章节二:HTML基础
1. 爬虫,从网页开始
1.1 为什么要学习HTML?
按道理来说,下面该学习爬虫的第1步: 数据解析了吧?
别急别急,心急爬不了热豆腐。在此之前,先来道送分题,我们要的数据藏哪里来着?
藏在网页当中,对吧。上一节课,老师提到,当我们在Chrome浏览器上,拿着url向服务器发出请求的时候,服务返回的是一个带有HTML文档的数据包,经过浏览器解析,网页才能在窗口上正常呈现。
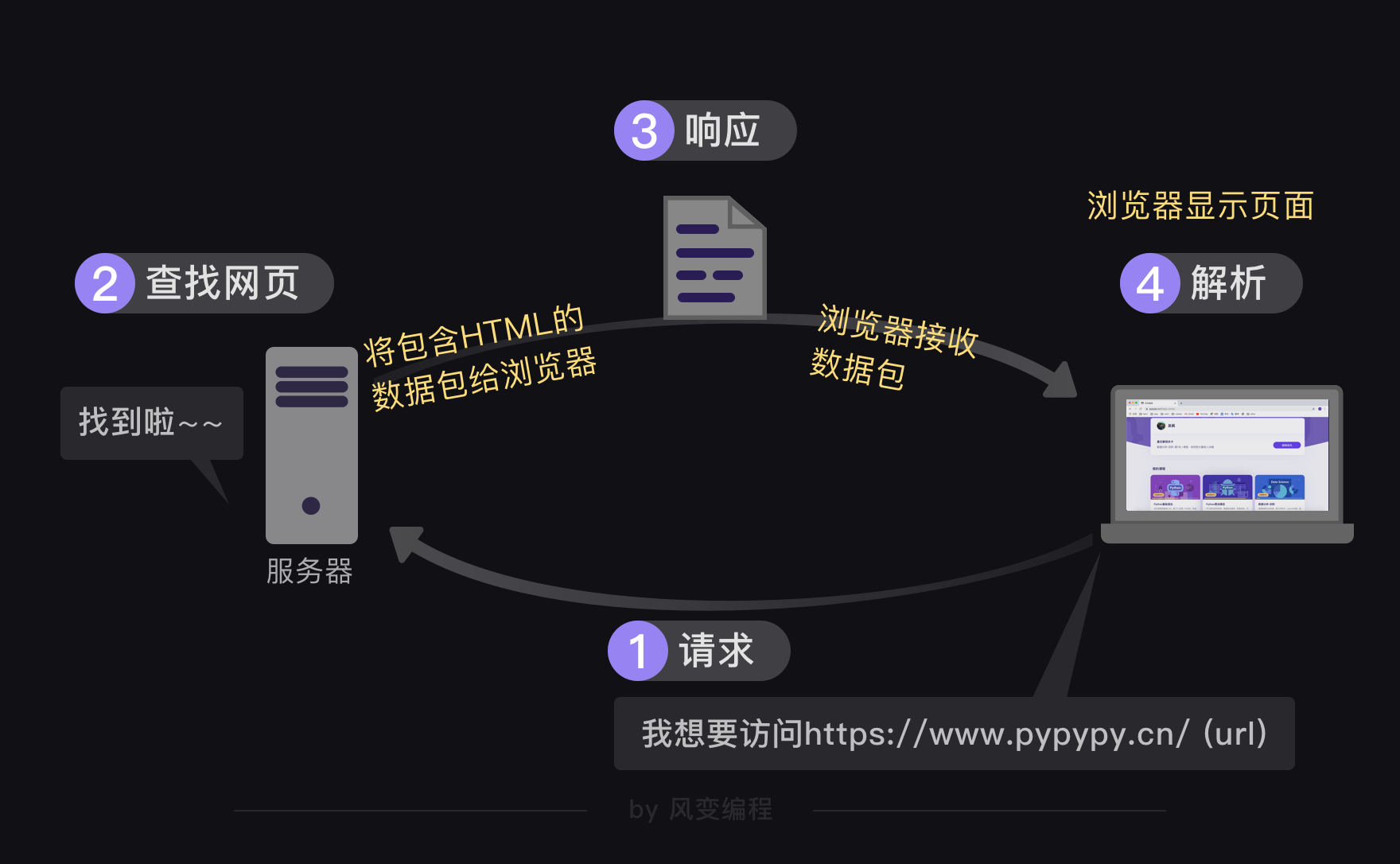
哎?发现问题没,python可没有内置Chrome浏览器啊。
也就是说,我们在用python请求了远程服务器之后,拿到的内容,最常见的,会是一份原汁原味的HTML文档。
如果把HTML的学习依序分为三个层次的话,应该是读懂、修改、编写。
【读懂】:可以说,HTML是踏入爬虫世界的第一步,在这个的基础上,我们才有可能运用Python模块解析数据和提取数据。这一步,你会解锁打开网页的新姿势。比如找到B站首页的logo彩蛋。
【修改】:在读懂的基础上,学会修改HTML代码,可以做些有趣的事情的,比如修改我偶像在社交网站上的简介:
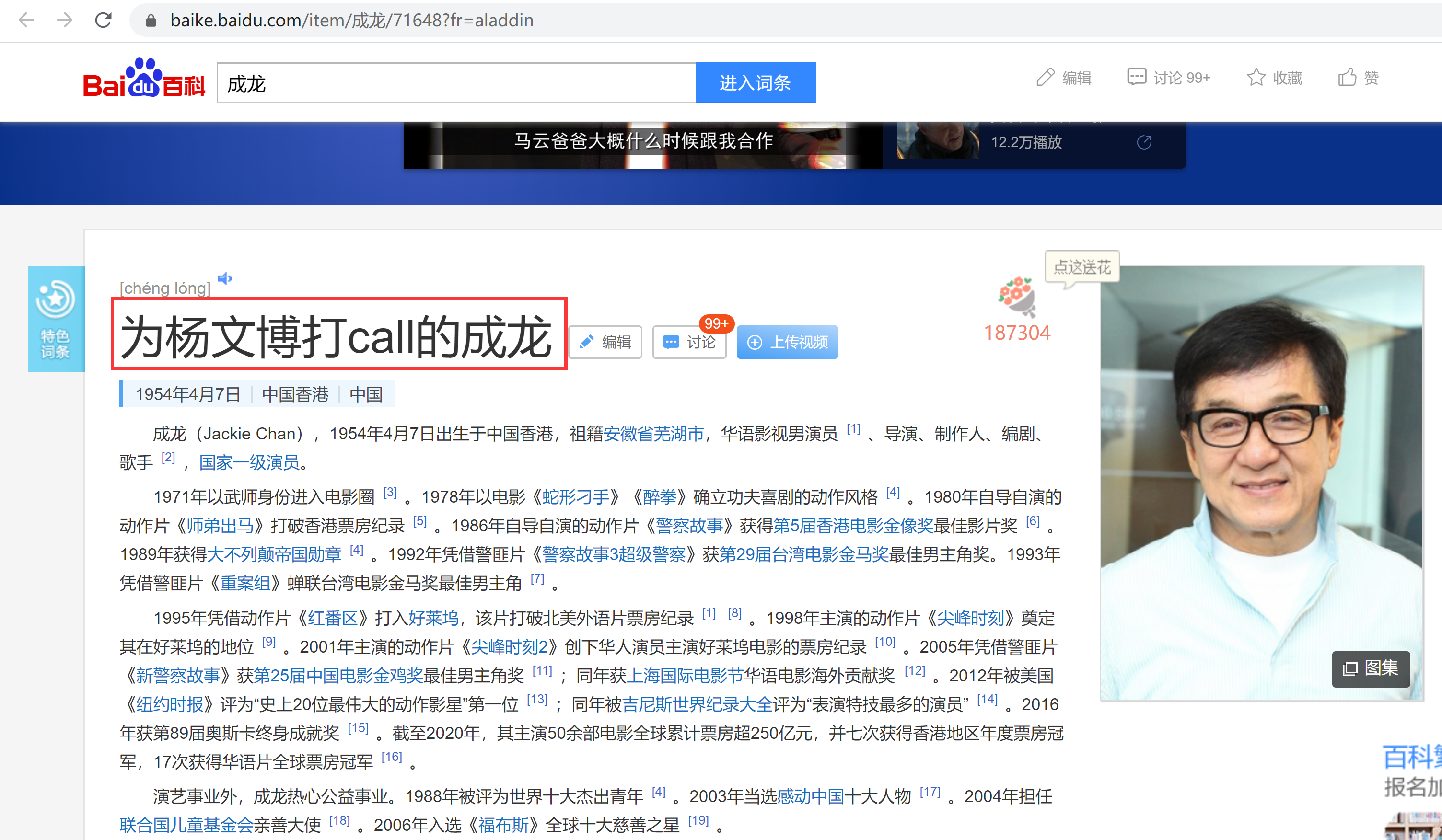
【编写】:如果技术达到了这个水平,那就可以去应聘初级前端工程师了。
当我们使用python拿到一份html文档后,毫无疑问,只有看懂且能对其进行简单分析,才能从中获取我们想要的信息。
所以,我们这一关的学习目标只要达到前两者,能够读懂、修改我们的学习网站这个书苑不太冷即可。
好,那马上开始今天的学习吧!
1.2 什么是HTML
HTML是用来描述网页的一种语言,英文全称是Hyper Text Markup Language,也叫超文本标记语言。
等等,你问什么是标记语言?
标记语言就是把文本和文本以外的相关信息(例如大小,高度,颜色,位置等)组合在一起的语言。
嗯...组合什么?怎么组合?
这几个问题会在接下来的课程中得到解答,现在请你带着这些疑惑,跟我到网页上一探究竟,上车!
1.3 查看网页源码
Talk is cheap,Show you the code. 话不多说,先验货。来看看漂亮的网页背后的HTML文档,请一步一步跟着我操作。
【注:下面我们的示范,会用谷歌浏览器(Chrome)进行演示】
随机打开一个网站,老师课堂上会用教学网站来演示,你也可以打开其他网站,诸如知乎、百度、淘宝等。
这个书苑不太冷:https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html
在网页任意地方点击鼠标右键,然后点击“显示网页源代码”。(Windows系统的电脑还可以使用快捷键ctrl+u来查看网页源代码)
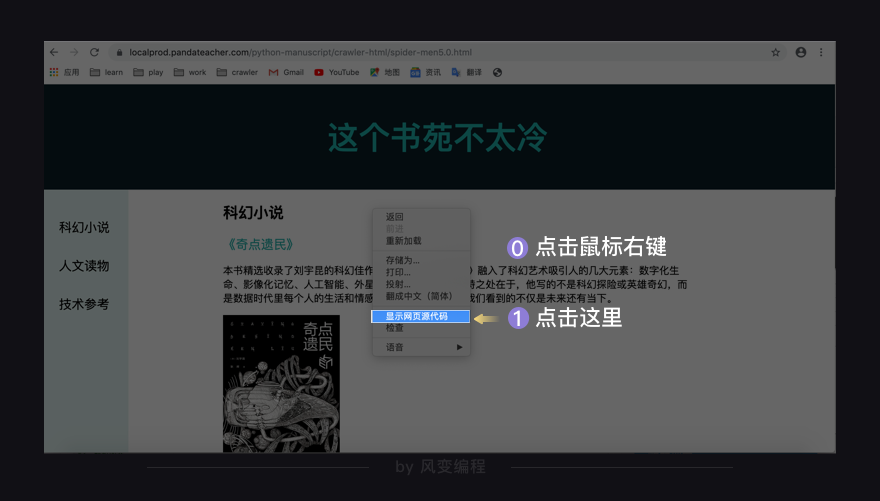
如果浏览器弹出了一个新的标签页,内容形式如下,那错不了,该网页是用HTML文档写的!
