Service基础理论
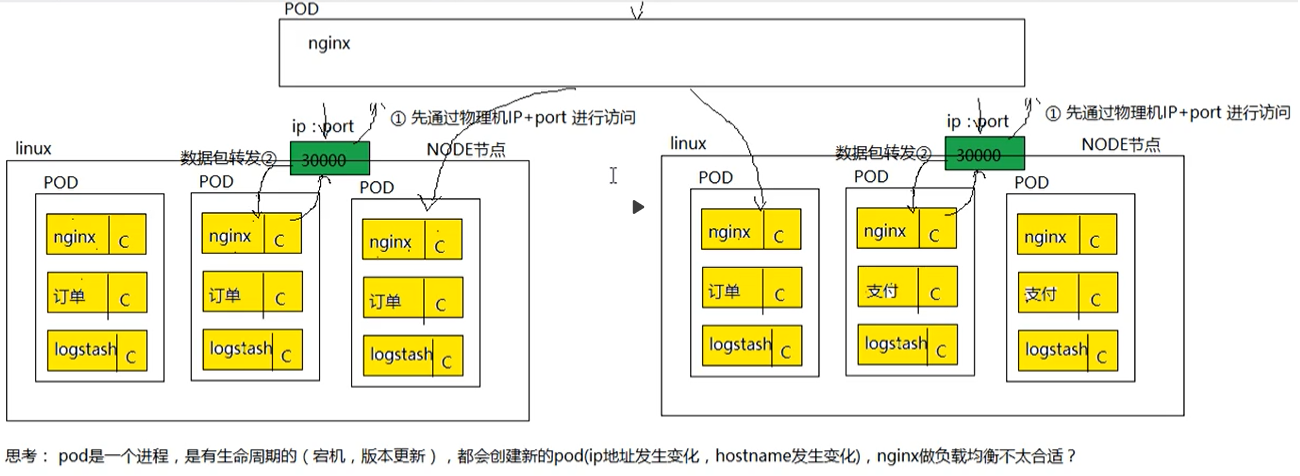
每个Pod都有自己的生命周期属于非可再生类的组件.在自愿或非自愿中断后只能被重 构的新Pod对象所取代
由Deployment等控制器管理的Pod对象中断后会由新建的Pod资源对象所取代.于是在动态,弹性的管理模型下Service资源用于为此类Pod对象提供一个固定,统一的访问接口及负载均衡的能力,并支持借助于新一代DNS系统的服务发现功能,解决客户端发现并访问容器化应用的难题
Service及Pod对象的IP地址都仅在Kubernetes集群内可达,它们无法接入集群外部的访问流量
Service端口用于接收客户端请求并将其转发至其后端的Pod中应用 的相应端口之上.因此,这种代理机制也称为"端口代理"(port proxy) 或四层代理,它工作于TCP/IP协议栈的传输层
Service的三种类型
1.在单一节点上做端口暴露(hostPort)及让Pod资源共享使用工作节点的网络 名称空间(hostNetwork)
2.NodePort类型的Service
3.LoadBalancer类型的Service
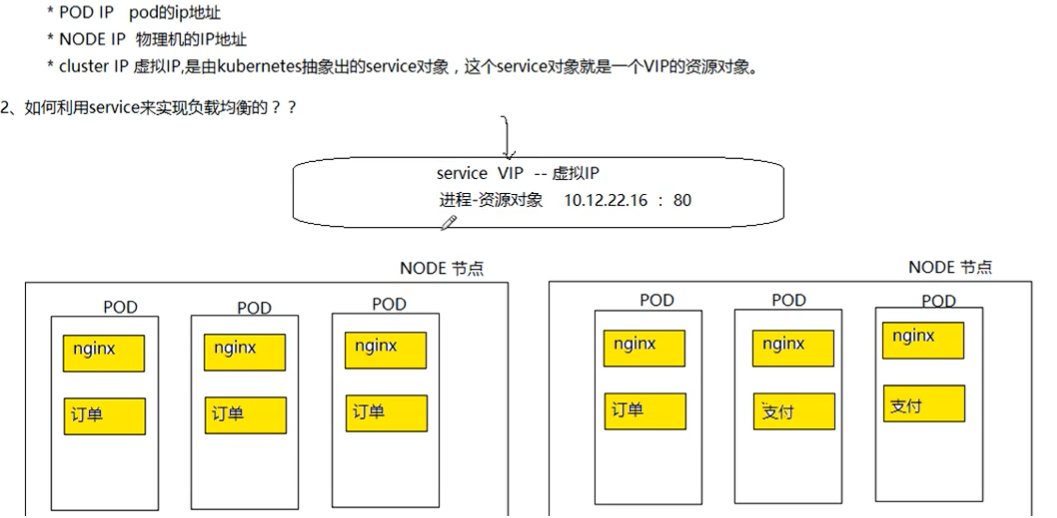
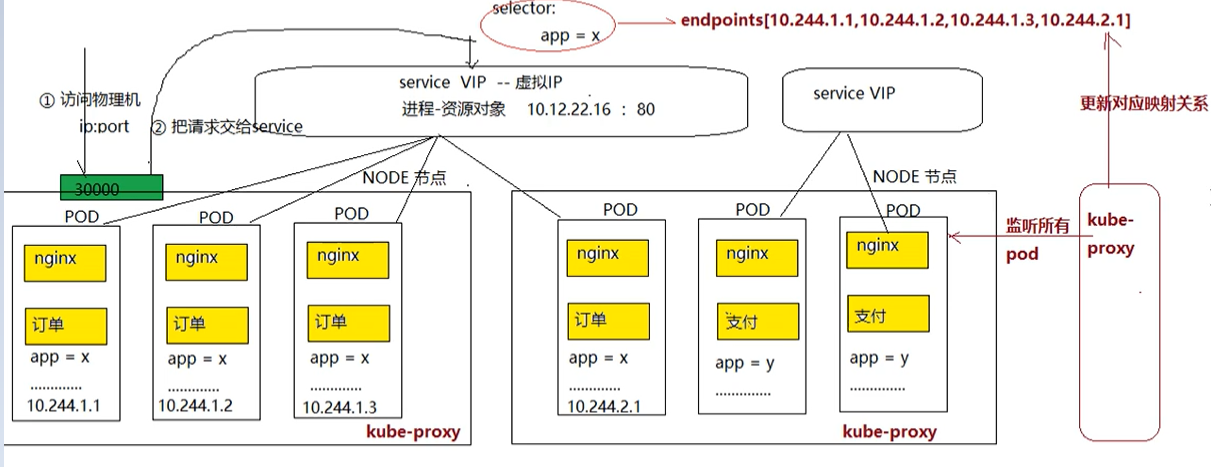
Service并不直接链接至Pod对象,它们之间还有一个中间层—Endpoints资源对象.它是一个由IP地址和端口组成的列表,这些IP 地址和端口则来自于由Service的标签选择器匹配到的Pod资源
Netfilter是Linux内核中用于管理网络报文的框架,它具有网络地址转换(NAT)、报文 改动和报文过滤等防火墙功能
Service三种代理模式
userspace代理模式
