join分为:join,left join、right join、full join(mysql中不支持full join,需要用 left join与 reight来合并处理)
接下来我们主要关注下| left join
先用一个案例看下连接条件写在 where 和 on 中的区别
创建表:classes 班级表
CREATE TABLE `classes` ( `id` int NOT NULL AUTO_INCREMENT, `name` varchar(45) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
创建表:students 学生表
CREATE TABLE `students` ( `id` int NOT NULL AUTO_INCREMENT, `class_id` int NOT NULL, `name` varchar(45) NOT NULL, `gender` varchar(45) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=11 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
上述【班级表】与【学生表】为 1对多的关系。
插入数据:
insert into classes values(1,"一班"),(2,"二班"),(3,"三班"),(4,"四班"); insert into students values(1,1,"小明","M"),(2,1,"小红","F"),(3,1,"小军","M"),(4,1,"小米","F"), (5,2,"小白","F"),(6,2,"小兵","M"),(7,2,"小林","M"),(8,3,"小新","F"),(9,3,"小王","M"),(10,3,"小丽","F");
那么现在有两个需求:
(1)找出每个班级的名称及其对应的女同学数量
(2)找出一班的同学总数
对于需求(1),大多数人会想象出两种sql写法
写法1:s.gender='F' 的条件放在 on 中
select c.name,count(s.name) as num from classes c left join students s on c.id = s.class_id and s.gender='F' group by c.name;
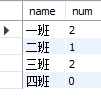
写法2:s.gender='F' 的条件放在 where 里
select c.name,count(s.name) as num from classes c left join students s on c.id = s.class_id where s.gender='F' group by c.name;

对于需求(2),大多数人也会给出两种写法
写法1:c.name='一班' 的条件放在 on 中
select c.name,count(s.name) as num from classes c left join students s on c.id = s.class_id and c.name='一班' group by c.name;
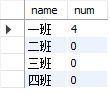
写法2:c.name='一班' 的条件放在 where 里
select c.name,count(s.name) as num from classes c left join students s on c.id = s.class_id where c.name='一班' group by c.name;

由上述两个案例可见,输出是不一样的,接下来我们来看一下 left join 的执行原理
mysql 对于 left join是采用的嵌套循环的方式来进行处理。以下面的语句为例:
SELECT * FROM LT LEFT JOIN RT ON P1(LT,RT)) WHERE P2(LT,RT)
其中,P!是 on 过滤条件,P2是 where 过滤条件。缺失都认为是 true;
该语句的执行逻辑可用以下伪代码描述:
FOR each row lt in LT {// 遍历左表的每一行 BOOL b = FALSE; FOR each row rt in RT such that P1(lt, rt) {// 遍历右表每一行,找到满足join条件的行 IF P2(lt, rt) {//满足 where 过滤条件 t:=lt||rt;//合并行,输出该行 } b=TRUE;// lt在RT中有对应的行 } IF (!b) { // 遍历完RT,发现lt在RT中没有有对应的行,则尝试用null补一行 IF P2(lt,NULL) {// 补上null后满足 where 过滤条件 t:=lt||NULL; // 输出lt和null补上的行 } } }
当然,实际情况中MySQL会使用buffer的方式进行优化,减少行比较次数,不过这不影响关键的执行流程
从这个伪代码我们能看出两点
(1)如果想对右表进行限制,则一定要在on条件中进行,若在where中进行则可能导致数据缺失,导致左表在右表中无匹配行的行在最终结果中不出现,违背了我们对left join的理解。
因为对左表无右表匹配行的行而言,遍历右表后b=FALSE,所以会尝试用NULL补齐右表,但是此时我们的P2对右表行进行了限制,NULL若不满足P2(NULL一般都不会满足限制条件,除非IS NULL这种),则不会加入最终的结果中,导致结果缺失。
(2)如果没有where条件,无论on条件对左表进行怎样的限制,左表的每一行都至少会有一行的合成结果,对左表行而言,若右表若没有对应的行,则右表遍历结束后b=FALSE,会用一行NULL来生成数据,而这个数据是多余的。所以对左表进行过滤必须用where。
总结::在left join语句中,左表过滤必须放where条件中,右表过滤必须放on条件中,这样结果才能不多不少,刚刚好。