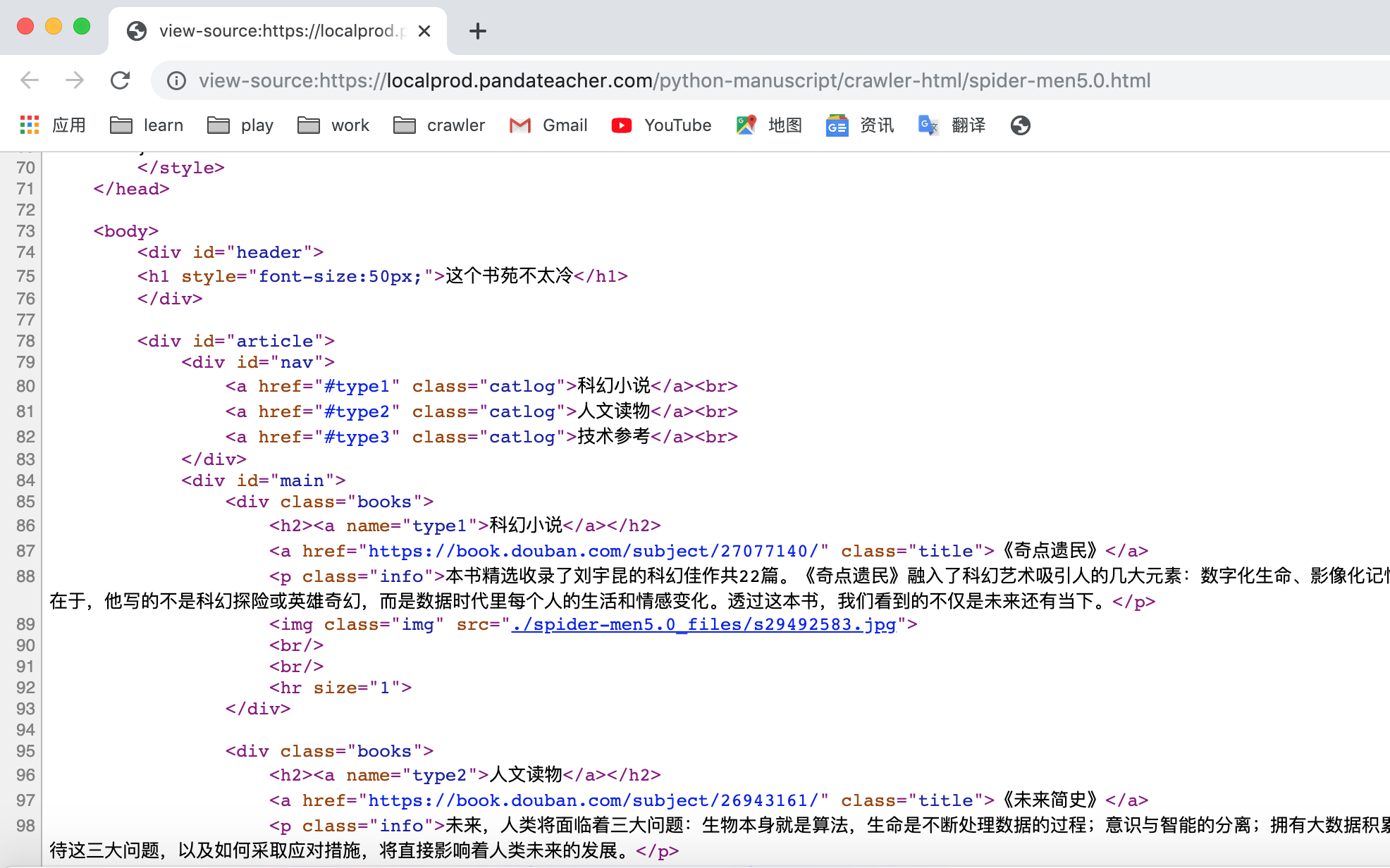
2. HTML的组成
看起来有点复杂?不怕,事实上,HTML文档在编程界是有名的软萌可推。不信?来看一份基础的HTML文档。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
风变一下,你就学到
</body>
</html>
对,这个看上去很简单的程序就是整个HTML的基本架势,我们先熟悉一下它的格式,不用纠结代码具体的意思。
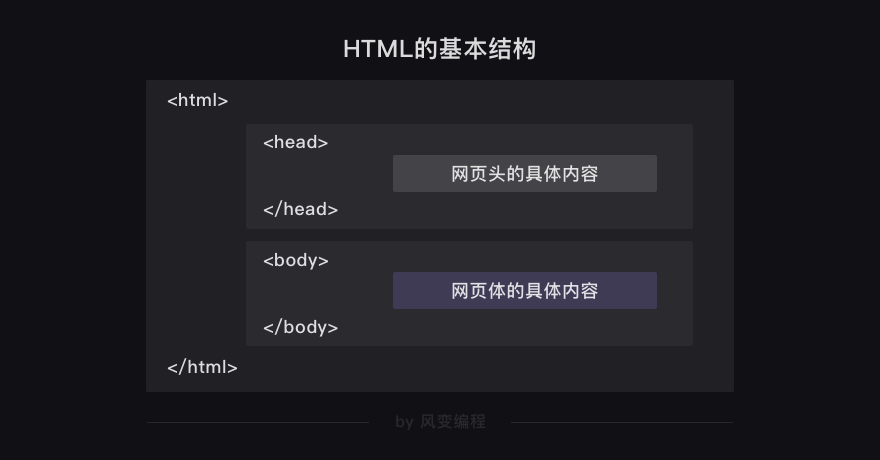
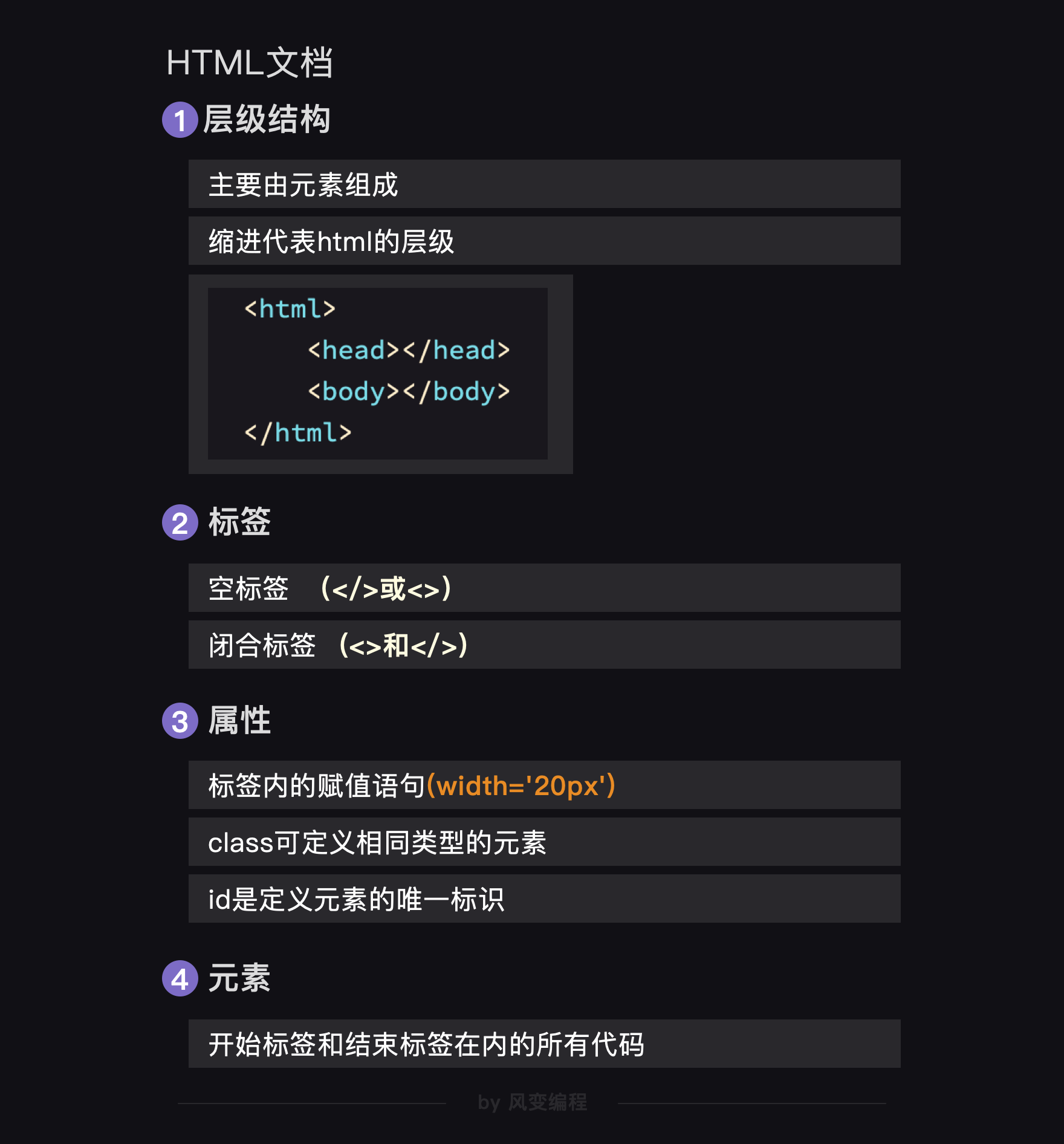
HTML文档主要由元素组成。
第一行<!DOCTYPE html>是一个全局声明,目的是告诉浏览器,你现在处理的这个文档是HTML文档。
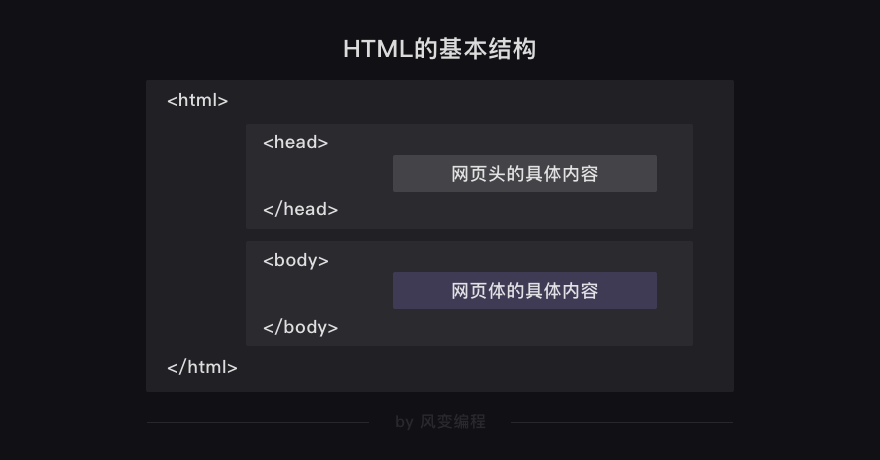
声明过后,迎来了HTML代码的主战场,一共有三组基本元素,分别是html元素(<html></html>),head头元素(<head></head>),和body主体元素(<body></body>)。
它们成对出现,都带有尖括号(<>&</>),分别代表着元素的起点和终点。
最外层是<html>(文档起点)</html>(文档终点),它的作用是标记文档的起始位置和终止位置,从层级上来看,显然是老大,将<head></head>(头部)和<body></body>(主题)包裹了起来。
看到这里,你会发现,HTML文档就好像一个勾勒好头部和身体位置的人体。

当然,人生在世,只有简单的“轮廓”是不够的,需再勾画些“器官”,穿些漂亮衣服,学习一些行为动作,才不虚此行。html亦是如此,下面,让它展露下自己的一鳞半甲。
前面我们说,HTML文档可以容纳更加丰富的信息,于是,老师在原来的基础上撒点料,变成了这样(体验一下,不必细究具体某块代码的意思):
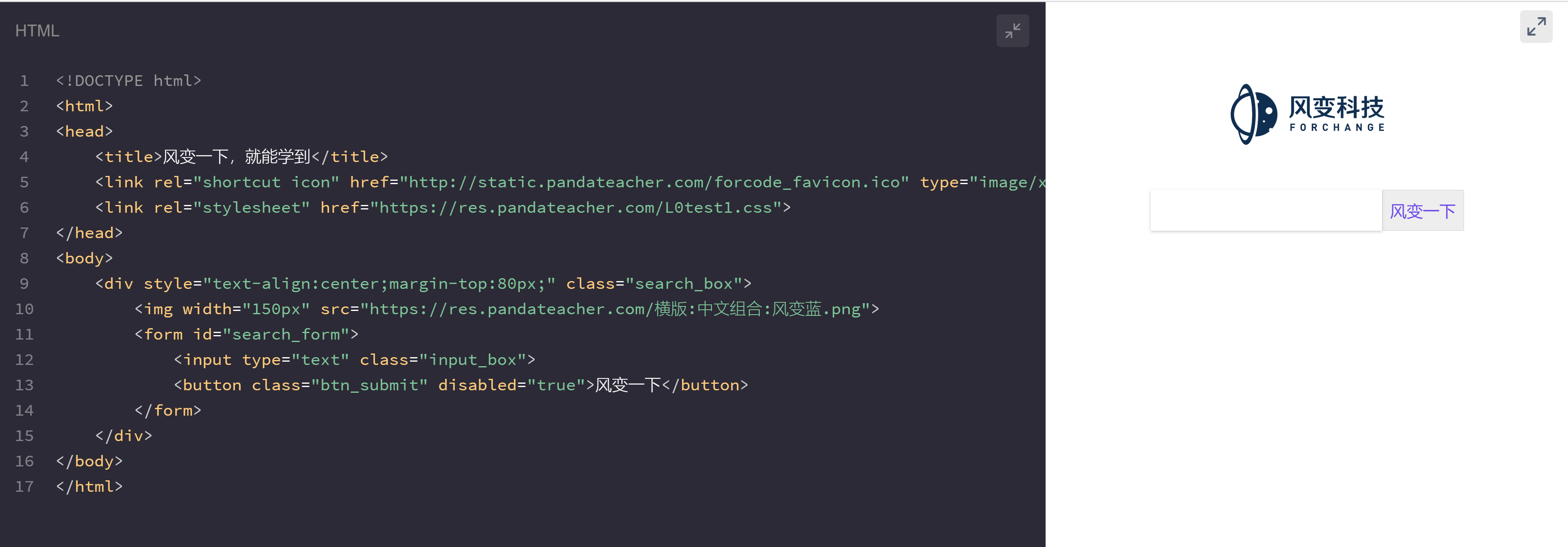
<!DOCTYPE html>
<html>
<head>
<title>风变一下,就能学到</title>
<link rel="shortcut " href="http://static.pandateacher.com/forcode_fav.ico" type="image/x-">
<link rel="stylesheet" href="https://res.pandateacher.com/L0test1.css">
</head>
<body>
<div style="text-align:center;margin-top:80px;" class="search_box">
<img width="150px" src="https://res.pandateacher.com/横版:中文组合:风变蓝.png">
<form id="search_form">
<input type="text" class="input_box">