kube-proxy负责Service对象和Endpoints资源的创建和移除
对于每个Service对象kube-proxy会随机打开一个本地端口(运行于用户空间的kube-proxy 进程负责监听),任何到达此代理端口的连接请求都将被代理至当前Service 资源后端的各Pod对象上
iptables代理模式
kube-proxy负责Service对象和Endpoints资源的创建和移除
ipvs代理模式
仅仅流量调度功能由ipvs模块实现
相对于用户空间模型来说,iptables模型无须将流量在用户空间和内核空间来回切换,因而更加高效和可靠.不过其缺点是iptables代理模型不会在被挑中的后端Pod资源无响应时自动进行重定向,而userspace模型则可以

服务发现理论
Service服务发现机制
在Kubernetes系统上,Service为Pod中的服务类应用提供了一个稳定的访问入口但Pod 客户端中的应用如何得知某个特定Service资源的IP和端口.这个时候就需要引入服务发现(Service Discovery)的机制
Pod环境变量
创建Pod资源时kubelet会将其所属名称空间内的每个活动的Service对象以一系列环境 变量的形式注入其中。它支持使用Kubernetes Service环境变量以及与Docker的links 兼容的变量.Kubernetes为每个Service资源生成包括以下形式的环境变量在内的一系列环境变量,在 同一名称空间中创建的Pod对象都会自动拥有这些变量
基于环境变量的服务发现其功能简单、易用.但存在一定的局限,如仅有那些与创建的Pod对象在同一名称空间中且事先存在的Service对象的信息才会以环境变量的形式注入,那些处于非同一名称空间或者是在Pod资源创建之后才创建的Service对象的相关环境变量则不会被添加.
