修改集群IP
通过统一修改各集群节点的hosts文件来实现IP迁移


127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 # ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 ##start user defiend### 192.168.30.105 elastic-node1 192.168.30.110 elastic-node2 192.168.30.110 mysql-node1 192.168.30.110 redis-node1 192.168.30.105 zookeeper-node1 192.168.30.110 zookeeper-node2 192.168.30.105 kafka-node1 192.168.30.110 kafka-node2 192.168.30.105 flink-node1 192.168.30.110 flink-node2 192.168.30.110 nginx-node1 192.168.30.110 Tlog-node1 ####end user defiend######
- name: Copy the hosts to {{ groups["all"] }}
template: src=hosts.j2 dest="/etc/hosts"
tags: hoststest
- name: set esmaster hosts for {{ groups["all"] }}
lineinfile: dest=/etc/hosts insertafter="{{item.position}}" line="{{item.value}}" state=present
with_items:
- {position: EOF, value: "{{ groups['elastic-master'][0] }} instance"}
tags: hoststest
- name: get hosts file data
shell: cat /etc/hosts
register: hosts_file_result
tags: hoststest
- name: echo hosts data test
debug:
msg: "{{ hosts_file_result.stdout_lines }}"
tags: hoststest
- name: get elastic hostsname
shell: cat /etc/hosts | grep elastic | awk '{print $2}'
register: elastic_hosts
tags: hoststest
- name: get zookeeper hostsname
shell: cat /etc/hosts | grep zookeeper | awk '{print $2}'
register: zookeeper_hosts
tags: hoststest
- name: get zookeeper hostsipname
shell: cat /etc/hosts | grep zookeeper
register: zookeeper_ip_hosts
tags: hoststest
- name: get kafka hostsname
shell: cat /etc/hosts | grep kafka | awk '{print $2}'
register: kafka_hosts
tags: hoststest
- name: get flink hostsname
shell: cat /etc/hosts | grep flink | awk '{print $2}'
register: flink_hosts
tags: hoststest
- name: get redis hostsname
shell: cat /etc/hosts | grep redis | awk '{print $2}'
register: redis_hosts
tags: hoststest
- name: get mysql hostsname
shell: cat /etc/hosts | grep mysql | awk '{print $2}'
register: mysql_hosts
tags: hoststest
- name: get Tlog hostsname
shell: cat /etc/hosts | grep Tlog | awk '{print $2}'
register: Tlog_hosts
tags: hoststest
- name: get nginx hostsname
shell: cat /etc/hosts | grep nginx | awk '{print $2}'
register: nginx_hosts
tags: hoststest
应用配置文件模板
所有的连接信息通过hostsname来进行连接配置,不再按照默认的ip地址来连接
code: beanPath: com/transfar/admin projectPath: D:/sourceCode/git/admin/ console-available: true export: imgFilePath: /Users/ mybatis-plus: configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl map-underscore-to-camel-case: false mapper-locations: classpath:mapper/*/*.xml type-aliases-package: com.transfar.admin.dao server: port: 8082 spring: profiles: active: local jackson: date-format: yyyy-MM-dd HH:mm:ss time-zone: GMT+8 output: ansi: enabled: ALWAYS #Springboot默认上传文件大小为不超过1MB,现根据业务需求设置为不超过5MB servlet: multipart: max-file-size: 5MB max-request-size: 5MB application: name: admin-console datasource: driverClassName: com.mysql.cj.jdbc.Driver url: