分片用户管理
不通过mongos连接分片
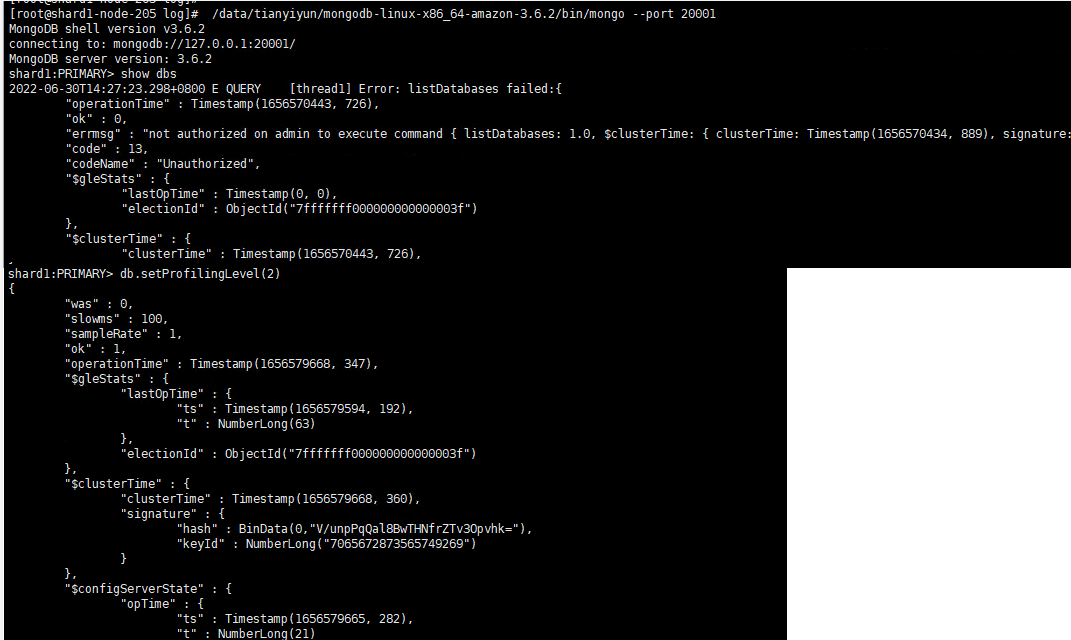
通过mongos创建的用户无法直接登录shard,必须单独给shard创建自己的用户
用户创建规则

连接分片
/data/tianyiyun/mongodb-linux-x86_64-amazon-3.6.2/bin/mongo --port 20001
集群mongos用户不能用来认证单个shard节点,必须要在shard节点单独建立用户
use admin
创建超级用户
db.createUser({user:"test",pwd:"abc123",roles:[{role:"userAdminAnyDatabase",db:"admin"}]})
db.auth("test","abc123")
db.setProfilingLevel(2) 是打开所有操作profile可以实验用,或者短时打开.但是一定要及时关闭
show collections 会看到多了一个collection 叫system.profile
然后db.system.profile.find().pretty()
Log: 用db.setLogLevel(1,command)可以看到所有的操作,每个操作的用时都会记录下来
记得定位后用db.setLogLevel(0)改回去
创建普通用户
MongoDB的账号跟随DB创建举例:
#以超级用户登陆之后,执行以下mongodb shell命令
use admin
db.createUser({'user':'test', pwd:'test', roles:['readWrite', 'dbAdmin']})
为什么副本实例、配置实例也要单独创建账号密码
因为副本实例配置实例设置的账号密码只是自己的账号密码,存储在本地.而从mongos设置的集群的账号密码存储在config server.如果直接从mongos上设置账号密码,那么副本实例配置实例将会因为没有账号而无法做任何运维操作
用户权限管理
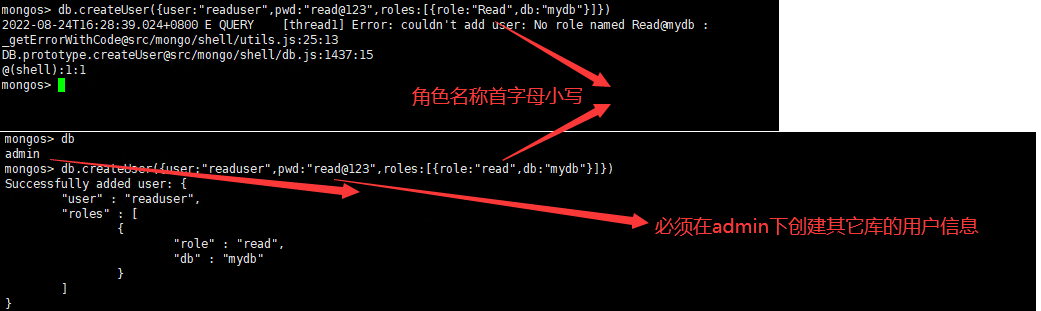
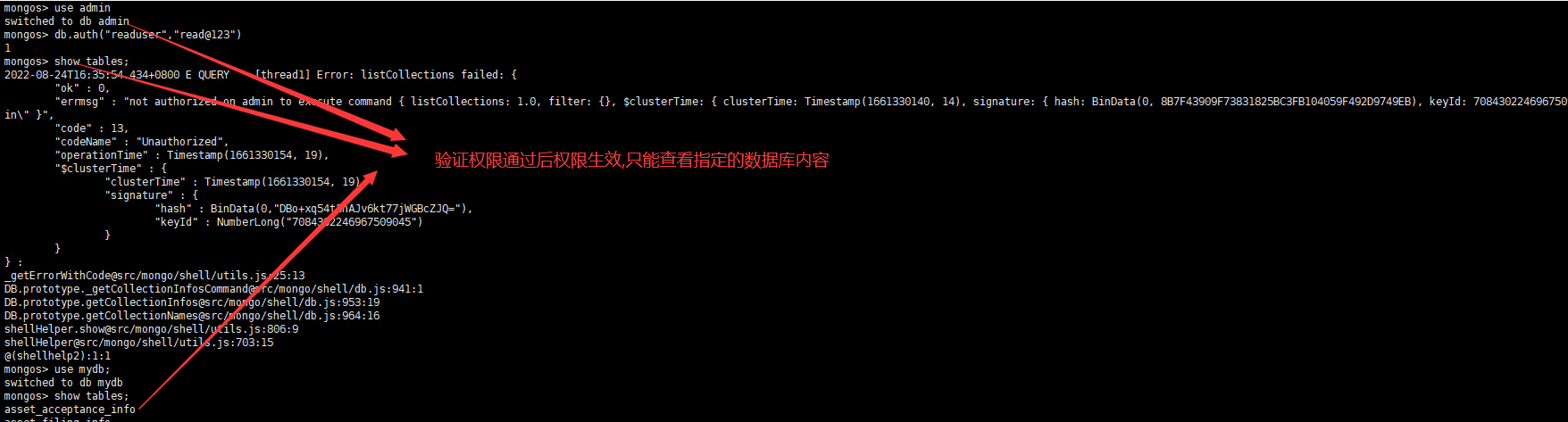
1.创建只能对某个数据库只有查询权限的用户