<button class="btn_submit" disabled="true">风变一下</button>
</form>
</div>
</body>
</html>
事情似乎变得有趣起来了,粗略地阅读代码框架,大致能得到如下信息:
2.1 层级结构
HTML和python一样,【有缩进】,这缩进将文档之间的那点结构层级安排地明明白白。
以我们人体为例,每颗头,都有眼睛、耳朵、鼻子,嘴唇、头发(好像不一定?)。而每双眼睛,又由眼睫毛、眼皮、眼球等结构组成。
生活如斯,在数据的世界中,分层级的组织规则和作用会更加明显。
譬如,头部元素(<head></head>)内,一般会被用来设置网页的编码,添加网页标签的小logo,小标题,外部文件引用(就好像python会用import引用别的模块)等。
其次,HTML文档的主体元素(<body></body>)负责定义网页窗口内的所有内容,同时也是今后我们重点关注的对象。
在这里,主体元素(<body></body>)的腹中只有一个div元素(<div></div>),而div元素(<div></div>)手下有两个“关节”:图片元素(<img/>)和表单元素(<form></form>),表单元素(<form></form>)也有两节“骨头”,分别是input元素(<input/>)和按钮元素(<button>)。
以上便是这份HTML文档的层级结构。
除了尖括号的英文外,似乎还暗藏着许多"赋值语句"(如width='200px')。这和尖括号的英文字符或字母(<img />)有什么关系?如何区分?
要捋清楚它们其实很容易,总结起来就两类东西:标签和属性,接下来我们会挨个讲解。
2.2 标签
标签用于标记文本信息,指用尖括号(<>和</>)括起来的字母和英文,形式有两种:闭合标签和空标签。
闭合标签,它们绝大多数成对出现(有开始标签<>,也有结束标签</>),如:<title>和</title>是标题标签,<div>和</div>是块标签,<form>和</form>是表单标签。
空标签,顾名思义,指那些“孤苦伶仃”的单标签,它们“形影单只”只有一个尖括号<>(斜杠/可省略),标签开始即结束,比如上面的<img />是图片标签,<link />是链接标签,<input />是input标签。
值得注意的是,不要把标签与我们前文讲的元素混淆了哦,前面我们说的元素,其实是包含了开始标签与结束标签内的所有代码。如html元素是指<html></html>包括标签内的所有代码。
通过标签的英文名,我们大致能猜测出它的作用:给浏览器介绍文本的结构。你看<img/>这个位置,我打算放一张图片,那个<form></form>里面我塞的是一张表单。
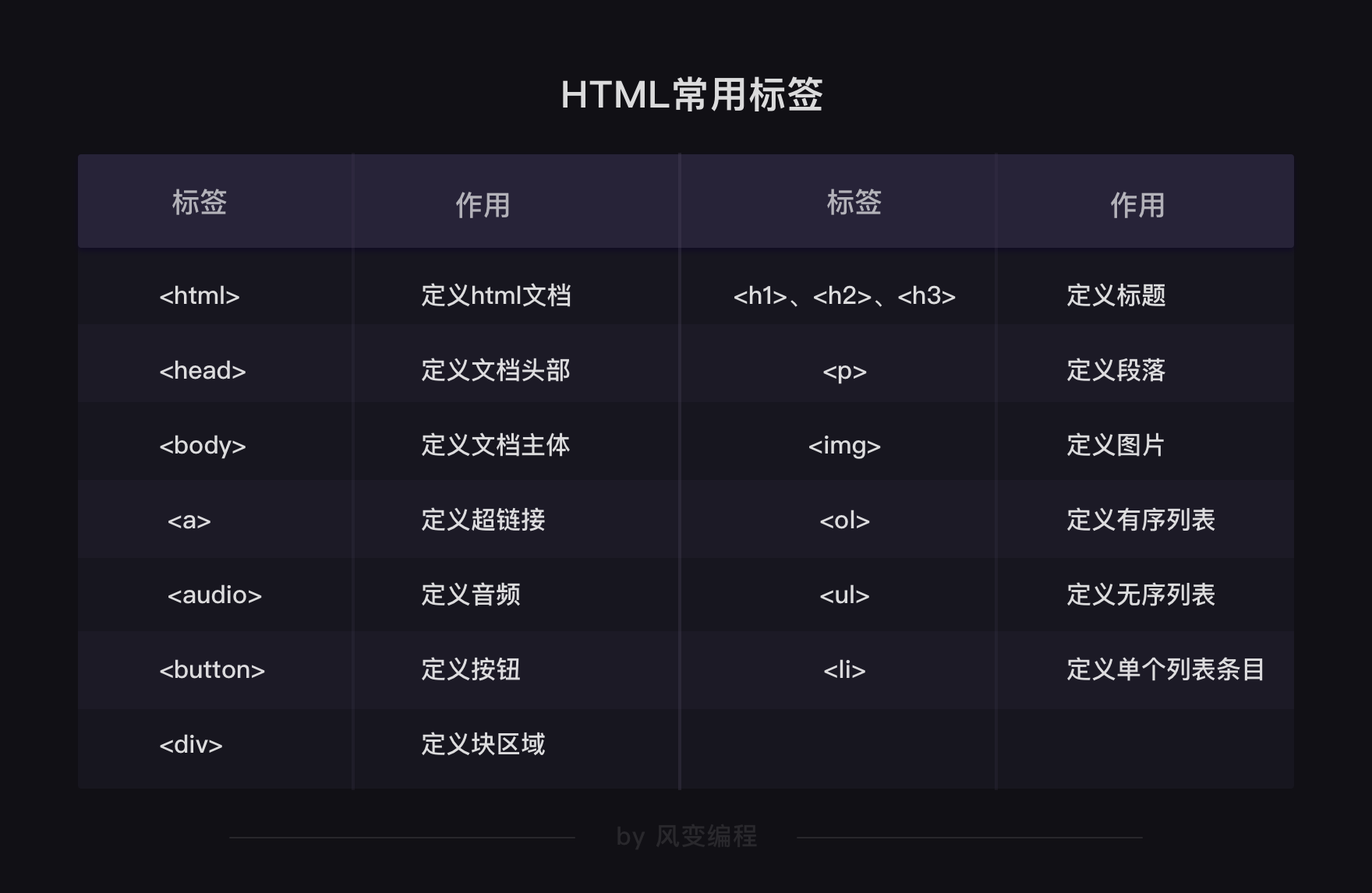
HTML文档含有许多标签,我们不必记住它们,了解几个常用的,混个脸熟即可,有兴趣的同学可以课后翻阅相关的文档(HTML标签)。
用标签给文本标记好了之后,浏览器开始发问了,年轻的程序员哟,你要的是这个金色的标题,还是这个银色的标题,还是这个五颜六色的标题?

想更加详细生动地描述乏味的标签,需要向标签注入点“形容词”,大的还是小的?长的还是高的?什么颜色?
