zookeeper基础知识
zk session
每一个客户端连接到zk的时候都会生成一个session来代表这个客户端
session有创建和销毁的过程,session只出现在zk的临时节点上面
zk的数据和redis一样全部存储在内存中
zk会在所有节点保存所有客户端的session信息
zk只有主节点可以写,其他从节点都只能读
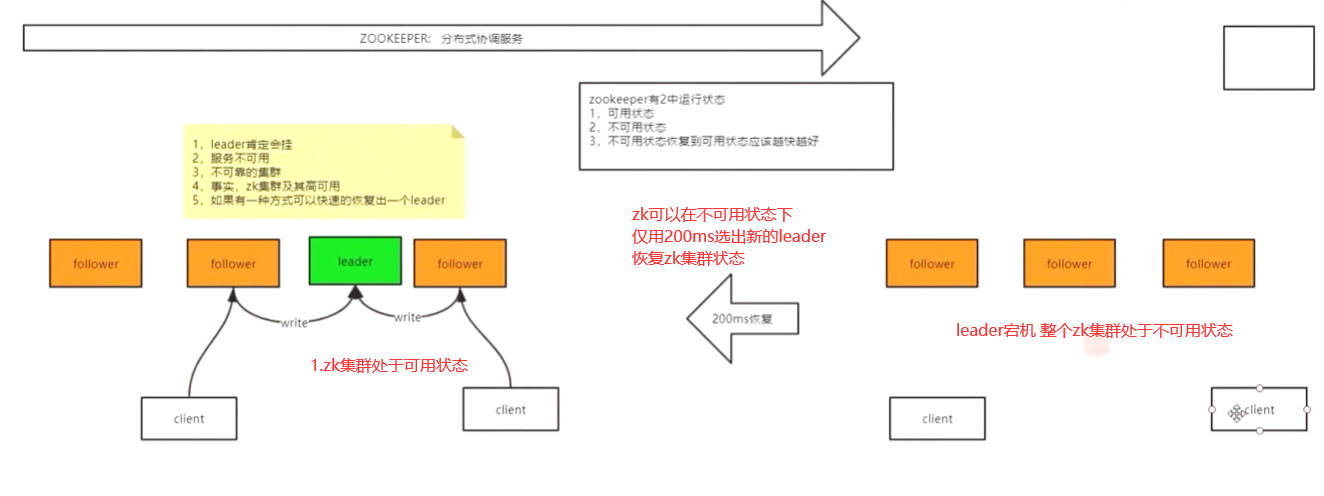
zk集群是单主的模式,有单点故障问题,但是单主节点可以保证处理顺序的一致性
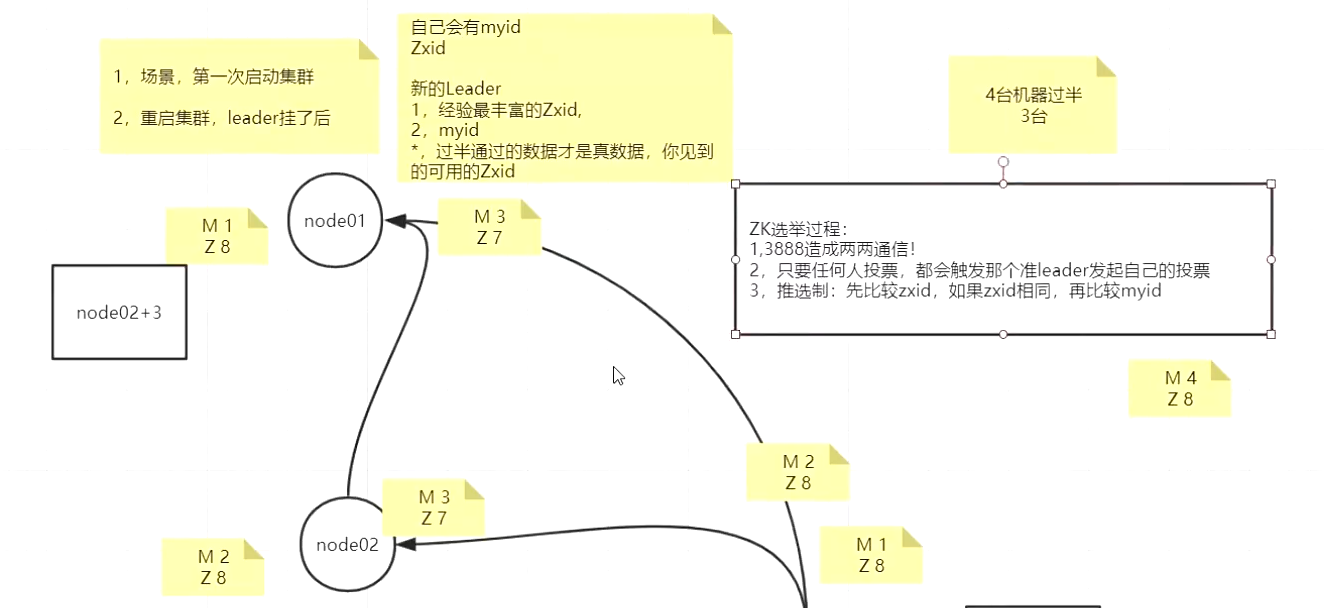
主节点一旦宕机,zk会立即在从节点中投票选出一个新的主节点
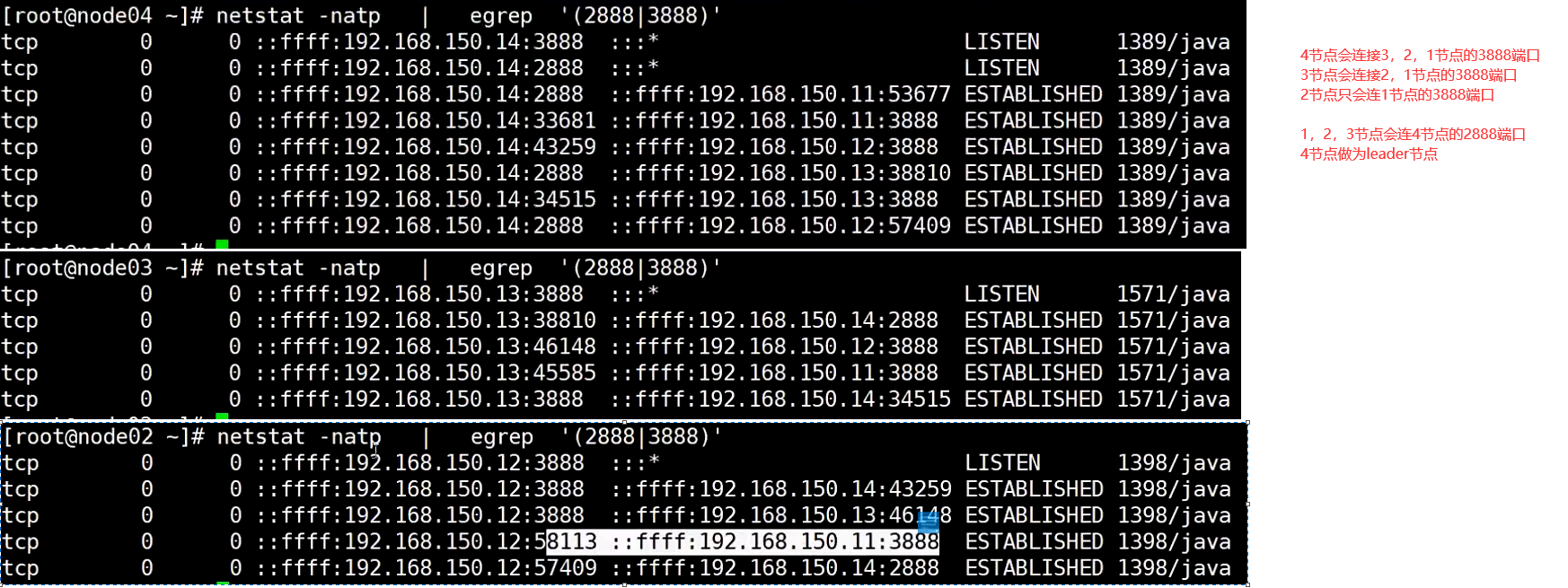