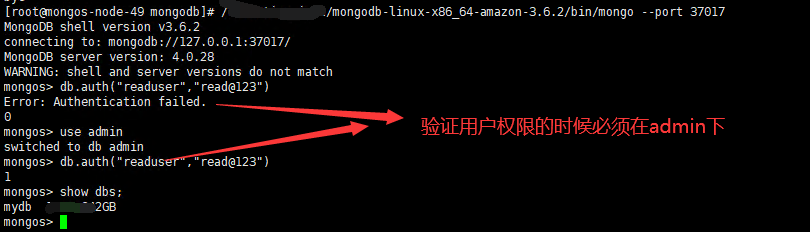
2.用户登录验证


3.修改用户密码
db.updateUser("admin",{pwd:"admin"})
4.创建的用户如果是dbowner那么可以直接通过用户名连接对应的db,如果创建的是普通用户,那么连接数据库的时候必须先连admin,然后通过admin验证权限后自动获取对应权限数据库.不能直接连接对应的数据库


创建数据库只读用户 use admin db.auth("admin","admin") db.createUser({user:"readuser",pwd:"read@123",roles:[{role:"read",db:"mydb"}]}) db.auth("readuser","read@123") use mydb db.table.findOne() db.auth("admin", "admin") 更新权限命令 db.grantRolesToUser("root", [{ role: "root", db: "admin" }]) 修改密码命令 db.updateUser("admin",{pwd:"admin"})
运行状态查看管理
mongotop命令
./mongotop 30 --uri='mongodb://admin:admin@192.168.0.107:2001/?authSource=admin'
mongotop用来跟踪MongoDB的实例,提供每个集合的统计数据。默认情况下,mongotop每一秒刷新一次
mongotop不能通过mongos路由节点上执行查询,必须要到shard节点上进行执行
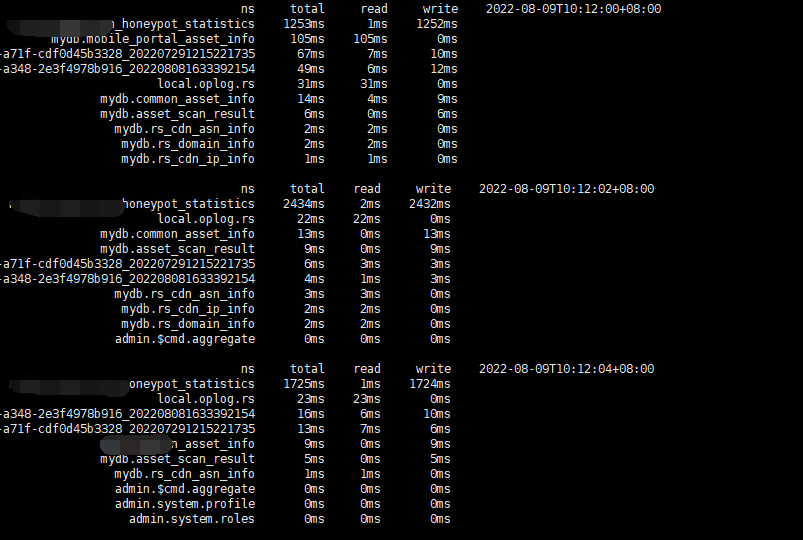
ns:数据库命名空间,后者结合了数据库名称和集合。
db:数据库的名称。名为 . 的数据库针对全局锁定,而非特定数据库。
total:mongod在这个命令空间上花费的总时间。
read:在这个命令空间上mongod执行读操作花费的时间。
write:在这个命名空间上mongod进行写操作花费的时间。
mongostat命令
可以在mongos节点上查询集群的运行信息