DNS机制
cat resolv.conf
nameserver 10.96.0.10
search default.svc.cluster.local,svc.cluster.local,cluster.local,ilinux.io
search参数中指定的DNS各搜索域,是以次序指定的几个域名后缀
解析时“myapp-svc”服务名称的搜索次序依次是default.svc.cluster.local、svc. cluster.local、cluster.local和ilinux.io
基于DNS的服务发现不受Service资源所在的名称空间和创建时间的限制
NodePort类型就是在工作节点的IP地址上选择一个端口用于将集群外部的用户请求转发至 目标Service的ClusterIP和Port.因此,这种类型的Service既可如ClusterIP一样受到 集群内部客户端Pod的访问,也会受到集群外部客户端通过套接字<NodeIP>:<NodePort> 进行的请求
LoadBalancer类型的Service会指向关联至Kubernetes集群外部的、切实存在的某个负载 均衡设备,该设备通过工作节点之上的NodePort向集群内部发送请求流量优势在于,它能够把 来自于集群外部客户端的请求调度至所有节点(或部分节点)的NodePort之上,而不是依赖于客户端自行决定连接至哪个节点,从而避免了因客户端指定的节点故障.而导致的服务不可用
NodePort类型的Service资源虽然能够于集群外部访问得到,但外部客户端必须得事先 得知NodePort和集群中至少一个节点的IP地址,且选定的节点发生故障时,客户端还得自行 选择请求访问其他的节点。另外,集群节点很可能是某IaaS云环境中使用私有IP地址的VM, 或者是IDC中使用私有地址的物理机,这类地址对互联网客户端不可达.因此,一般还应该在 集群之外创建一个具有公网IP地址的负载均衡器,由它接入外部客户端的请求并调度至集群 节点相应的NodePort之上
ExternalName:其通过将Service映射至由externalName字段的内容指定的主机名来暴露 服务,此主机名需要被DNS服务解析至CNAME类型的记录。换言之,此种类型并非定义由 Kubernetes集群提供的服务,而是把集群外部的某服务以DNS CNAME记录的方式映射到集群 内,从而让集群内的Pod资源能够访问外部的Service的一种实现方式
因此,这种类型的Service没有ClusterIP和NodePort,也没有标签选择器用于选择Pod资源但必须要使用spec.externalName属性定义一个CNAME记录用于返回外部真正提供服务的 主机的别名,而后通过CNAME记录值获取到相关主机的IP地址
Service默认的ClusterIP类型资源它仅能接收来自于集群中的Pod对象中的客户端程序的访问请求。如若需要将Service资源发布至网络外部,应该将其配置为NodePort或LoadBalancer类型。若要把外部的服务发布于集群内容供Pod对象使用,则需要定义一个ExternalName类型的 Service资源.