3888端口是zk所有节点启动的时候相互进行通信来选举zk leader
zk leader选出来后会监听2888端口,其他节点会连接leader节点的2888端口
然后通过2888端口进行节点创建,删除等相关业务操作
zookeeper集群状态



zookeeper的连接模型


Paxos分布式一致性算法
Paxos成立的前提条件
必须保证集群中所有主机通信是安全的,只有在一个可信的网络环境中才能成立
ZAB协议
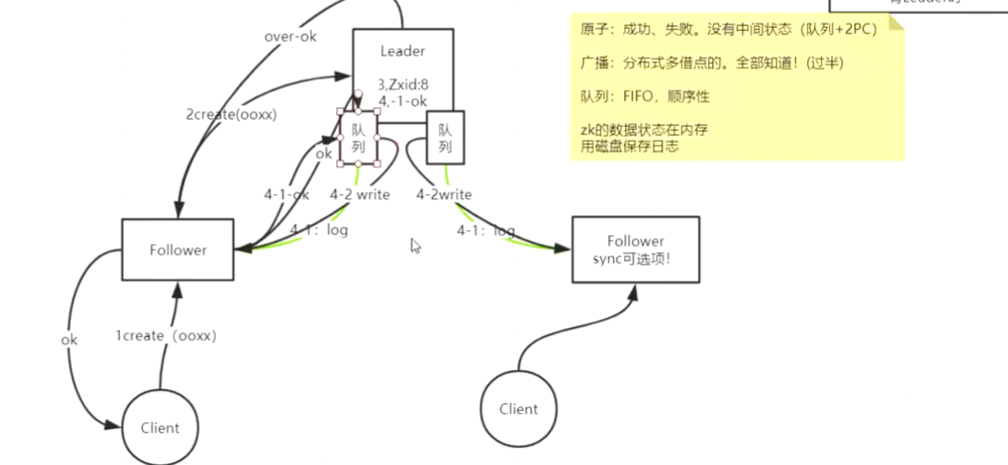
两阶段提交
1.leader把消息发送给所有的follwer,所有的follower会在本机先写相应的日志文件
leader会等待超过半数的follower返回写日志成功的结果
