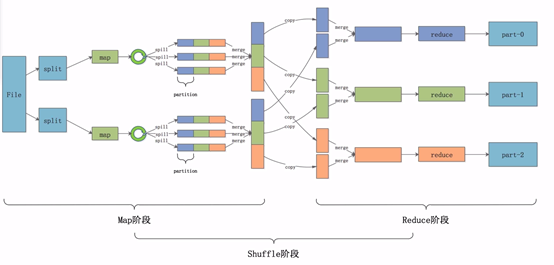
一.Map的原理和运行流程
Map的输入数据源是多种多样的,我们使用hdfs作为数据源。文件在hdfs上是以block(块,Hdfs上的存储单元)为单位进行存储的。
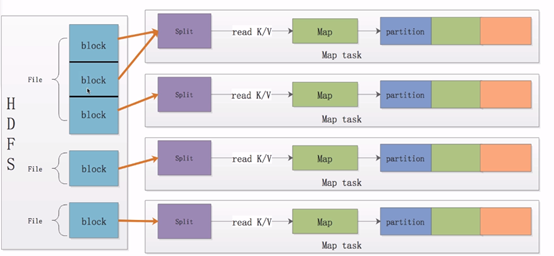
1.分片

我们将这一个个block划分成数据分片,即Split(分片,逻辑划分,不包含具体数据,只包含这些数据的位置信息),那么上图中的第一个Split则对应两个个文件块,第二个Split对应一个块。需要注意的是一个Split只会包含一个File的block,不会跨文件。
2. 数据读取和处理

当我们把数据块分好的时候,MapReduce(以下简称mr)程序将这些分片以key-value的形式读取出来,并且将这些数据交给用户自定义的Map函数处理。
3.

用户处理完这些数据后同样以key-value的形式将这些数据写出来交给mr计算框架。mr框架会对这些数据进行划分,此处用进行表示。不同颜色的partition矩形块表示为不同的partition,同一种颜色的partition最后会分配到同一个reduce节点上进行处理。
Map是如何将这些数据进行划分的?
默认使用Hash算法对key值进行Hash,这样既能保证同一个key值的数据划分到同一个partition中,又能保证不同partition的数据梁是大致相当的。
总结:
1.一个map指挥处理一个Split
2.map处理完的数据会分成不同的partition
3.一类partition对应一个reduce
那么一个mr程序中 map的数量是由split的数量决定的,reduce的数量是由partiton的数量决定的。
二.Shuffle
Shuffle,翻译成中文是混洗。mr没有排序是没有灵魂的,shuffle是mr中非常重要的一个过程。他在Map执行完,Reduce执行前发生。
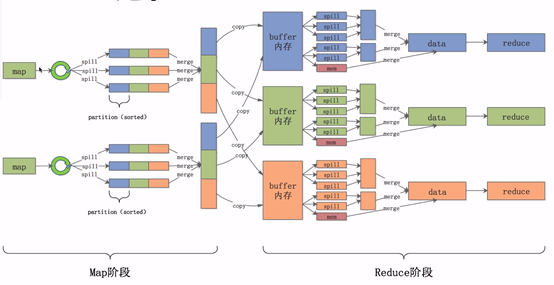
Map阶段的shuffle
数据经过用户自定的map函数处理完成之后,数据会放入内存中的环形缓冲区之内, ,他分为两个部分,数据区和索引区。数据区是存放用户真实的数据,索引区存放数据对应的key值,partition和位置信息。当环形缓冲区数据达到一定的比例后,会将数据溢写到一个文件之中,即途中的spill(溢写)过程。
,他分为两个部分,数据区和索引区。数据区是存放用户真实的数据,索引区存放数据对应的key值,partition和位置信息。当环形缓冲区数据达到一定的比例后,会将数据溢写到一个文件之中,即途中的spill(溢写)过程。
在溢写前,会将数据根据key和partition进行排序,排好序之后会将数据区的数据按照顺序一个个写入文件之中。这样就能保证文件中数据是按照key和parttition进行排序的。最后会将溢写出的一个个小文件合并成一个大的文件,并且保证在每一个partition
中是按照Key值有序的。
总结:
- Collect阶段将数据放进环形缓冲区,缓冲区分为数据区和索引区。
- Sort阶段对在同一partition内的索引按照key排序。
- Spill阶段跟胡排好序的索引将数据按照顺序写到文件中。
- Merge阶段将Spill生成的小文件分批合并排序成一个大文件。
Reduce阶段的shuffle
reduce节点会将数据拷贝到自己的buffer缓存区中,当缓存区中的数据达到一定的比例的时候,同样会发生溢写过程,我们任然要保证每一个溢写的文件是有序的。与此同时,后台会启一个线程,将这些小文件合并成一个大文件,经过一轮又一轮的合并,最后将这些文件合并成一个大的数据集。在这个数据集中,数据是有序的,相同的key值对应的value值是挨在一起的。最后,将这些数据交给reduce程序进行聚合处理。
总结:
- 1. Copy阶段将Map端的数据分批拷贝到Reduce的缓冲区。
- 2. Spill阶段将内存缓存区的数据按顺序写到文件中。
- 3. Merge阶段将溢出的文件合并成一个排序的数据集。
三.Reduce运行过程

在map处理完之后,reduce节点会将各个map节点上属于自己的数据拷贝到内存缓冲区中,最后将数据合并成一个大的数据集,并且按照key值进行聚合,把聚合后的value值作为iterable(迭代器)交给用户使用,这些数据经过用户自定义的reduce函数进行处理之后,同样会以key-value的形式输出出来,默认输出到hdfs上的文件。
四.Combine优化
我们说mr程序最终是要将数据按照key值进行聚合,对value值进行计算,那么我们是不是可以提前对聚合好的value值进行计算?of course,我们将这个过程称为Combine。哪些场景可以进行conbine优化。如下。
Map端:
1. 在数据排序后,溢写到磁盘前,运行combiner。这个时候相同Key值的value值是挨在一起的,可以对这些value值进行一次聚合计算,比如说累加。
2. 溢写出的小文件合并之前,我们也可以执行一次combiner,需要注意的是mr程序默认至少存在三个文件才进行combiner,否则mr会认为这个操作是不值得的。当然这个值可以通过min.num.spills.for.combine设置。
Reduce端:
- 和map端一样,在合并溢出文件输出到磁盘之前,运行combiner。
写在最后
送上整个MR过程图。