jdbc:mysql://{{mysql_hosts.stdout_lines[0]}}:{{MYSQL_PORT}}/siem?allowPublicKeyRetrieval=true&useSSL=false&useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai password: {{ MYSQL_CONNECT_PASSWORD }} type: com.alibaba.druid.pool.DruidDataSource username: {{ MYSQL_CONNECT_USERNAME }} redis: database: 0 host: {{ redis_hosts.stdout_lines[0] }} port: {{ redis_port }} password: {{ redis_password }} #============== kafka =================== # 指定kafka 代理地址,可以多个 kafka: bootstrap-servers: {{ kafka_hosts.stdout_lines | join(':9092,') }}:9092 #=============== provider ======================= producer: # retries: 0 # 每次批量发送消息的数量 #batch-size: 16384 # buffer-memory: 33554432 # 指定消息key和消息体的编解码方式 key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.apache.kafka.common.serialization.StringSerializer #=============== consumer ======================= # 指定默认消费者group id consumer: group-id: user-notification-group auto-offset-reset: earliest # enable-auto-commit: true # auto-commit-interval: 100 # 指定消息key和消息体的编解码方式 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer logging: level: root: info com.transfar.admin: debug file: name: logs/${spring.application.name}.log eureka: client: serviceUrl: defaultZone: http://{{ eureka_name }}:{{ eureka_passwd }}@{{ nginx_hosts.stdout_lines[0] }}:8761/eureka fdfs: soTimeout: 1500 #socket连接超时时长 connectTimeout: 600 #连接tracker服务器超时时长 resHost: {{ nginx_hosts.stdout_lines[0] }} storagePort: 23000 visit: http trackerList: #TrackerList参数,支持多个,我这里只有一个,如果有多个在下方加- x.x.x.x:port - {{ nginx_hosts.stdout_lines[0] }}:22122 nginx: port: 8999 file: type: .+(.jpg|.gif|.png|.pdf|.doc|.xls|.ppt|.rar|.zip)$ management: endpoints: web: exposure: include: "*" metrics: tags: application: ${spring.application.name} # 暴露的数据中添加application label: endpoint: health: show-details: always # 1-报表任务启动 2 - 关闭 report: start: 1 license: address: {{ taishi_dir }}/app/license/license.json asset: visit: http ip: {{ nginx_hosts.stdout_lines[0] }} jasypt: encryptor: password: JeF8U9wHFOMfs2Y8 ribbon: ReadTimeout: 60000 ConnectTimeout: 60000
broker.id={{ ansible_default_ipv4.address.split('.')| last }}
listeners=PLAINTEXT://{{ ansible_default_ipv4.address }}:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs={{ kafka_logdir }}
num.partitions=1
num.recovery.threads.per.data.dir=1
log.retention.hours=96
log.retention.bytes=-1
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect={{ zookeeper_hosts.stdout_lines | join(':2181,') }}:2181
zookeeper.connection.timeout.ms=6000000
delete.topic.enable=true
auto.create.topics.enable=true
default.replication.factor=1
offsets.topic.replication.factor=1
tickTime=2000 initLimit=10 syncLimit=5 clientPort=2181 maxClientCnxns=0 dataDir= {{ zk_dataDir }} dataLogDir= {{ zk_logDir }} {% for host in zookeeper_ip_hosts.stdout_lines %} {% set ip= host.split(' ') | first %} server.{{ ip.split('.') | last }}={{ host.split(' ') | last }}:2888:3888 {% endfor %}