2.leader接收到超过半数的follower(包含leader本身计算一票)成功消息后,leader本身会把数据写入自己的内存然后会把数据写入内存的任务发送给每个follower对应维护的消息队列
所有的follower会从自己的队列里消费任务,最终实现整个集群节点数据的一致性
ZAB快速选出leader节点机制
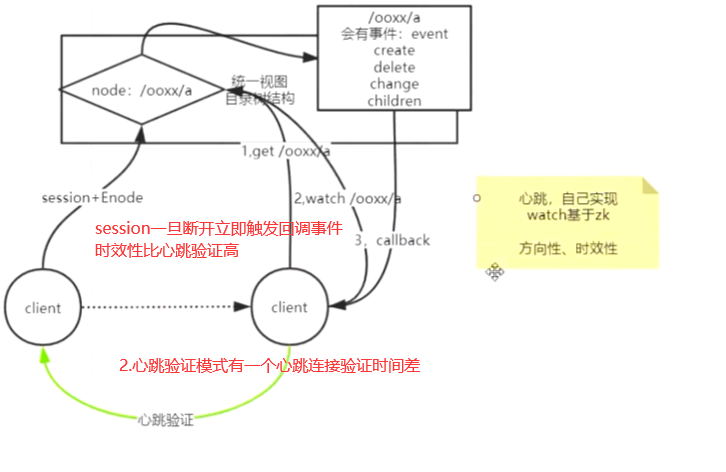
zookeeper的watch机制-分布式协调
1.轮询心跳机制
2.watch机制
zk最大的优势是有事件回调机制
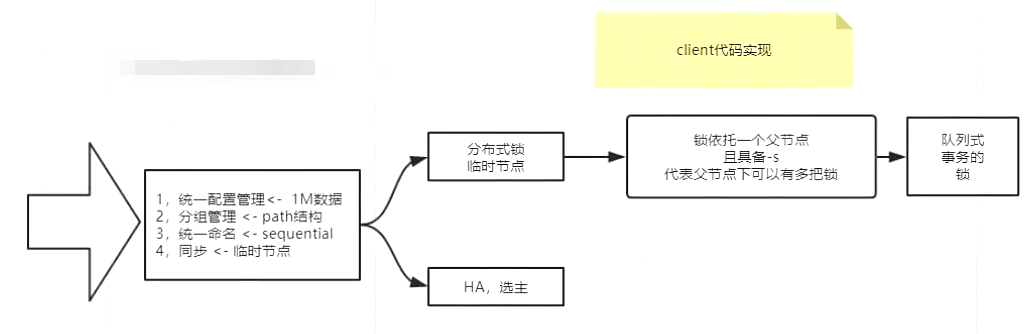
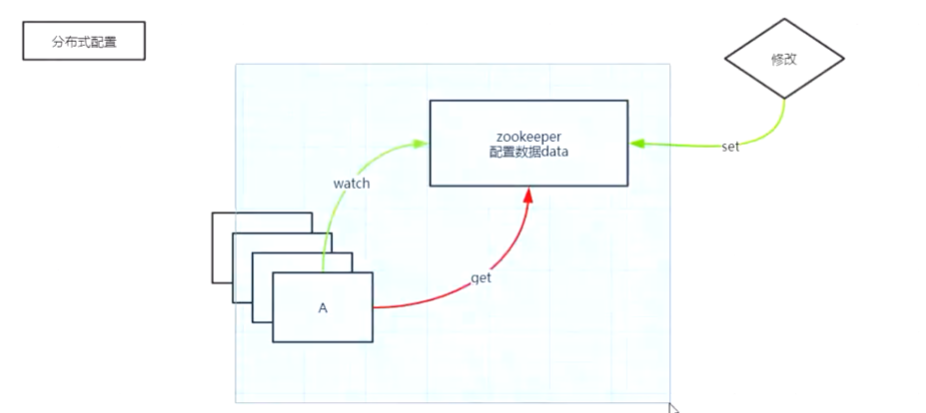
zookeeper实现分布式协调机制

zookeeper实现分布式锁
zk实现分布式锁的优势 zk集群是高可用的