总而言之,是要刻画元素的属性,给html的骨架增添点漂亮的“衣服”。(注意:HTML的属性和Python中的属性不是一个东西)。
2.3 属性
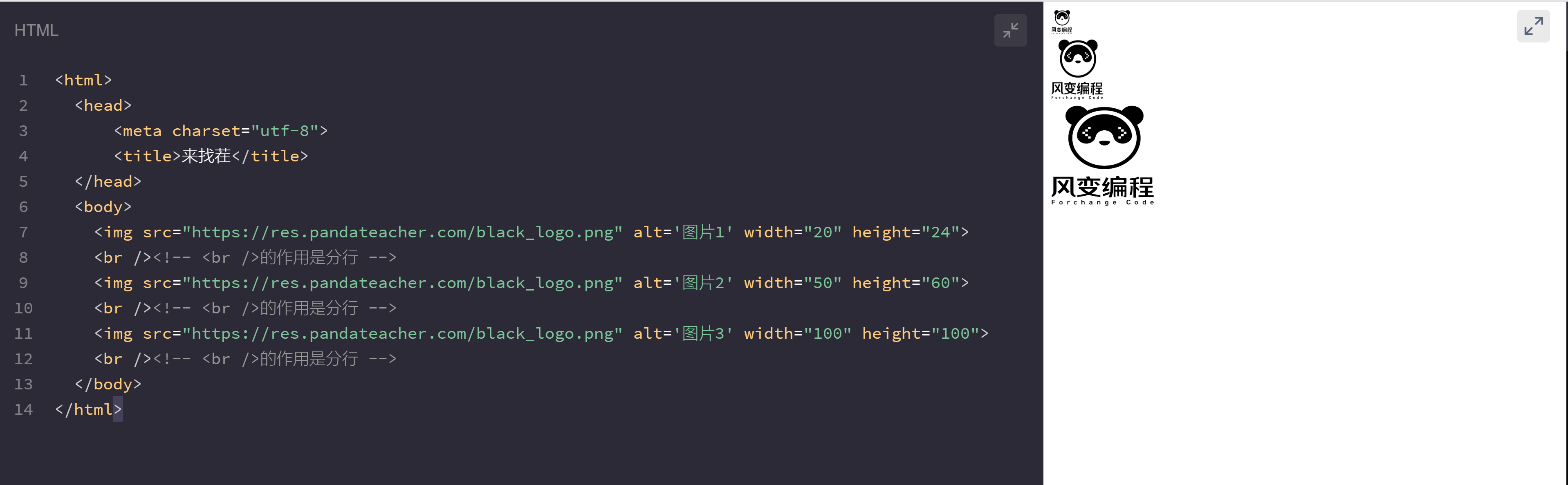
正式介绍属性之前,来玩一个“找茬”游戏吧!请你尝试寻找body元素(<body></body>)内三条图片标签<img />间的不同之处,然后运行一下代码,比较一下两者之间的样式差异。
提示:<!-- -->作用相当于python中的#,是HTML的注释方式。
<html>
<head>
<meta charset="utf-8">
<title>来找茬</title>
</head>
<body>
<img src="https://res.pandateacher.com/black_logo.png" alt='图片1' width="20" height="24">
<br /><!-- <br />的作用是分行 -->
<img src="https://res.pandateacher.com/black_logo.png" alt='图片2' width="50" height="60">
<br /><!-- <br />的作用是分行 -->
<img src="https://res.pandateacher.com/black_logo.png" alt='图片3' width="100" height="100">
<br /><!-- <br />的作用是分行 -->
</body>
</html>
三个熊猫头大小各异,这其实是赋值语句width='xx'和height='xx'的功劳,width属性可以描述图片的宽。height属性能控制图片的高度,两相结合,图片的大小任人摆布。
除此之外,还有设置图片链接的src属性(src='xx'),alt属性可编辑当图片无法显示时的替代文本,它们的独有的特征是:都由赋值语句构成。

现在,相信你对属性和标签有了一定的认识,来检验一下学习成果吧~
<h1 style="color: #20b2aa;">这个书苑不太冷</h1>
<h2 align='center'>吴枫喜欢的书:</h2>
<div>
<img height='200px' style='margin-right: 20px;' src="https://res.pandateacher.com/book_qidianyimin.jpg" alt="奇点遗民">
<div>
<h4>《奇点遗民》</h4>
<p style='color:#4c4a4a;'>本书精选收录了刘宇昆的科幻佳作共22篇...</p>
<a href="https://wordpress-edu-3autumn.localprod.oc.forchange.cn/">点这里看看</a>
</div>
</div>
属性的书写方式(赋值)让人一目了然,却也有一个致命的问题,若一个的元素具有多个属性(如大小、颜色、间距、对齐方式),结构就会变得十分冗杂,严重影响阅读体验,像这样:
<h1 font-weight='bold' align='center' letter-spacing='2px' style="color: #20b2aa;">这个书苑不太冷</h1>
倒是有个通用的style属性能把所有的样式以键值对的形式收集起来,像这样:
<h1 style="font-weight:bold;text-align:center;letter-spacing:2px;color: #20b2aa;">这个书苑不太冷</h1>
可是,这样“长篇累牍”的代码还是不够优雅。于是,集勤劳与智慧于一身的程序员一不做二不休,干脆将style属性样式全部抽离出来。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<style>
/*规定h1的具体样式*/
h1 {
font-weight: bold;/*控制元素字体粗细*/
text-align: center;/*控制元素对齐方式*/
letter-spacing: 2px;/*控制元素对齐方式*/
color: #20b2aa;/*控制元素的颜色*/
}
</style>
</head>
<body>
<h1>这个书苑不太冷</h1>
</body>
</html>
如此,分工明确,各司其职。标签<h1>只管增添文本内容,文本样式的控制权交给head元素的<style>标签。
<style>
/*规定h1的具体样式*/
h1 {
font-weight: bold;/*控制元素字体粗细*/
text-align: center;/*控制元素对齐方式*/
letter-spacing: 2px;/*控制元素对齐方式*/
color: #20b2aa;/*控制元素的颜色*/
}
</style>
h1 {}的内容,是h1元素样式的具体描述,比如text-align: center;,而/*控制元素对齐方式*/是对代码的注释。
好景不长,很快就有人就提出了质疑:这不是一刀切么,所有的h1元素都一个模样,倘若第二个h1元素想保持原有的样式可不就尴尬了?
为了解决这个问题,HTML文档诞生了两个最为特殊的元素:class和id。
2.4 属性:class&id
讲解它们的作用之前,我们再来思考一个场景:如果网页需要排版多张大小不同的图片,它们的属性应该怎么设置?

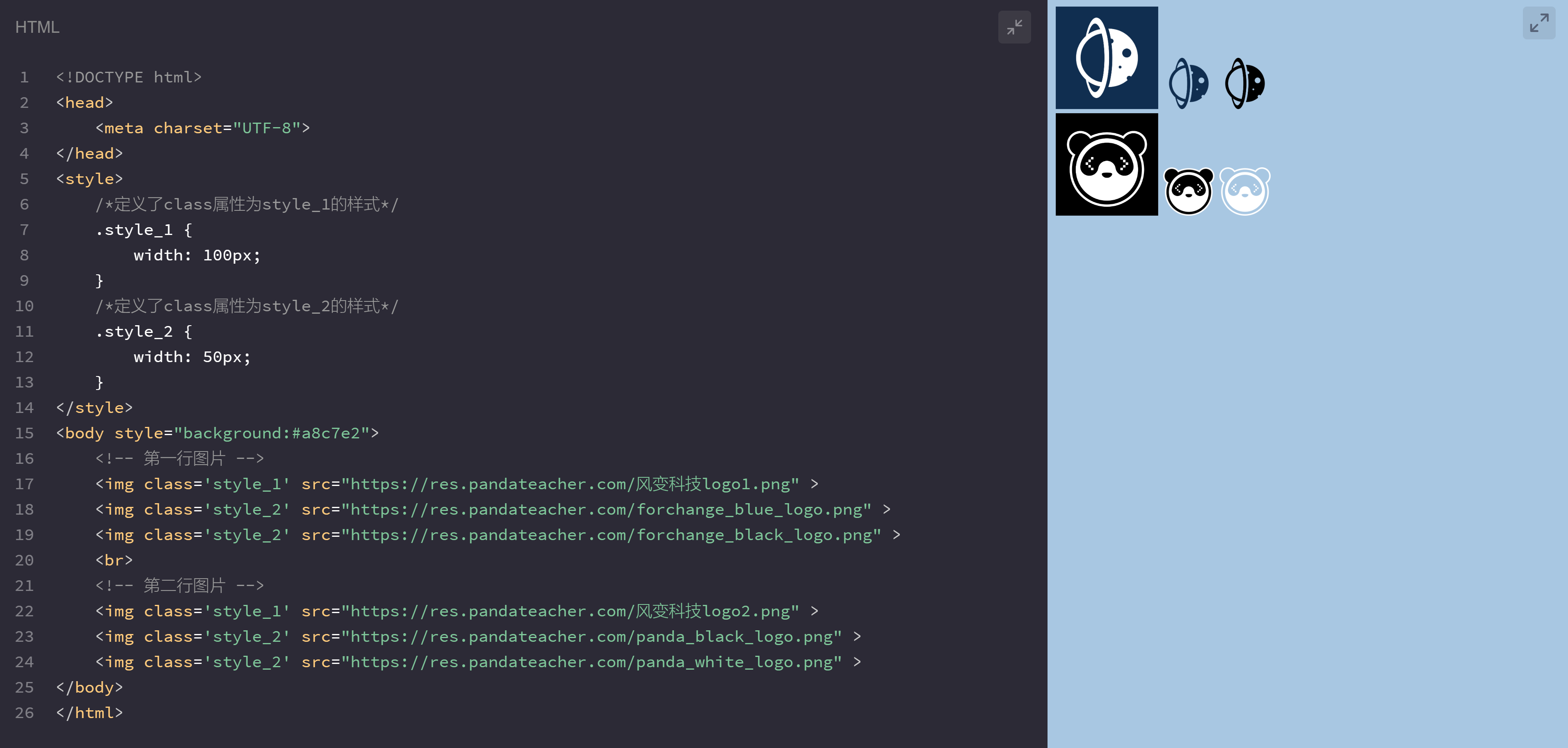
譬如上面这几张图片的排版,每行第一张图片宽度为100像素(width=100px),其余的图片的宽度为50像素(width=50px)。
直接设置img元素的样式,似乎有些不妥。那给每个logo的<img />标签都标注宽高?试想,电商网站有成千上万张图片,都这么干的话,某宝的前端程序员单是图片处理就已过劳而秃了吧。
怎么办?如果我们用的是python代码,遇到类似的事情会怎么做?
