey&age=22") print(response.text)
import requests data = { 'name': 'germey', 'age': 22 } response = requests.get("http://httpbin.org/get", params=data) print(response.text)
两种方法都可以,添加 data 或者写在url上
resquesets.get(url) 得到的结果 response.text 为文本文件
3.1、获取二进制数据,可以爬取图片、视频等
import requests response = requests.get("https://github.com/favicon.ico") with open('favicon.ico', 'wb') as f: f.write(response.content) f.close()
将爬取到的二进制数据,保存在 favicon.ico文件中,resquests.content 为获取到的内容
3.2、添加 headers标签
和 urllib.urlopen一样,可以添加一个 headers参数
import requests headers = { 'User-Agent' :'Mozilla/5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 70.0.3538.102Safari / 537.36Edge / 18.18362' } response = requests.get("https://www.zhihu.com/explore", headers=headers) print(response.text)
4、response的属性
import requests response = requests.get('http://www.baidu.com') print(type(response.status_code), response.status_code) print(type(response.headers), response.headers) print(type(response.cookies), response.cookies) print(type(response.url), response.url) print(type(response.history), response.history)
5、上传文件
import requests files = {'file': open('favicon.ico', 'rb')} response = requests.post("http://httpbin.org/post", files=files) print(response.text)
上传图片到 url网址上,然后接收端下载文件即可,用的是 post请求
6、获取cookie
import requests response = requests.get("https://www.baidu.com") print(response.cookies) for key, value in response.cookies.items(): print(key + '=' + value)
cookie是一个登录状态,下载之后,利用python访问的时候可以添加 cookie登录,不然有些网址会提示没有权限
模拟登录
import requests s = requests.Session() s.get('http://httpbin.org/cookies/set/number/123456789') response = s.get('http://httpbin.org/cookies') print(response.text)
建立一个 Session对象,保证添加 cookies的浏览器和再次访问的浏览器是同一个浏览器
就是说,如果是普通的方法,可能是模拟一个浏览器上添加了 cookie,再模拟另一个浏览器读取,的不要想要的验证效果
get( url/ cookie/set/xxx) 是添加 cookie 的方法 然后再 s.get 读取结果为 response
7、证书验证
一些网站没有官方的证书认证,浏览器访问会提示是否继续访问,但是python爬虫不会提示,访问会直接报错,可以添加参数 verify =False,屏蔽证书
import requests from requests.packages import urllib3 urllib3.disable_warnings() response = requests.get('https://www.12306.cn', verify=False) print(response.status_code)
在 requests.get()方法中加入 verify =False即可,不过这样虽然可以运行,但是会有 warning 提示
也可以设置 uillib3.disable_warning() 关闭 warning提示
8、认证设置
比如说访问一些 htp网址或者其他需要账号密码登录,就需要直接输入
import requests r = requests.get('http://120.27.34.24:9001', auth=('user', '123')) print(r.status_code)
9、异常处理
import requests from requests.exceptions import ReadTimeout, ConnectionError, RequestException try: response = requests.get("http://httpbin.org/get", timeout = 0.5) print(response.status_code) except ReadTimeout: print('Timeout') except ConnectionError: print('Connection error') except RequestException: print('Error')
根据报错信息来判断是什么报错,然后添加 try expect 来处理异常