Headless Service
Headless Service对象没有ClusterIP,于是kube-proxy便无须处理此类请求.也就更没有 了负载均衡或代理它的需要
根据Headless Service的工作特性。可知它记录于ClusterDNS的A记录的相关解析结果是 后端Pod资源的IP地址,这就意味着客户端通过此Service资源的名称发现的是各Pod资源
Ingress是Kubernetes API的标准资源类型之一,它其实就是一组基于DNS名称( host) 或URL路径把请求转发至指定的Service资源的规则,用于将集群外部的请求流量转发至集群内部完成服务发布.它仅是一组路由规则的集合
Ingress控制器可基于某Ingress资源定义的规则将客户端的请求流量直接转发至与Service对应的后端Pod资源之上,这种转发机制会绕过Service资源,从而省去了由kube-proxy实现的 端口代理开销
存储卷理论
Kubernetes提供的存储卷(Volume)属于Pod资源级别,共享于Pod内的所有容器,可用于在容器的文件系统之外存储应用程序的相关数据,甚至 还可独立于Pod的生命周期之外实现数据持久化
Pod本身具有生命周期,故其内部运行的容器及其相关数据自身均无法持久存在。Docker支持 配置容器使用存储卷将数据持久存储于容器自身文件系统之外的存储空间中,它们可以是节点 文件系统或网络文件系统之上的存储空间
Kubernetes也支持类似的存储卷功能,不过其存储卷是与Pod资源绑定而非容器。 简单来说,存储卷是定义在Pod资源之上、可被其内部的所有容器挂载的共享目录,它关联至某外部的存储设备之上的存储空间,从而独立于容器自身的文件系统
通过.spec.volumes字段定义在Pod之上的存储卷列表
通过.spec.containers.volumeMounts字段在容器上定义的存储卷挂载列表,它只能挂载当前 Pod资源中定义的具体存储卷
只有多个容器挂载同一个存储卷时,“ 共享”才有了具体的意义.当Pod中只有一个容器时,使用存储卷的目的通常在于数据持久化
mountPath<string>:挂载点路径,容器文件系统上的路径,必选字段
subPath<string>:挂载存储卷时使用的子路径,即在mountPath指定的路径下使用一个子路径作为其挂载点
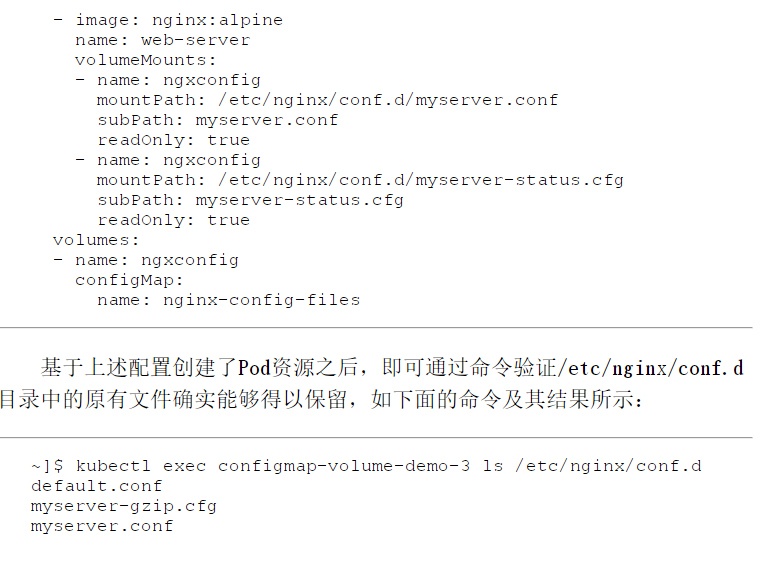
subPath支持用户从存储卷挂载单个文件或单个目录而非整个存储卷。例如,示例就于/etc/nginx/conf.d 目录中单独挂载了两个文件,而保留于了目录下原有的文件
存储类的好处之一便是支持PV的动态创建。用户用到持久性存储时,需要通过创建PVC来绑定 匹配的PV,此类操作需求量较大,或者当管理员手动创建的PV无法满足PVC的所有需求时,系统按 PVC的需求标准动态创建适配的PV会为存储管理带来极大的灵活性
provisioner(供给方):即提供了存储资源的存储系统,存储类要依赖Provisioner来判定要使 用的存储插件以便适配到目标存储系统动态PV供给的启用,需要事先由管理员创建至少一个存储类,不同的Provisoner的创建方法各有不同
任何支持PV动态供给的存储系统都可以在定义为存储类后由PVC动态申请
存储供给(Provisioning)是指为PVC准备可用PV的机制为了支持使用动态供给机制,集群管理员需要为准入控制器(admission controller)启用“ DefaultStorageClass”选项
PVC保护机制