还记得类吗?在python中,可将相同的属性和方法的对象抽象成类,关键词是class。

在HTML文档中,我们也有一个关键词为class的属性,class属性值相同的元素可复用同一套样式。
经观察发现,上面的六张图片,可根据它们的宽度进行简单分类,宽度是100像素(width=100px)为一类,宽度为50像素(width=50px)是另一类。
<!DOCTYPE html>
<head>
<meta charset="UTF-8">
</head>
<style>
/*定义了class属性为style_1的样式*/
.style_1 {
100px;
}
/*定义了class属性为style_2的样式*/
.style_2 {
50px;
}
</style>
<body style="background:#a8c7e2">
<!-- 第一行图片 -->
<img class='style_1' src="https://res.pandateacher.com/风变科技logo1.png" >
<img class='style_2' src="https://res.pandateacher.com/forchange_blue_logo.png" >
<img class='style_2' src="https://res.pandateacher.com/forchange_black_logo.png" >
<br>
<!-- 第二行图片 -->
<img class='style_1' src="https://res.pandateacher.com/风变科技logo2.png" >
<img class='style_2' src="https://res.pandateacher.com/panda_black_logo.png" >
<img class='style_2' src="https://res.pandateacher.com/panda_white_logo.png" >
</body>
</html>
上面,我们创建了两套样式,图片class属性值为style_1,获得<style>标签中的.style_1样式,其余class属性值为style_2的图片抱走.style_2的样式。
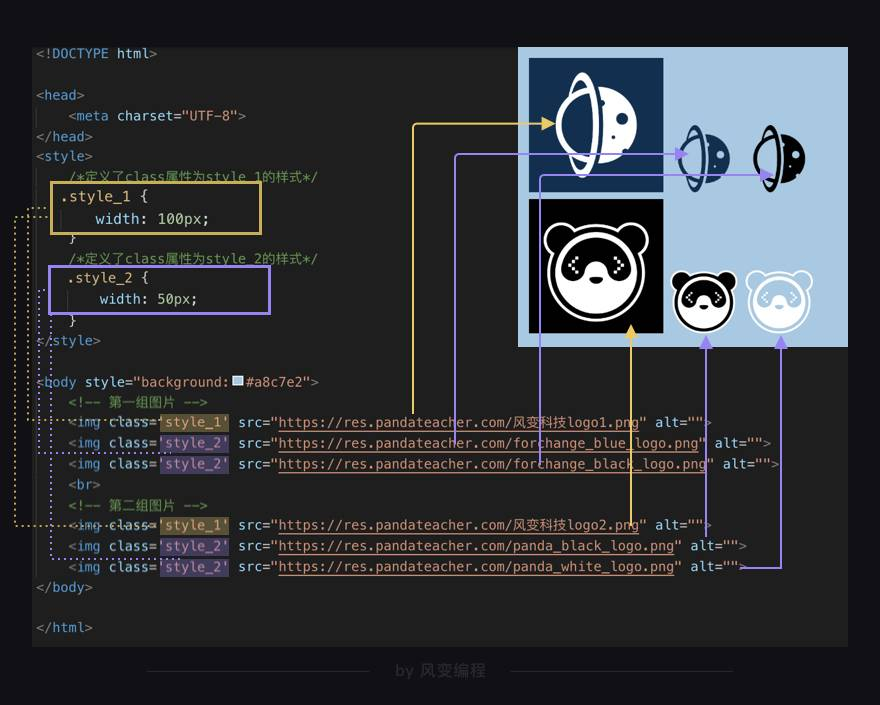
我们可以这么理解:class属性的作用是给元素增添类名,多个元素可配置一个类名,类名相同的元素沿袭同一套样式。
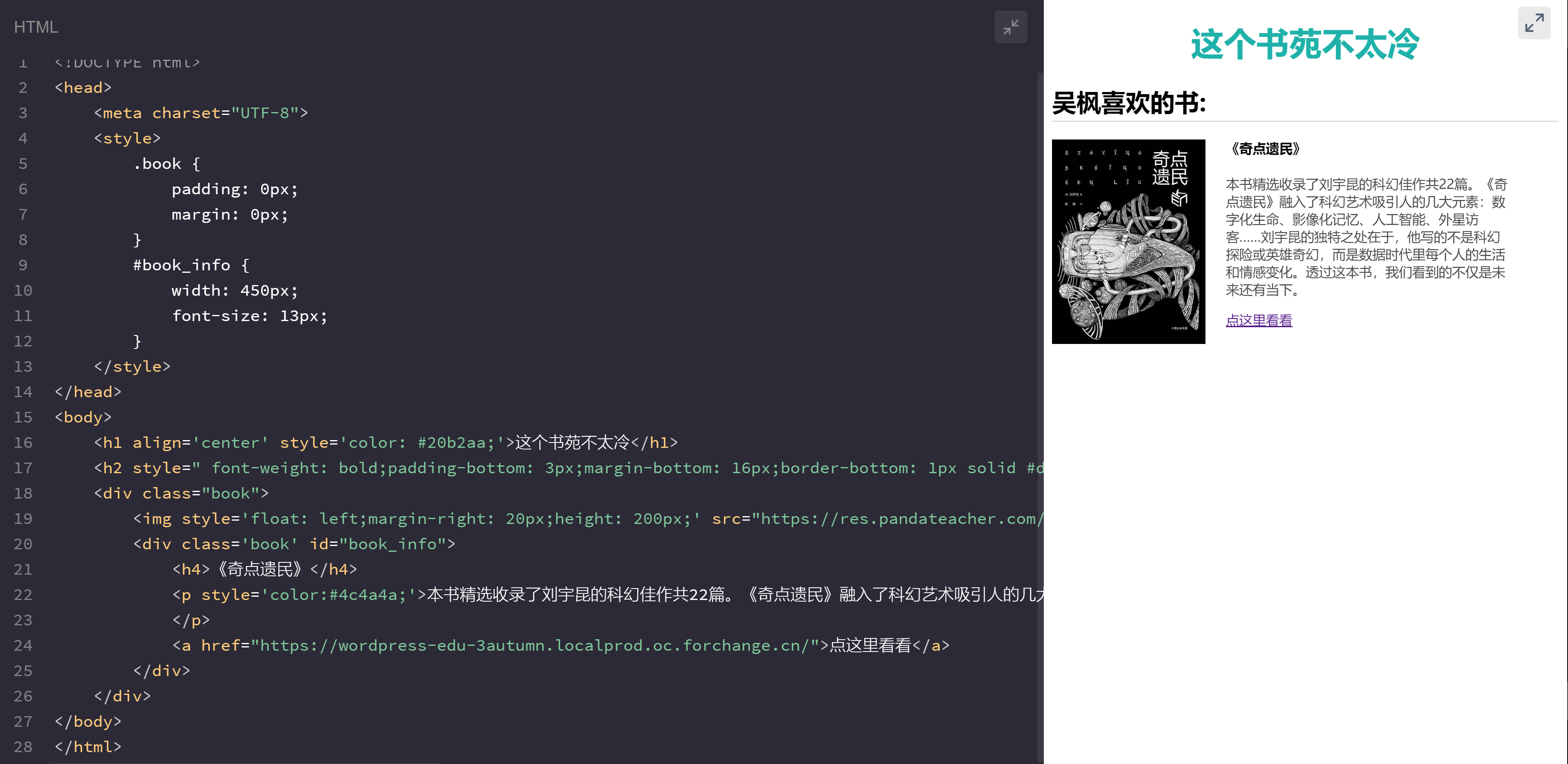
id属性则刚好和class属性相反,整个HTML文档,它是独一无二的标识,每个id值只能定义一个元素。
如若今后要爬取的元素带有id属性,那么恭喜你!这个元素具有唯一的标识,有了id,从千万元素中取值,犹如探囊取物。
<!DOCTYPE html>
<head>
<meta charset="UTF-8">
<style>
.book {
padding: 0px;
margin: 0px;
}
#book_info {
450px;
font-size: 13px;
}
</style>
</head>
<body>
<h1 align='center' style='color: #20b2aa;'>这个书苑不太冷</h1>