################################################################################ # Licensed to the Apache Software Foundation (ASF) under one # or more contributor license agreements. See the NOTICE file # distributed with this work for additional information # regarding copyright ownership. The ASF licenses this file # to you under the Apache License, Version 2.0 (the # "License"); you may not use this file except in compliance # with the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. ################################################################################ #============================================================================== # Common #============================================================================== # The external address of the host on which the JobManager runs and can be # reached by the TaskManagers and any clients which want to connect. This setting # is only used in Standalone mode and may be overwritten on the JobManager side # by specifying the --host <hostname> parameter of the bin/jobmanager.sh executable. # In high availability mode, if you use the bin/start-cluster.sh script and setup # the conf/masters file, this will be taken care of automatically. Yarn/Mesos # automatically configure the host name based on the hostname of the node where the # JobManager runs. jobmanager.rpc.address: {{ flink_hosts.stdout_lines[0] }} # The RPC port where the JobManager is reachable. jobmanager.rpc.port: 6123 #taskmanager.memory.jvm-metaspace.size: 1024m # The total process memory size for the JobManager. # # Note this accounts for all memory usage within the JobManager process, including JVM metaspace and other overhead. #jobmanager.memory.process.size: 1600m jobmanager.memory.process.size: 4096m jobmanager.memory.jvm-metaspace.size: 2048m # The total process memory size for the TaskManager. # # Note this accounts for all memory usage within the TaskManager process, including JVM metaspace and other overhead. taskmanager.memory.task.heap.size: {{ taskmanager_memory_task_heap_size }} taskmanager.memory.managed.size: 1024m taskmanager.memory.framework.off-heap.size: 2048m taskmanager.memory.jvm-metaspace.size: 2048m #taskmanager.memory.process.size: 1728m # To exclude JVM metaspace and overhead, please, use total Flink memory size instead of 'taskmanager.memory.process.size'. # It is not recommended to set both 'taskmanager.memory.process.size' and Flink memory. # # taskmanager.memory.flink.size: 1280m # The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline. taskmanager.numberOfTaskSlots: {{ taskmanager_numberOfTaskSlots }} # The parallelism used for programs that did not specify and other parallelism. parallelism.default: 1 # The default file system scheme and authority. # # By default file paths without scheme are interpreted relative to the local # root file system 'file:///'. Use this to override the default and interpret # relative paths relative to a different file system, # for example 'hdfs://mynamenode:12345' # # fs.default-scheme #============================================================================== # High Availability #============================================================================== # The high-availability mode. Possible options are 'NONE' or 'zookeeper'. # # high-availability: zookeeper # The path where metadata for master recovery is persisted. While ZooKeeper stores # the small ground truth for checkpoint and leader election, this location stores # the larger objects, like persisted dataflow graphs. # # Must be a durable file system that is accessible from all nodes # (like HDFS, S3, Ceph, nfs, ...) # # high-availability.storageDir: hdfs:///flink/ha/ # The list of ZooKeeper quorum peers that coordinate the high-availability # setup. This must be a list of the form: # "host1:clientPort,host2:clientPort,..." (default clientPort: 2181) # # high-availability.zookeeper.quorum: localhost:2181 # ACL options are based on https://zookeeper.apache.org/doc/r3.1.2/zookeeperProgrammers.html#sc_BuiltinACLSchemes # It can be either "creator" (ZOO_CREATE_ALL_ACL) or "open" (ZOO_OPEN_ACL_UNSAFE) # The default value is "open" and it can be changed to "creator" if ZK security is enabled # # high-availability.zookeeper.client.acl: open #============================================================================== # Fault tolerance and checkpointing #============================================================================== # The backend that will be used to store operator state checkpoints if # checkpointing is enabled. # # Supported backends are 'jobmanager', 'filesystem', 'rocksdb', or the # <class-name-of-factory>. # # state.backend: filesystem # Directory for checkpoints filesystem, when using any of the default bundled # state backends. # # state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints # Default target directory for savepoints, optional. # # state.savepoints.dir: hdfs://namenode-host:port/flink-checkpoints # Flag to enable/disable incremental checkpoints for backends that # support incremental checkpoints (like the RocksDB state backend). # # state.backend.incremental: false state.checkpoints.num-retained: 2 # The failover strategy, i.e., how the job computation recovers from task failures. # Only restart tasks that may have been affected by the task failure, which typically includes # downstream tasks and potentially upstream tasks if their produced data is no longer available for consumption. jobmanager.execution.failover-strategy: region #============================================================================== # Rest & web frontend #============================================================================== # The port to