面向对象编程的过程中,经常需要创建对象,如果频繁创建对象特别是使用容器持有对象,那么内存的占用就会越来越高,这对于大型项目来说有时候是致命的。比如对于一篇文档,文档中有文字,而文字是有字体信息、格式信息、颜色信息、位置信息等,显而易见,在面向对象编程中,每个文字被视作一个来处理,那么一篇文档中如果有几万个字,难道要创建几万个对象么?几十万个文字,就要创建几十万个对象么?这显然是极不合理的,实际上,文字处理器中经常用到我今天介绍的设计模式----享元模式, 在池化技术中享元模式得到了普遍应用。
1.享元模式
享元模式(Flyweight Pattern),运用共享技术有效地支持大量细粒度的对象。 ----《大话设计模式》
这里需要理解两个方面:
- 怎么实现共享技术
- 什么是细粒度对象
实现共享技术,就是什么时候创建对象、如何存储对象、怎样获取对象这一套策略。
细粒度对象,就像上文所举的文字例子,文字包含文字符号、位置等信息,这些信息中,注意到,文字符号是不可变的,就拿字母“A”来说,是不变的,但是位置是可变的,文章各个位置都有可能存在“A”这个字母,我们把位置信息抽取出来,称之为外部状态,剩下的部分,只有一个不变的符号信息,留在对象内部,称之为内部状态。这样把部分信息剥离只留下必要信息的对象,就叫做细粒度的对象。
外部状态通常作为方法参数的形式传入“A”对象, 内部状态则作为“A”对象的成员变量。而“A”对象则可以被共享和复用,称之为享元对象。享元对象需要满足不可变性(immutability),即其内部状态不可被修改。
总之,享元模式是为了减少内存开销而存在的,所以当编程过程中,如果遇到需要大量对象或者需要大量内存空间的时候,就可以考虑能不能使用享元模式。其类图为:
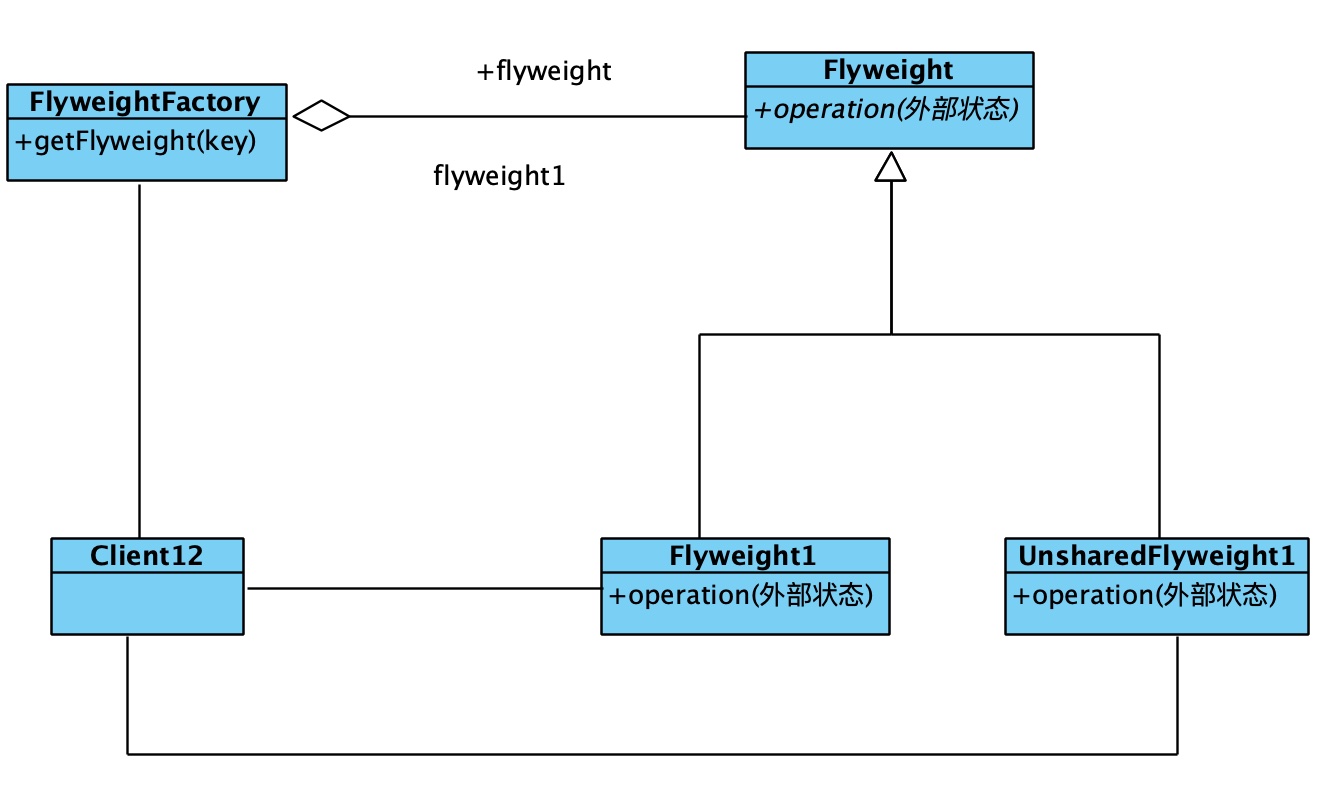
Flyweight就是上文提到的“细粒度对象”, 是需要被创建、存储和共享的, 它的实现类可以根据业务实际需求定义, UnsharedFlyweight1这里是不希望被共享的对象。FlyweightFactory是享元对象的工厂,客户端调用getFlyweight(key)获取Flyweight对象。注意到operation(外部状态)方法, 仅通过该方法将外部状态信息作为参数传入对象,比如字符“A”的位置信息。
2.代码实现
下面通过一个简易的字母处理器代码Demo来实现享元模式, 假设该处理器只支持英文26个小写字母。
定义了LowerCase类表示小写字母。使用WeakHashMap是为了最大程度上减少内存开销,因为其内持有的对象是弱引用,所以即使你没有特意处理,WeakhashMap中的对象也有可能被GC(垃圾回收)掉。WeakHashMap也是为缓存应用而生的, 这样有我们要的对象时给我们,没有时创建,我们用完之后,GC有可能会回收内存资源,所以在一定程度上可以优化内存损耗。
getCase()用来获取对象。
/** * 字母类,作为flyweight * 提供静态方法获取字母对象 */ class LowerCase { /** 内部状态: 字母名称 */ private final String name; /** 用缓存来储存共享对象 */ private static final WeakHashMap<String, LowerCase> CACHE = new WeakHashMap<>(); /** 只允许intern方法创建对象*/ private LowerCase(String name) { this.name = name; } /**静态工厂方法: 获取共享对象*/ public static LowerCase getCase(String key){ //由于是共享的,这里保证多线程下不会重复创建对象 synchronized (CACHE) { //如果存在key对应的对象,返回该对象;如果不存在,则创建一个对象 return CACHE.computeIfAbsent(key, LowerCase::new); } } /** 用于测试CACHE中创建了多少对象*/ public static int totalCount() { //共享对象可增删,使用同步代码块保证同时只有一个线程可以访问缓存 synchronized (CACHE) { return CACHE.size(); } } public String toString() { return name; } }