<h2 style=" font-weight: bold;padding-bottom: 3px;margin-bottom: 16px;border-bottom: 1px solid #ddd;">吴枫喜欢的书:</h2>
<div class="book">
<img style='float: left;margin-right: 20px;height: 200px;' src="https://res.pandateacher.com/book_qidianyimin.jpg" alt="奇点遗民">
<div class='book' id="book_info">
<h4>《奇点遗民》</h4>
<p style='color:#4c4a4a;'>本书精选收录了刘宇昆的科幻佳作共22篇。《奇点遗民》融入了科幻艺术吸引人的几大元素:数字化生命、影像化记忆、人工智能、外星访客……刘宇昆的独特之处在于,他写的不是科幻探险或英雄奇幻,而是数据时代里每个人的生活和情感变化。透过这本书,我们看到的不仅是未来还有当下。
</p>
<a href="https://wordpress-edu-3autumn.localprod.oc.forchange.cn/">点这里看看</a>
</div>
</div>
</body>
</html>
咱们重点关注第18行和第20行代码,显然,两个div元素含有同一个class属性值book,两个元素都可以使用.book的样式,但只有id="book_info"的元素可以使用#book_info的样式。
注:在<style>标签中定义class属性的样式用点.,id属性用井号键#(了解即可)。
id就像是学生的学生证号码,每个人都是唯一的,而学生们可以属于同一个班级,班级就像class。
好,以上,是HTML文档关于结构、标签、属性、元素这几个概念的理解,来份总结吧~
3. HTML分析
刷够了HTML文档的技能点,现在,即将开启的是一件分析HTML文档的“神器” —— 浏览器的开发者工具。
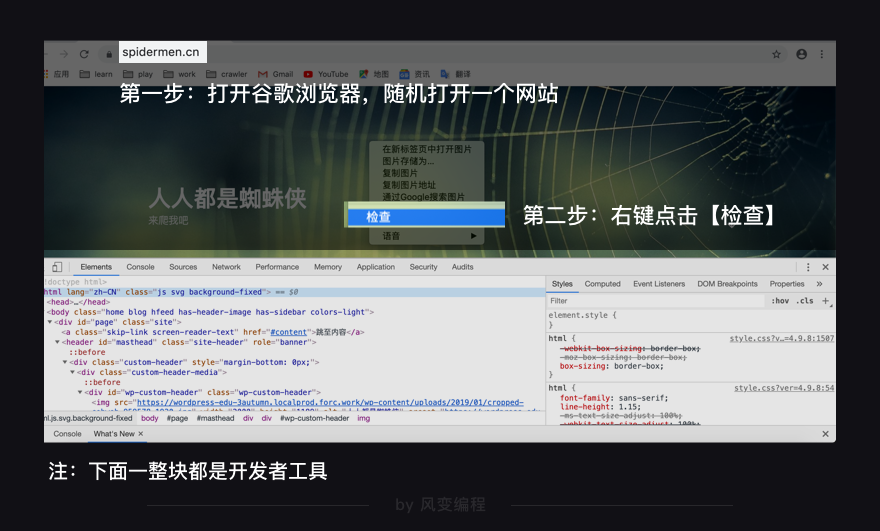
3.1 开发者工具
使用谷歌浏览器(chrome)随机打开一个网页,右键点击【检查】选项,Windows电脑的同学可直接按F12,随即,网页下方(或右方)弹出一个子窗口,这便是浏览器的开发者工具。
可以看到,HTML源代码中有一些小三角形,每一个三角形都可以展开或合上。尖角向下代表展开,向右代表合上了。
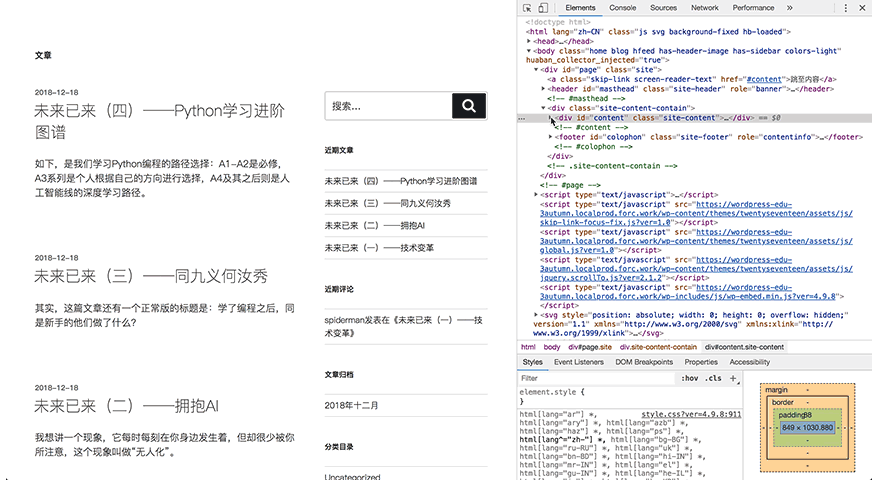
HTML的层级关系可通过这些小三角形进行查阅,每一个可以展开和合上的小三角形里包含的内容,都是一个层级,就像电脑中一层一层的文件夹。
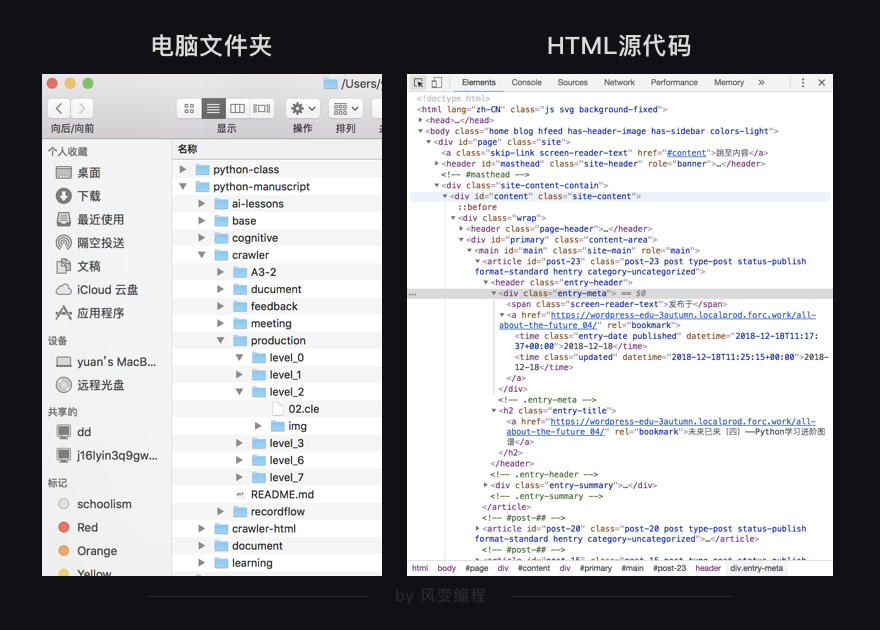
3.2 开发者彩蛋
值得一提的是,浏览器的开发者工具除了可以查看html的源代码,还可以查看前端程序员留给同行的“暗号”,老师带你去看看。
打开百度网页下的开发者工具,点击开发者工具导航栏上的Console标签,哎嘿,发现了百度的招聘链接。
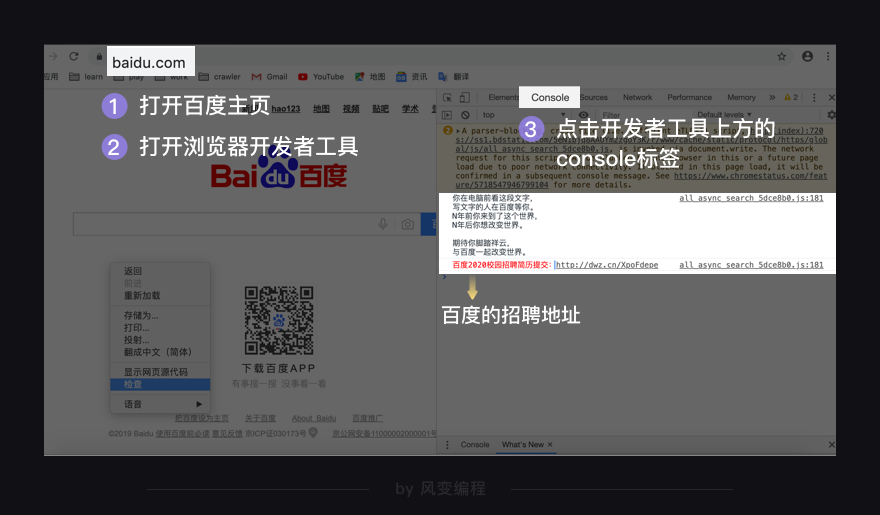
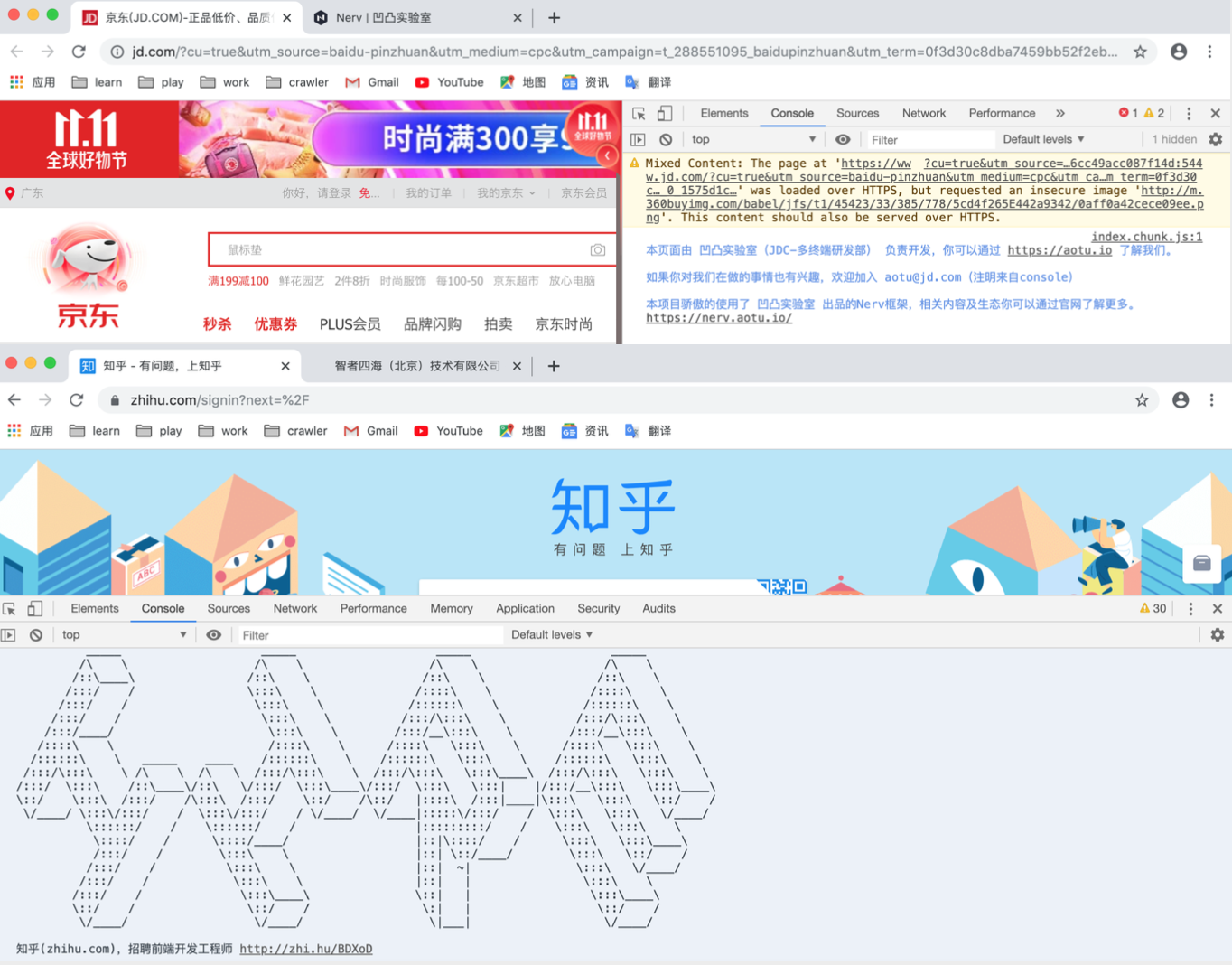
同样的方法,可以查看你喜欢的网站是否具有类似的招聘渠道,通过这种方式投递简历,也许你会收获意料之外的惊喜。
3.3 修改网页
最后再教你一个网页偷天换日法:
打开我们的爬虫学习网站网页下的开发者工具,你能看到左上角,有一个图标长这样吗?
