TF-IDF
前言
前段时间,又具体看了自己以前整理的TF-IDF,这里把它发布在博客上,知识就是需要不断的重复的,否则就感觉生疏了。
TF-IDF理解
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术, TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF反文档频率(Inverse Document Frequency)。TF表示词条在文档d中出现的频率。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m + k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处.
TF公式:
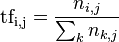
以上式子中  是该词在文件
是该词在文件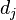 中的出现次数,而分母则是在文件中所有字词的出现次数之和。
中的出现次数,而分母则是在文件中所有字词的出现次数之和。
IDF公式:
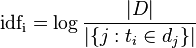
- |D|:语料库中的文件总数
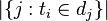 :包含词语
:包含词语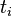 的文件数目(即
的文件数目(即 的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用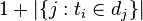
然后

TF-IDF案例
案例:假如一篇文件的总词语数是100个,而词语“母牛”出现了3次,那么“母牛”一词在该文件中的词频就是3/100=0.03。一个计算文件频率 (DF) 的方法是测定有多少份文件出现过“母牛”一词,然后除以文件集里包含的文件总数。所以,如果“母牛”一词在1,000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率就是 lg(10,000,000 / 1,000)=4。最后的TF-IDF的分数为0.03 * 4=0.12。
TF-IDF实现(Java)
这里采用了外部插件IKAnalyzer-2012.jar,用其进行分词,插件和测试文件可以从这里下载:点击
具体代码如下:
package tfidf; import java.io.*; import java.util.*; import org.wltea.analyzer.lucene.IKAnalyzer; public class ReadFiles { /** * @param args */ private static ArrayList<String> FileList = new ArrayList<String>(); // the list of file //get list of file for the directory, including sub-directory of it public static List<String> readDirs(String filepath) throws FileNotFoundException, IOException { try { File file = new File(filepath); if(!file.isDirectory()) { System.out.println("输入的[]"); System.out.println("filepath:" + file.getAbsolutePath()); } else { String[] flist = file.list(); for(int i = 0; i < flist.length; i++) { File newfile = new File(filepath + "\" + flist[i]); if(!newfile.isDirectory()) { FileList.add(newfile.getAbsolutePath()); } else if(newfile.isDirectory()) //if file is a directory, call ReadDirs { readDirs(filepath + "\" + flist[i]); } } } }catch(FileNotFoundException e) { System.out.println(e.getMessage()); } return FileList; } //read file public static String readFile(String file) throws FileNotFoundException, IOException { StringBuffer strSb = new StringBuffer(); //String is constant, StringBuffer can be changed. InputStreamReader inStrR = new InputStreamReader(new FileInputStream(file), "gbk"); //byte streams to character streams BufferedReader br = new BufferedReader(inStrR); String line = br.readLine(); while(line != null){ strSb.append(line).append(" "); line = br.readLine(); } return strSb.toString(); } //word