which the REST client connects to. If rest.bind-port has # not been specified, then the server will bind to this port as well. # #rest.port: 8081 # The address to which the REST client will connect to # #rest.address: 0.0.0.0 # Port range for the REST and web server to bind to. # #rest.bind-port: 8080-8090 # The address that the REST & web server binds to # #rest.bind-address: 0.0.0.0 rest.bind-address: 0.0.0.0 # Flag to specify whether job submission is enabled from the web-based # runtime monitor. Uncomment to disable. #web.submit.enable: false #============================================================================== # Advanced #============================================================================== # Override the directories for temporary files. If not specified, the # system-specific Java temporary directory (java.io.tmpdir property) is taken. # # For framework setups on Yarn or Mesos, Flink will automatically pick up the # containers' temp directories without any need for configuration. # # Add a delimited list for multiple directories, using the system directory # delimiter (colon ':' on unix) or a comma, e.g.: # /data1/tmp:/data2/tmp:/data3/tmp # # Note: Each directory entry is read from and written to by a different I/O # thread. You can include the same directory multiple times in order to create # multiple I/O threads against that directory. This is for example relevant for # high-throughput RAIDs. # # io.tmp.dirs: /tmp io.tmp.dirs: {{ flink_temp_dir }} # The classloading resolve order. Possible values are 'child-first' (Flink's default) # and 'parent-first' (Java's default). # # Child first classloading allows users to use different dependency/library # versions in their application than those in the classpath. Switching back # to 'parent-first' may help with debugging dependency issues. # # classloader.resolve-order: child-first # The amount of memory going to the network stack. These numbers usually need # no tuning. Adjusting them may be necessary in case of an "Insufficient number # of network buffers" error. The default min is 64MB, the default max is 1GB. # #taskmanager.memory.network.fraction: 0.1 #taskmanager.memory.network.min: 64mb #taskmanager.memory.network.max: 1gb #============================================================================== # Flink Cluster Security Configuration #============================================================================== # Kerberos authentication for various components - Hadoop, ZooKeeper, and connectors - # may be enabled in four steps: # 1. configure the local krb5.conf file # 2. provide Kerberos credentials (either a keytab or a ticket cache w/ kinit) # 3. make the credentials available to various JAAS login contexts # 4. configure the connector to use JAAS/SASL # The below configure how Kerberos credentials are provided. A keytab will be used instead of # a ticket cache if the keytab path and principal are set. # security.kerberos.login.use-ticket-cache: true # security.kerberos.login.keytab: /path/to/kerberos/keytab # security.kerberos.login.principal: flink-user # The configuration below defines which JAAS login contexts # security.kerberos.login.contexts: Client,KafkaClient #============================================================================== # ZK Security Configuration #============================================================================== # Below configurations are applicable if ZK ensemble is configured for security # Override below configuration to provide custom ZK service name if configured # zookeeper.sasl.service-name: zookeeper # The configuration below must match one of the values set in "security.kerberos.login.contexts" # zookeeper.sasl.login-context-name: Client #============================================================================== # HistoryServer #============================================================================== # The HistoryServer is started and stopped via bin/historyserver.sh (start|stop) # Directory to upload completed jobs to. Add this directory to the list of # monitored directories of the HistoryServer as well (see below). jobmanager.archive.fs.dir: file://{{ flink_history_dir }} # The address under which the web-based HistoryServer listens. #historyserver.web.address: 0.0.0.0 # The port under which the web-based HistoryServer listens. historyserver.web.port: 8882 # Comma separated list of directories to monitor for completed jobs. historyserver.archive.fs.dir: file://{{ flink_history_dir }} # Interval in milliseconds for refreshing the monitored directories. #historyserver.archive.fs.refresh-interval: 10000 env.java.home: /usr/lib/java/jdk1.8.0_191 web.upload.dir: {{ flink_web_jar }} metrics.reporters: prom metrics.reporter.prom.class: org.apache.flink.metrics.prometheus.PrometheusReporter metrics.reporter.prom.port: 9213-9214
console-available: true export: imgFilePath: /Users/ mybatis-plus: configuration: log-impl: org.apache.ibatis.logging.stdout.StdOutImpl map-underscore-to-camel-case: false mapper-locations: classpath:mapper/*/*.xml type-aliases-package: com.transfar.admin.dao server: port: 8082 spring: profiles: active: local jackson: date-format: yyyy-MM-dd HH:mm:ss time-zone: GMT+8 output: ansi: enabled: ALWAYS #Springboot默认上传文件大小为不超过1MB,现根据业务需求设置为不超过5MB servlet: multipart: max-file-size: 5MB max-request-size: 5MB application: name: admin-console datasource: driverClassName: com.mysql.cj.jdbc.Driver url: jdbc:mysql://mysql-node1:6306/siem?allowPublicKeyRetrieval=true&useSSL=false&useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai password: Transfar@2022 type: com.alibaba.druid.pool.DruidDataSource username: taishi redis: database: 0 host: redis-node1 port: 6379 password: Transfar@2022 #============== kafka =================== # 指定kafka 代理地址,可以多个 kafka: bootstrap-servers: kafka-node1:9092,kafka-node2:9092 #=============== provider ======================= producer: # retries: 0 # 每次批量发送消息的数量 #batch-size: 16384 # buffer-memory: 33554432 # 指定消息key和消息体的编解码方式 key-serializer: org.apache.kafka.common.serialization.StringSerializer value-serializer: org.apache.kafka.common.serialization.StringSerializer #=============== consumer ======================= # 指定默认消费者group id consumer: group-id: user-notification-group auto-offset-reset: earliest # enable-auto-commit: true # auto-commit-interval: 100 # 指定消息key和消息体的编解码方式 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer value-deserializer: org.apache.kafka.common.serialization.StringDeserializer logging: level: root: info com.transfar.admin: debug file: name: logs/${spring.application.name}.log eureka: client: serviceUrl: defaultZone: http://transfar:Transfar123@nginx-node1:8761/eureka fdfs: soTimeout: 1500 #socket连接超时时长 connectTimeout: 600 #连接tracker服务器超时时长 resHost: nginx-node1 storagePort: 23000 visit: http trackerList: #TrackerList参数,支持多个,我这里只有一个,如果有多个在下方加- x.x.x.x:port - nginx-node1:22122 nginx: port: 8999 file: type: .+(.jpg|.gif|.png|.pdf|.doc|.xls|.ppt|.rar|.zip)$ management: endpoints: web: exposure: include: "*" metrics: tags: application: ${spring.application.name} # 暴露的数据中添加application label: endpoint: health: show-details: always # 1-报表任务启动 2 - 关闭 report: start: 1 license: address: /app/taishi/app/license/license.json asset: visit: http ip: nginx-node1 jasypt: encryptor: password: JeF8U9wHFOMfs2Y8 ribbon: ReadTimeout: 60000 ConnectTimeout: 60000
task配置
- name: Copy the updateip.sh to {{ groups["all"] }}
template: src=updateip.sh.j2 dest={{ taishi_dir }}/updateip.sh owner={{ taishi_user }} group={{ taishi_user }} mode=0755
tags: changeip
- name: "Copy the prometheus.yml"
template: src=prometheus.yml.j2 dest="{{ monitor_dir }}/promethues/server/prometheus.yml" owner={{ taishi_user }} group={{ taishi_user }} mode=0755
tags: changeip
- name: "sh updateip.sh"
shell: "{{ taishi_dir }}/updateip.sh"
ignore_errors: True
tags: changeip
- name: stop taishi serivice {{ groups["all"] }}
service: name=taishi state=stopped
tags: changeip
- name: start taishiservice to {{ groups["all"] }}
service: name=taishi state=started
tags: changeip
#! /bin/bash #####update mysql data############### mysqlip=`cat /etc/hosts | grep mysql | awk '{print $1}'` newip=`cat /etc/hosts | grep nginx | awk '{print $1}'` /app/taishi/mysql/mysql-5.7.31-linux-glibc2.12-x86_64/bin/mysql -P6306 -h$mysqlip -utaishi -pTransf2 siem -e "UPDATE sys_config SET vals = 'https://$newip:1688/devops/monitor/d/rYdddlPWk-evan/sadan-ji-ban-jian-kong?orgId=1&refresh=1m&kiosk=tv' where flag = 'sysInfo' and feature = 'url'" /app/taishi/mysql/mysql-5.7.31-linux-glibc2.12-x86_64/bin/mysql -P6306 -h$mysqlip -utaishi -pTransfa siem -e "UPDATE sys_config SET vals = 'https://$newip:1688' where id = 'h89573859ol6yhn8uhbdccc564rf8ui9'" /app/taishi/mysql/mysql-5.7.31-linux-glibc2.12-x86_64/bin/mysql -P6306 -h$mysqlip -utaishi -pTranssiem -e "UPDATE sa_log_worker SET ip = '$newip' where name = 'work1'" #####get host ip########## myip="192.168.30.110" ########update kafka config############ sed -ri "s/([0-9]{1,3}.){3}[0-9]{1,3}/$myip/g" /app/taishi/kafka/config/server.properties #####update Tlog config############### sed -ri "s/([0-9]{1,3}.){3}[0-9]{1,3}/$myip/g" /app/taishi/Tlog/config/application.yml
#! /bin/bash #####update mysql data############### mysqlip=`cat /etc/hosts | grep mysql | awk '{print $1}'` newip=`cat /etc/hosts | grep nginx | awk '{print $1}'` {{ taishi_dir }}/mysql/mysql-5.7.31-linux-glibc2.12-x86_64/bin/mysql -P{{ MYSQL_PORT }} -h$mysqlip -u{{MYSQL_CONNECT_USERNAME}} -p{{MYSQL_CONNECT_PASSWORD}} siem -e "UPDATE sys_config SET vals = 'https://$newip:1688/devops/monitor/d/rYdddlPWk-evan/sadan-ji-ban-jian-kong?orgId=1&refresh=1m&kiosk=tv' where flag = 'sysInfo' and feature = 'url'" {{ taishi_dir }}/mysql/mysql-5.7.31-linux-glibc2.12-x86_64/bin/mysql -P{{ MYSQL_PORT }} -h$mysqlip -u{{MYSQL_CONNECT_USERNAME}} -p{{MYSQL_CONNECT_PASSWORD}} siem -e "UPDATE sys_config SET vals = 'https://$newip:1688' where id = 'h89573859ol6yhn8uhbdccc564rf8ui9'" {{ taishi_dir }}/mysql/mysql-5.7.31-linux-glibc2.12-x86_64/bin/mysql -P{{ MYSQL_PORT }} -h$mysqlip -u{{MYSQL_CONNECT_USERNAME}} -p{{MYSQL_CONNECT_PASSWORD}} siem -e "UPDATE sa_log_worker SET ip = '$newip' where name = 'work1'" #########get host ip########## myip="{{ ansible_default_ipv4.address }}" ########update kafka config############ sed -ri "s/([0-9]{1,3}.){3}[0-9]{1,3}/$myip/g" {{ taishi_dir }}/kafka/config/server.properties #####update Tlog config############### sed -ri "s/([0-9]{1,3}.){3}[0-9]{1,3}/$myip/g" {{ taishi_dir }}/Tlog/config/application.yml ########update prometheus.yml ip config############ # startline=`cat -n /etc/hosts |grep 'start cluster'|awk '{print $1}'` # endline=`cat -n /etc/hosts |grep 'end cluster'|awk '{print $1}'` # iplists=`sed -n '${startline},${endline}p' /etc/hosts | grep -v "#" | grep -v '^$' | awk '{print $1}' | sort -u` ######update docker############### docker restart prometheus-v2.25.2
执行task

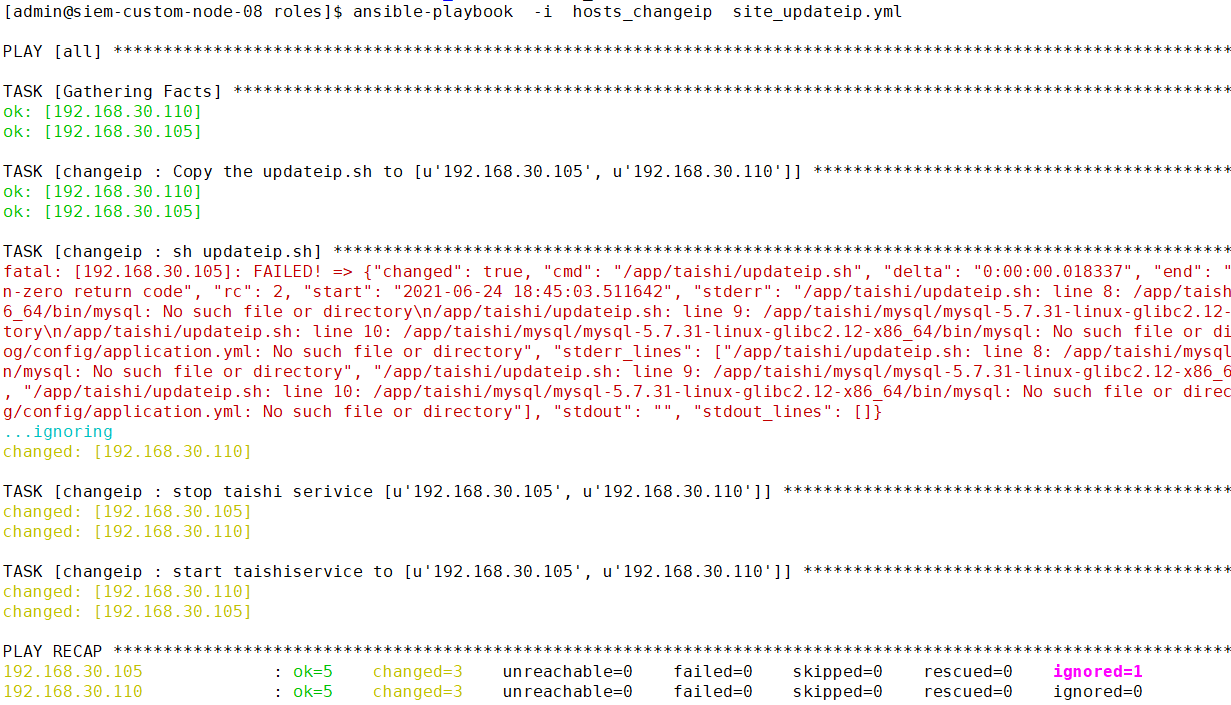
这样就可以随意修改集群中任何主机的IP
1.修改主机IP 重启被修改主机的网络服务
2.重新建立主控端和新地址被控端的免密连接
ssh-copy-id -f -i /home/admin/.ssh/id_rsa.pub admin@192.168.30.110
3.修改各个主机的/etc/hosts
4.修改hosts_changeip文件中的IP地址
5.执行ansible task
6.通过新的IP地址访问系统即可
shell批量处理IP hosts
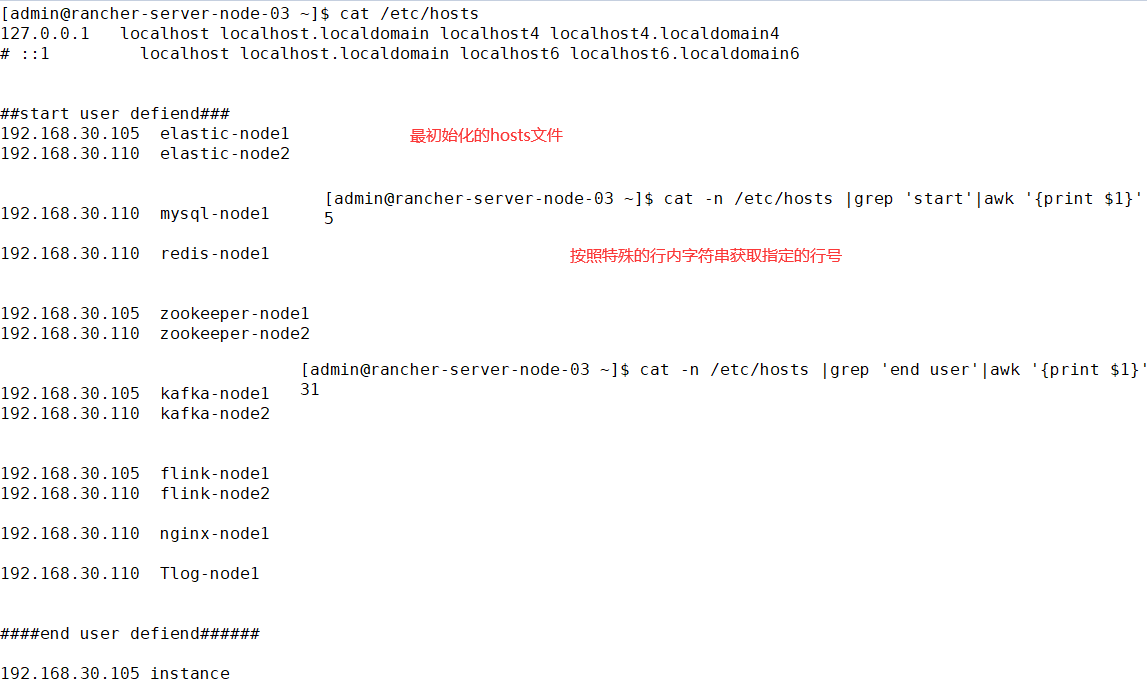
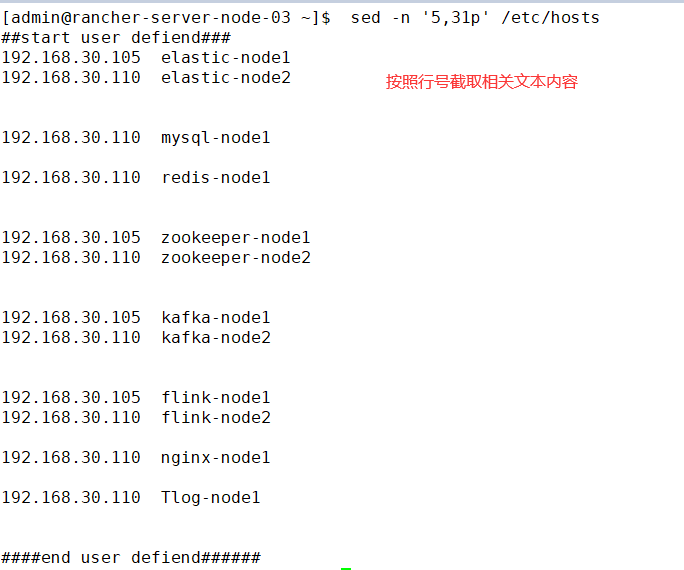
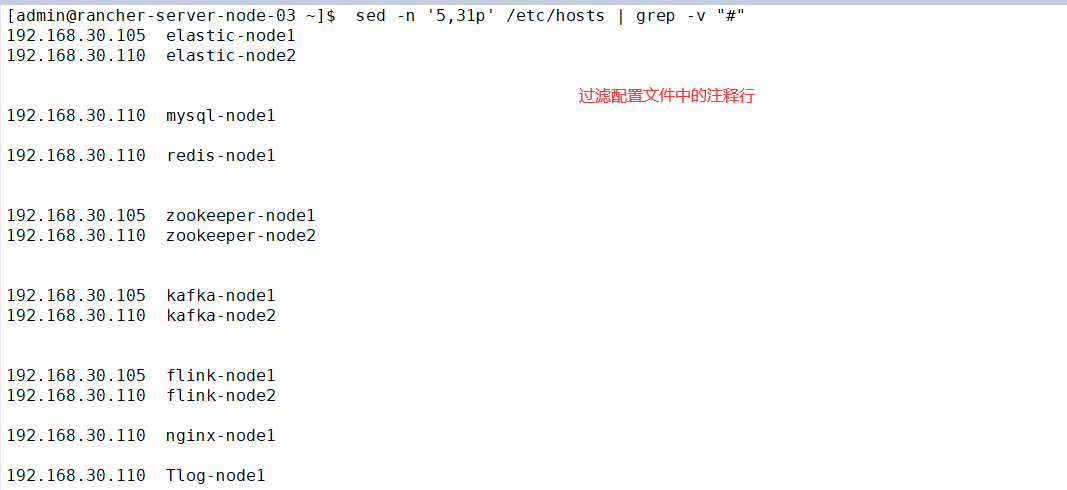

1.shell获取行号
cat -n /etc/hosts |grep 'start'|awk -F',' '{print $1}'
sed -n '5,31p' /etc/hosts | grep -v "#" | grep -v '^$' | awk '{print $1}' | sort -u
2.根据行号读取内容
sed -n '5,31p' /etc/hosts ##查询5至31行的内容