点击URL:https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html
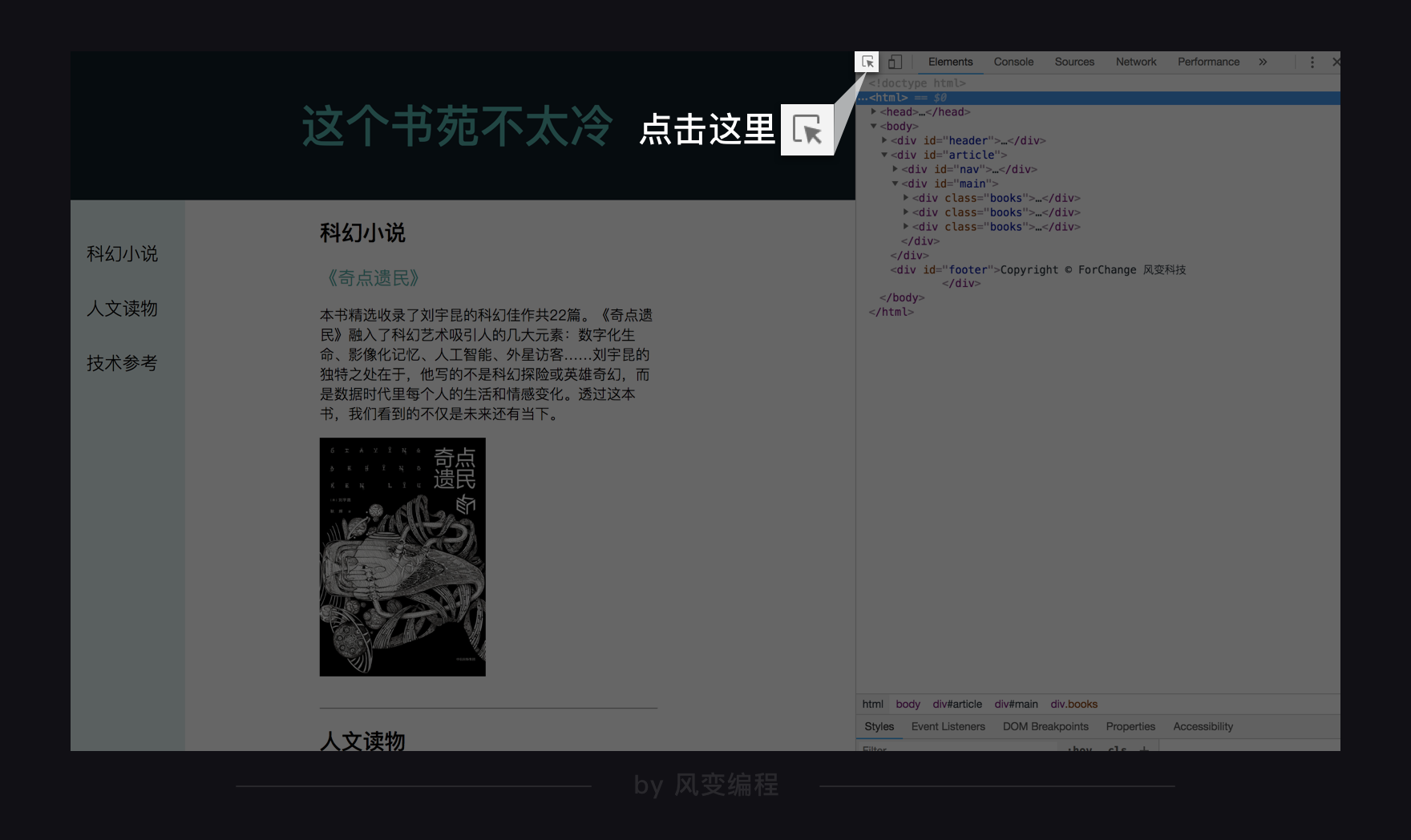
点击它,然后再把鼠标放在网页中,你会发现很好玩的事情:当鼠标放在网页上,右边代码区中描述它的代码会被标亮出来:
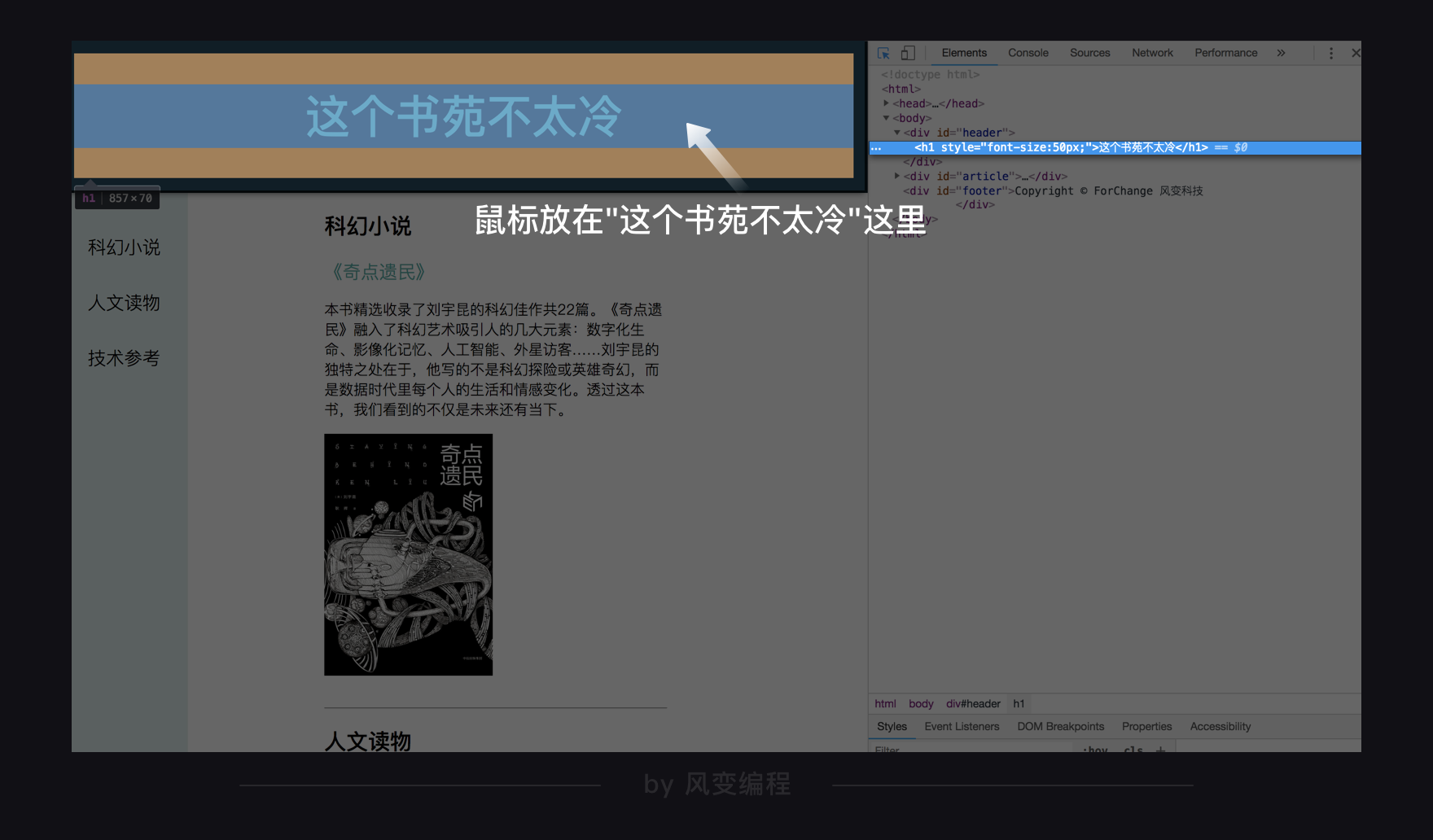
这是一个你以后会经常用到的功能,用来定位你所要查找的网页内容的源代码。我们可用鼠标在源代码上从网页头到尾轻轻滑过(无需点击),查看当前代码被浏览器解析后呈现的内容。
然后,定位到我们想修改的网页标题,把鼠标放在网页"这个书苑不太冷"这里,双击,和修改word文档一样。
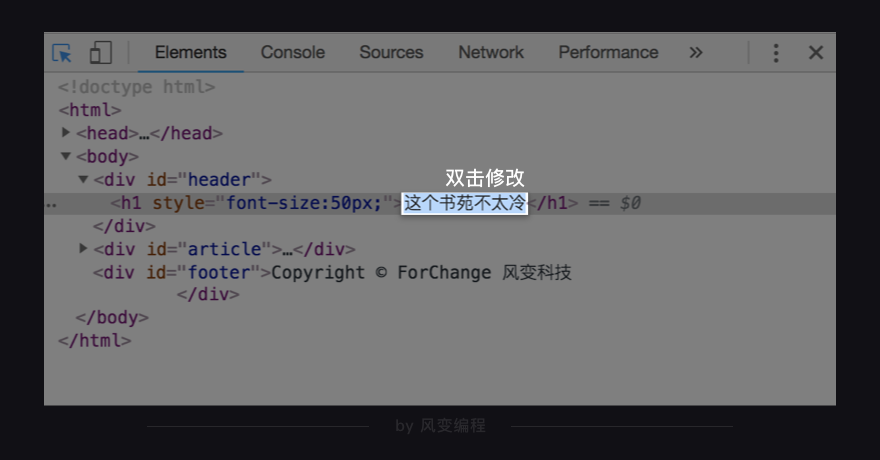
改完之后,按下enter确认。你会发现左边的文字就变成了你刚才输入的样子。

然后点击开发者工具右上角的叉号,关掉它,大功告成!
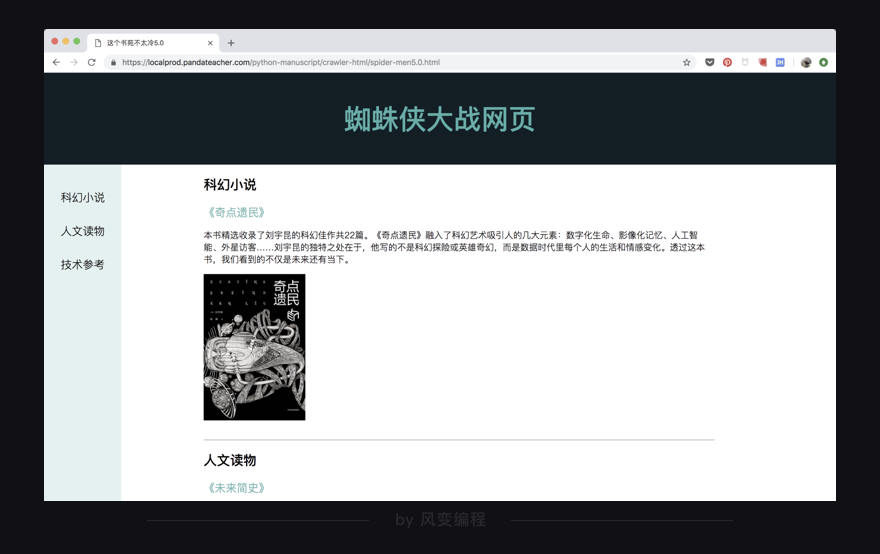
用同样的方法,可以修改网页的其它部分。
学会了这招,你还可以用来修改其他的网页,比如修改偶像的ins,P图都没有这么自然,发朋友圈炫耀。
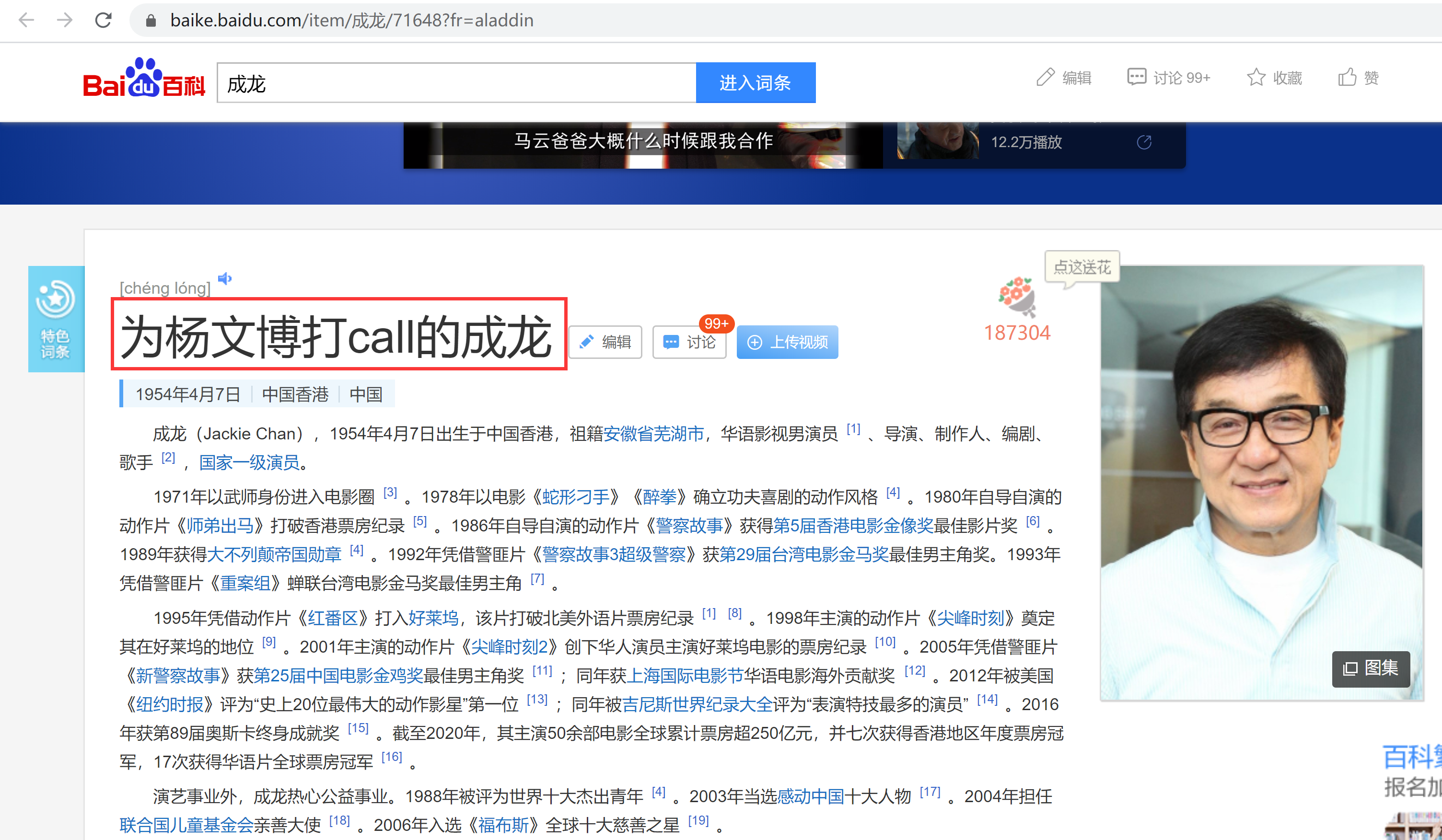
当然,这样的修改只是在你本地的修改,而服务器上的源文件你是修改不了的。
如果你重新刷新网页,修改的所有内容都会被清空。所以,这些改动仅供你自娱自乐。而程序员们会使用这个方法,在开发者工具这里,调试HTML代码。
到这里,我认为你已经足够了解HTML,可以继续学习爬虫啦。
4. 实操一下
获取数据
上一关,你已经学习了使用requests.get()获取数据,体验了用它来获取电子书和图片。

我们来回顾一下,试着获取这个书苑不太冷的网页源代码。
URL:https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html
请求这个网页的源代码,并且打印出来。提示:response.text可获得网页响应的文本数据(在这里,响应数据就是HTML文档源码),然后再打印出来就好啦。
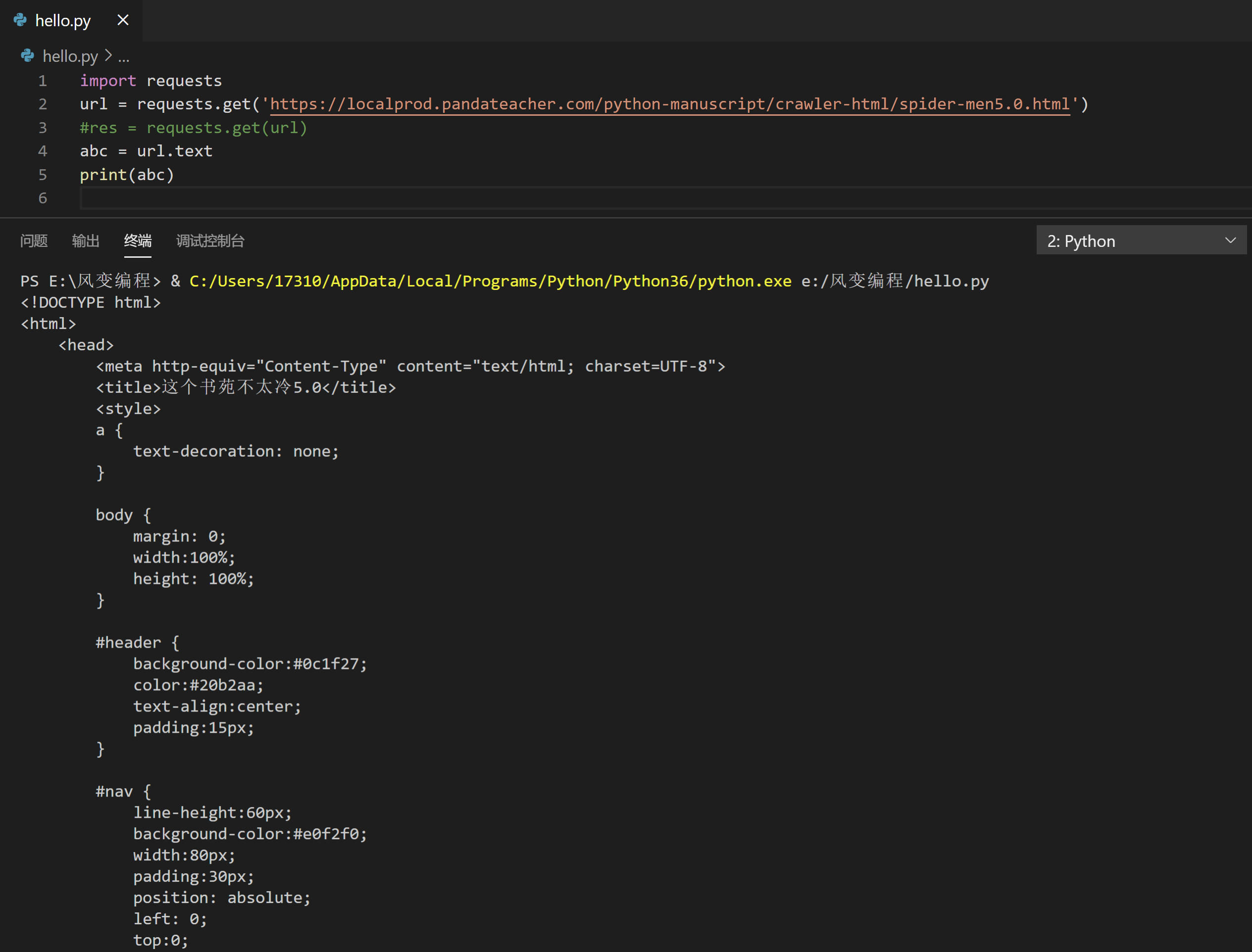
import requests
url = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
#res = requests.get(url)
abc = url.text
print(abc)
检查一下,网页源代码都正常,没有编码问题,完美❀