文档类, 作为载体,字母被打印在上面,注意到printCase(String charactor, int positionX, int postionY)方法,charactor是缓存中所需LowerCase的key, positionX,positionY是表示该字符的坐标位置的外部信息,外部信息通畅就像这样通过方法传递的。
/** * 文档类,打印字母的版面 */ class Document { public static void printCase(String charactor, int positionX, int positionY) { LowerCase lowerCase = LowerCase.getCase(charactor); Printer.print(lowerCase, positionX, positionY); } }
Printer模拟打印程序,拿到具体的字符对象LowerCase以及外部信息,对这些参数做整合处理。
/** * 打印程序,用来打印文字 */ class Printer { public static void print(LowerCase lc, int x, int y) { System.out.printf("小写字母:%s, 位置(x=%d, y=%d) ", lc.toString(),x,y); } }
客户端调用,每一次随机从a,b,c,d,e,f这六个小写字母中取一个字母打印在随机的位置上,这个操作进行1000次,最后用LowerCase.totalCount()来查看缓存中有多少对象。
public class FlyWeightDemo1 { static final String[] keys = {"a", "b", "c", "d", "e", "f"}; static Random rand = new Random(47); static void test(int circle) { for (int i = 0; i < circle; i++) { int index = rand.nextInt(keys.length); int x = rand.nextInt(1000); int y = rand.nextInt(1000); Document.printCase(keys[index], x, y); } } public static void main(String[] args) { //打印1000个字母 test(1000); //查看缓存中目前一共有多少对象 System.out.printf("缓存中共有%d个字母对象",LowerCase.totalCount()); } }
输出结果,输出了1000个字母,可以看到实际上缓存只保存了6个对象
小写字母:b, 位置(x=359, y=654) 小写字母:e, 位置(x=187, y=144) 小写字母:e, 位置(x=549, y=384) ...... ...... ...... 小写字母:b, 位置(x=766, y=207) 小写字母:b, 位置(x=558, y=462) 缓存中共有6个字母对象
3.总结
优化内存损耗是开发应用过程中经常需要考虑的问题,只要遇见需要大量创建类似的对象或者需要大量内存的时候,就可以考虑这个对象能否把“外部状态”剥离出来从而由剩下的部分形成所谓“细粒度对象”。在本文的代码示例中,采用WeakHashMap,应用享元模式,实现了一个简化版的“字母池”, 每次需要创建一个字母,从缓存中去取,从而大大节省了内存空间。在实际开发中,大可不必非得按照“标准”UML类图,创建一个Flyweight,一个FlyweightFactory,享元模式的核心是创建、储存和获取对象,其目的是节省内存空间,只要按照这种思路对代码进行设计即可。
此外,由于享元模式的享元对象,是需要被共享的,当创建享元对象时,就需要考虑到多线程并发的情况。一般分为两种情况:
- 一种是储存享元对象的容器大小是有限的,这样可以提前创建好对象,多线程去获取对象就不存在抢占问题了。
- 另一种是运行时多线程可能会创建享元对象(如本文代码),那么就需要考虑线程安全问题,一般有两种方式:
-
-
- 采用sychronized同步线程,任何一个时刻只允许一个线程访问缓存资源(如本文代码)
- 享元对象满足相等性(equality)的前提下,可以允许多线程同时创建对象和访问
-