redis是有单点故障 而且不能开启数据持久化,开启持久化就涉及磁盘IO影响性能
锁的功能是在单机多线程或者分布式多主机多线程的情况下限制同一时刻只能有一个客户端使用被锁的资源
单线程的情况下是无需设置锁的
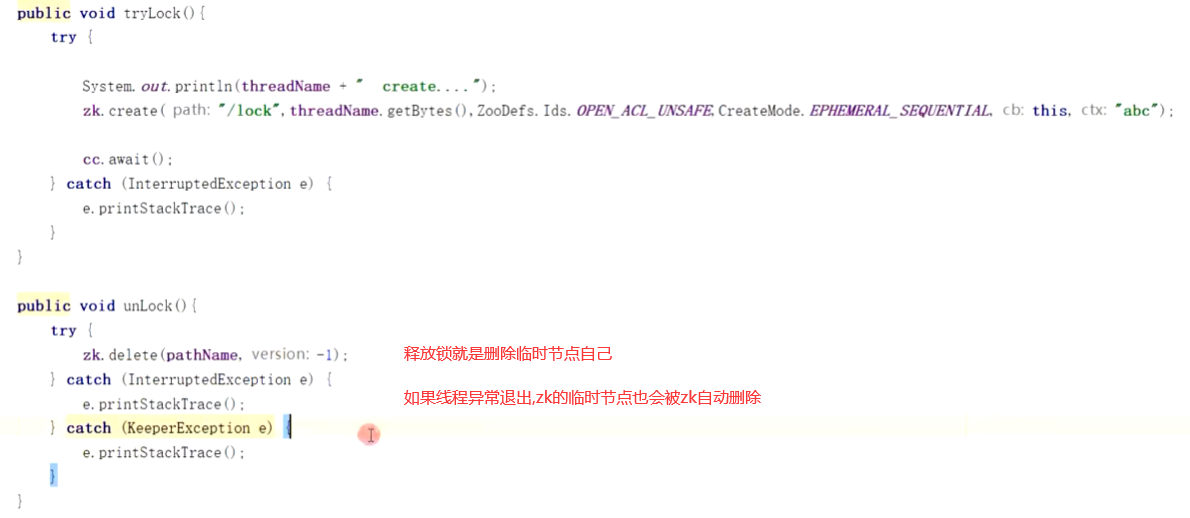
第一步:争抢锁 只有一个客户端能获得锁
第二步:处理死锁 获得锁的客户端在没有释放锁之前就宕机
第三步:客户端正常释放锁
第四步: 锁被释放或者被删除后,如何通知其它客户端
分布式锁实现机制
1.每个独立线程并发连接zk集群
2.线程连接zk后调用zk的API创建一个序列临时节点,创建完成之后所有线程进入等待状态
3.注册创建zk临时节点回调函数,获取当前zk目录下的所有子节点
4.比较子节点列表编号,把编号最小的线程从等待状态切换成运行状态
5.每个zk临时节点watch它前面编号的zk节点