./mongostat --uri=mongodb://admin:admin@192.168.0.49:37017,192.168.0.103:37017,192.168.0.67:37017,192.168.0.174:37017/admin
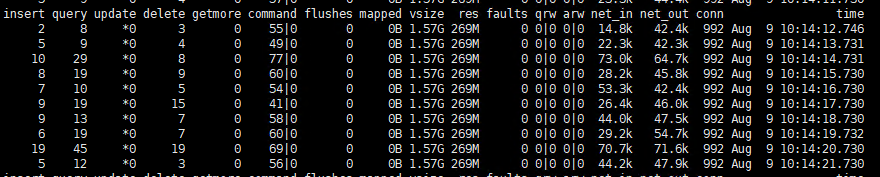
insert/s : 官方解释是每秒插入数据库的对象数量,如果是slave,则数值前有*,则表示复制集操作 query/s : 每秒的查询操作次数 update/s : 每秒的更新操作次数 delete/s : 每秒的删除操作次数 getmore/s: 每秒查询cursor(游标)时的getmore操作数 command: 每秒执行的命令数,在主从系统中会显示两个值(例如 3|0),分表代表 本地|复制 命令 注: 一秒内执行的命令数比如批量插入,只认为是一条命令(所以意义应该不大) dirty: 仅仅针对WiredTiger引擎,官网解释是脏数据字节的缓存百分比 used:仅仅针对WiredTiger引擎,官网解释是正在使用中的缓存百分比 flushes: For WiredTiger引擎:指checkpoint的触发次数在一个轮询间隔期间 For MMAPv1 引擎:每秒执行fsync将数据写入硬盘的次数 注:一般都是0,间断性会是1, 通过计算两个1之间的间隔时间,可以大致了解多长时间flush一次。flush开销是很大的, 如果频繁的flush,可能就要找找原因了 vsize: 虚拟内存使用量,单位MB (这是 在mongostat 最后一次调用的总数据) res: 物理内存使用量,单位MB (这是 在mongostat 最后一次调用的总数据) 注:这个和你用top看到的一样, vsize一般不会有大的变动, res会慢慢的上升,如果res经常突然下降,去查查是否有别的程序狂吃内存。 qr: 客户端等待从MongoDB实例读数据的队列长度 qw: 客户端等待从MongoDB实例写入数据的队列长度 ar: 执行读操作的活跃客户端数量 aw: 执行写操作的活客户端数量 注:如果这两个数值很大,那么就是DB被堵住了,DB的处理速度不及请求速度。看看是否有开销很大的慢查询。