segmentation public static ArrayList<String> cutWords(String file) throws IOException{ ArrayList<String> words = new ArrayList<String>(); String text = ReadFiles.readFile(file); IKAnalyzer analyzer = new IKAnalyzer(); words = analyzer.split(text); return words; } //term frequency in a file, times for each word public static HashMap<String, Integer> normalTF(ArrayList<String> cutwords){ HashMap<String, Integer> resTF = new HashMap<String, Integer>(); for(String word : cutwords){ if(resTF.get(word) == null){ resTF.put(word, 1); System.out.println(word); } else{ resTF.put(word, resTF.get(word) + 1); System.out.println(word.toString()); } } return resTF; } //term frequency in a file, frequency of each word public static HashMap<String, Float> tf(ArrayList<String> cutwords){ HashMap<String, Float> resTF = new HashMap<String, Float>(); int wordLen = cutwords.size(); HashMap<String, Integer> intTF = ReadFiles.normalTF(cutwords); Iterator iter = intTF.entrySet().iterator(); //iterator for that get from TF while(iter.hasNext()){ Map.Entry entry = (Map.Entry)iter.next(); resTF.put(entry.getKey().toString(), Float.parseFloat(entry.getValue().toString()) / wordLen); System.out.println(entry.getKey().toString() + " = "+ Float.parseFloat(entry.getValue().toString()) / wordLen); } return resTF; } //tf times for file public static HashMap<String, HashMap<String, Integer>> normalTFAllFiles(String dirc) throws IOException{ HashMap<String, HashMap<String, Integer>> allNormalTF = new HashMap<String, HashMap<String,Integer>>(); List<String> filelist = ReadFiles.readDirs(dirc); for(String file : filelist){ HashMap<String, Integer> dict = new HashMap<String, Integer>(); ArrayList<String> cutwords = ReadFiles.cutWords(file); //get cut word for one file dict = ReadFiles.normalTF(cutwords); allNormalTF.put(file, dict); } return allNormalTF; } //tf for all file public static HashMap<String,HashMap<String, Float>> tfAllFiles(String dirc) throws IOException{ HashMap<String, HashMap<String, Float>> allTF = new HashMap<String, HashMap<String, Float>>(); List<String> filelist = ReadFiles.readDirs(dirc); for(String file : filelist){ HashMap<String, Float> dict = new HashMap<String, Float>(); ArrayList<String> cutwords = ReadFiles.cutWords(file); //get cut words for one file dict = ReadFiles.tf(cutwords); allTF.put(file, dict); } return allTF; } public static HashMap<String, Float> idf(HashMap<String,HashMap<String, Float>> all_tf){ HashMap<String, Float> resIdf = new HashMap<String, Float>(); HashMap<String, Integer> dict = new HashMap<String, Integer>(); int docNum = FileList.size(); for(int i = 0; i < docNum; i++){ HashMap<String, Float> temp = all_tf.get(FileList.get(i)); Iterator iter = temp.entrySet().iterator(); while(iter.hasNext()){ Map.Entry entry = (Map.Entry)iter.next(); String word = entry.getKey().toString(); if(dict.get(word) == null){ dict.put(word, 1); }else { dict.put(word, dict.get(word) + 1); } } } System.out.println("IDF for every word is:"); Iterator iter_dict = dict.entrySet().iterator(); while(iter_dict.hasNext()){ Map.Entry entry = (Map.Entry)iter_dict.next(); float value = (float)Math.log(docNum / Float.parseFloat(entry.getValue().toString())); resIdf.put(entry.getKey().toString(), value); System.out.println(entry.getKey().toString() + " = " + value); } return resIdf; } public static void tf_idf(HashMap<String,HashMap<String, Float>> all_tf,HashMap<String, Float> idfs){ HashMap<String, HashMap<String, Float>> resTfIdf = new HashMap<String, HashMap<String, Float>>(); int docNum = FileList.size(); for(int i = 0; i < docNum; i++){ String filepath = FileList.get(i); HashMap<String, Float> tfidf = new HashMap<String, Float>(); HashMap<String, Float> temp = all_tf.get(filepath); Iterator iter = temp.entrySet().iterator(); while(iter.hasNext()){ Map.Entry entry = (Map.Entry)iter.next(); String word = entry.getKey().toString(); Float value = (float)Float.parseFloat(entry.getValue().toString()) * idfs.get(word); tfidf.put(word, value); } resTfIdf.put(filepath, tfidf); } System.out.println("TF-IDF for Every file is :"); DisTfIdf(resTfIdf); } public static void DisTfIdf(HashMap<String, HashMap<String, Float>> tfidf){ Iterator iter1 = tfidf.entrySet().iterator(); while(iter1.hasNext()){ Map.Entry entrys = (Map.Entry)iter1.next(); System.out.println("FileName: " + entrys.getKey().toString()); System.out.print("{"); HashMap<String, Float> temp = (HashMap<String, Float>) entrys.getValue(); Iterator iter2 = temp.entrySet().iterator(); while(iter2.hasNext()){ Map.Entry entry = (Map.Entry)iter2.next(); System.out.print(entry.getKey().toString() + " = " + entry.getValue().toString() + ", "); } System.out.println("}"); } } public static void main(String[] args) throws IOException { // TODO Auto-generated method stub String file = "D:/testfiles"; HashMap<String,HashMap<String, Float>> all_tf = tfAllFiles(file); System.out.println(); HashMap<String, Float> idfs = idf(all_tf); System.out.println(); tf_idf(all_tf, idfs); } }
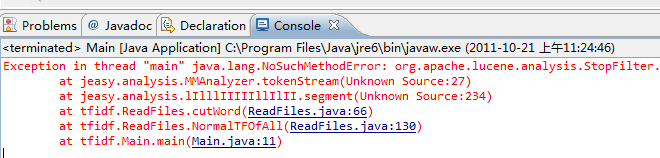
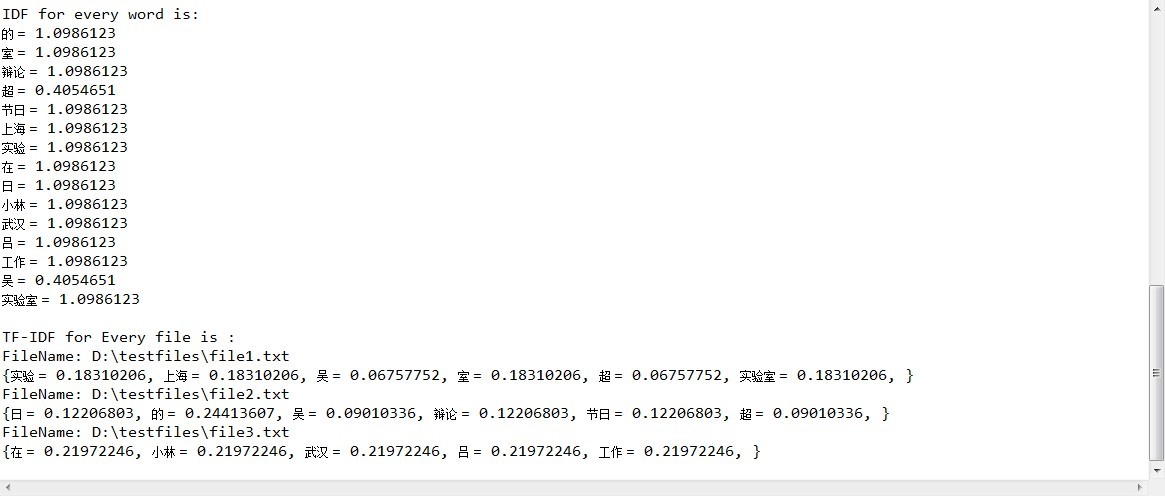
结果如下图:
常见问题
没有加入lucene jar包
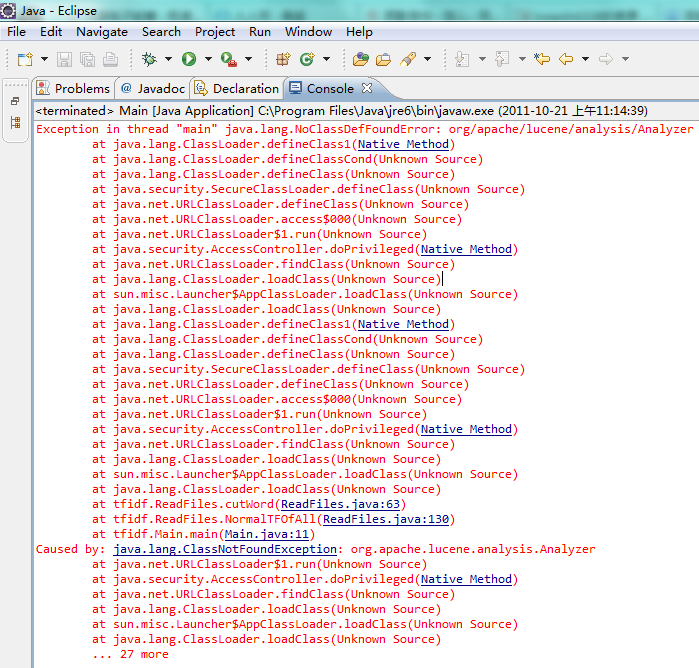
lucene包和je包版本不适合