万一有用户删除了仍处于某Pod资源使用中的PVC时,Kubernetes不会立即予以移除,而是 推迟到不再被任何Pod资源使用后方才执行删除操作.处于此种阶段的PVC资源的status字段 为"Termination"
downwardAPI存储卷
Pod对象中的容器化应用偶尔也需要获取其所属Pod对象的IP、主机名、标签、注解、UID、 请求的CPU及内存资源量及其限额,甚至是Pod所在的节点名称
downwardAPI存储卷为Kubernetes上运行容器化应用提供了获取外部环境信息的有效 途径,这一点对那些非为云原生开发的应用程序在不进行代码重构的前提下获取环境信息 进行自身配置等操作时尤为有用
Secret和ConfigMap而且是Kubernetes系统上一等类别的资源对象,它们要么被Pod资源以 存储卷的形式加载,要么由容器通过envFrom字段以变量的形式加载
命令行参数配置容器应用
使用command字段指定要运行的程序,而args字段则可用于指定传递给程序的选项及参数。 在配置文件中定义的command和args会覆盖镜像文件中相关的默认设定,这类程序会被直接 运行,而不会由shell解释器解释运行,因此与shell相关的特性均不被支持,如命令行展开符号{}、重定向等操作
通行的做法是在制作Docker镜像时,为ENTRYPOINT指令定义一个脚本,它能够在启动容器时 将环境变量替换至应用程序的配置文件中,而后再由此脚本启动相应的应用程序。基于这类 镜像运行容器时,即可通过向环境变量(env)传值的方式来配置应用程序

相较于环境变量来说,使用ConfigMap资源为容器应用提供配置的优势之一 在于其支持容器应用动态更新其配置:用户直接更新ConfigMap对象,而后由容器应用重载其配置文件即可

挂载ConfigMap存储卷的挂载点目录中的文件都是符号链接,它们指向了当前目录中的“.. data”,而“.. data”也是符号链接,它指向了名字形如“.. 2018_ 03_ 17_ 14_ 41_ 41. 256460087”的目录,这个目录才是存储卷的真正挂载点
Secret对象主要有两种用途: 一是作为存储卷注入到Pod上由容器应用 程序所使用. 二是用于kubelet为Pod里的容器拉取镜像时向私有仓库提供认证信息
存储是表述持久保存数据的方法,现今通常是指机械硬盘或SSD设备.若进程仅需操作内存中的 数据,则表示其无须进行磁盘I/O操作.如果产生了I/O操作.则通常意味着数据的只读访问或 读写访问行为
StatefulSet(有状态副本集)则是专门用来满足此类应用的控制器类型,由其管控的每个Pod对象都有着固定的主机名和专有存储卷,即便被重构后亦能保持不变
一个典型、完整可用的StatefulSet通常由三个组件构成:Headless Service、StatefulSet 和volumeClaimTemplate.其中Headless Service用于为Pod资源标识符 生成可解析的DNS资源记录,StatefulSet用于管控Pod资源,volumeClaimTemplate则基于 静态或动态的PV供给方式为Pod资源提供专有且固定的存储
StatefulSet控制器默认以串行的方式创建各Pod副本,如果想要以并行方式创建和删除Pod资源,则可以设定.spec.podManagementPolicy字段的值为“ Parallel”,默认值为“OrderedReady”
滚动更新StatefulSet控制器的Pod资源以逆序的形式从其最大索引编号的Pod资源逐一进行,它在终止一个Pod资源、 更新资源并待其就绪后启动更新下一个资源,即索引号比当前号小1的Pod资源.对于主从复制类的集群应用来说,这样也能保证起主节点作用的Pod资源最后进行更新,确保兼容性