如果查询一切正常,确实是负载很大,就需要加机器了 netIn:MongoDB实例的网络进流量 netOut:MongoDB实例的网络出流量 注:此两项字段表名网络带宽压力,一般情况下,不会成为瓶颈 conn: 打开连接的总数,是qr,qw,ar,aw的总和 注:MongoDB为每一个连接创建一个线程,线程的创建与释放也会有开销,所以尽量要适当配置连接数的启动参数, maxIncomingConnections,阿里工程师建议在5000以下,基本满足多数场景
db状态查询
1.全局操作变量db db表示的是当前所在的数据库对象实例
2.可以在mongos上进行查询,查询的是集群中所有分片节点数据库的信息
3.也可在shard节点上进行查询,查询的结果仅仅是当前节点所在的分片数据库的信息
4.mongos节点上只有db变量,没有rs变量
rs副本集状态查询
1.全局操作变量rs rs表示当前所在的副本(主副本或者从副本)的对象实例
2.只能通过在shard节点上执行,不能在mongos节点上进行rs命令操作
3.shard节点上既有db变量,也有rs变量
复制集状态查询:rs.status()
查看oplog状态: rs.printReplicationInfo()
查看复制延迟:rs.printSlaveReplicationInfo()
查看服务状态详情:db.serverStatus()
oplog的配置管理
oplog是local库下的一个固定集合,Secondary就是通过查看Primary的oplog这个集合来进行复制的。每个节点都有oplog,记录从主节点复制过来的信息,这样每个成员都可以作为同步源给其它节点。
默认是disk的5%(最小为1G,最大50G)。他只能保存特定数量的操作日志,通常oplog使用空间的增长速度跟系统处理写请求的速度相当。如果主节点每分钟处理1KB的写入数据,那么oplog每分钟大约也写入1KB数据。
第一次启动节点时,MongoDB会建立Oplog,会有一个默认的大小,这个大小取决于机器的操作系统,3.4版本一旦启动,再修改oplogSize就不生效了
oplog主要是用于副本同步Primary时使用的,类似于mysql的binlog!不能轻易删除!如果大小超过了设定的大小,会采用覆盖的方式继续更新oplog
新MongoDB节点启动时,配置文件mongo.conf设置oplogSize: 4096 即4G大小,启动生效