接下来,我们把请求到的HTML源代码保存到本地,和上一关保存的.txt文件不同的是,这次,我们保存的是HTML文档,它的文件扩展名是.html,如(test.html)。
提示:html文件写入和txt文件写入方式一样(打开文件 - 写入文件 - 关闭文件)
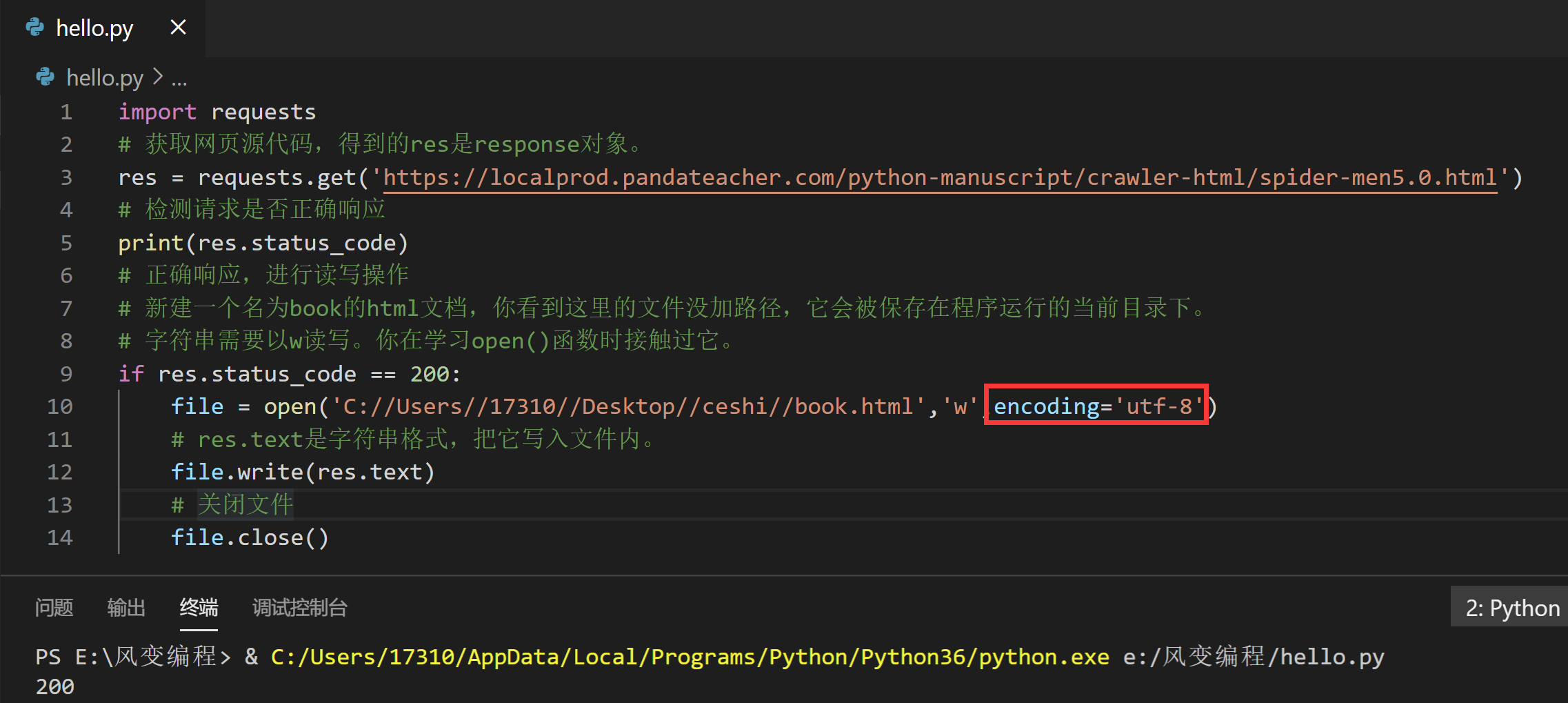
import requests
# 获取网页源代码,得到的res是response对象。
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
# 检测请求是否正确响应
print(res.status_code)
# 正确响应,进行读写操作
# 新建一个名为book的html文档,你看到这里的文件没加路径,它会被保存在程序运行的当前目录下。
# 字符串需要以w读写。你在学习open()函数时接触过它。
if res.status_code == 200:
file = open('C://Users//17310//Desktop//ceshi//book.html','w',encoding='utf-8')
# res.text是字符串格式,把它写入文件内。
file.write(res.text)
# 关闭文件
file.close()
刚才,你已经成功实践了爬虫的第0步,获取网页源代码,此处应该有掌声。

最后对比一下老师的答案:
# 调用requests模块
import requests
# 获取网页源代码,得到的res是response对象。
res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html')
# 检测请求是否正确响应
print(res.status_code)
# 正确响应,进行读写操作
# 新建一个名为book的html文档,你看到这里的文件没加路径,它会被保存在程序运行的当前目录下。
# 字符串需要以w读写。你在学习open()函数时接触过它。
if res.status_code == 200:
file = open('book.html','w',encoding='utf-8')
# res.text是字符串格式,把它写入文件内。
file.write(res.text)
# 关闭文件
file.close()
然后,双击我们写在本地的book.html文件,你会发现它可以用浏览器打开。这就好比MP3文件用音乐播放器打开,txt用记事本打开。
现在的你应该更明白浏览器的工作原理了,简单来说:浏览器从服务器上接收一个HTML文档,然后拿去做解析,最后呈现给你。因此,它也可以把你电脑的HTML文档解析成漂亮的网页。
本关的内容就到这里结束了,我们来复习一下吧。
首先,我们了解了由网页头和网页体所构成的HTML基本结构。
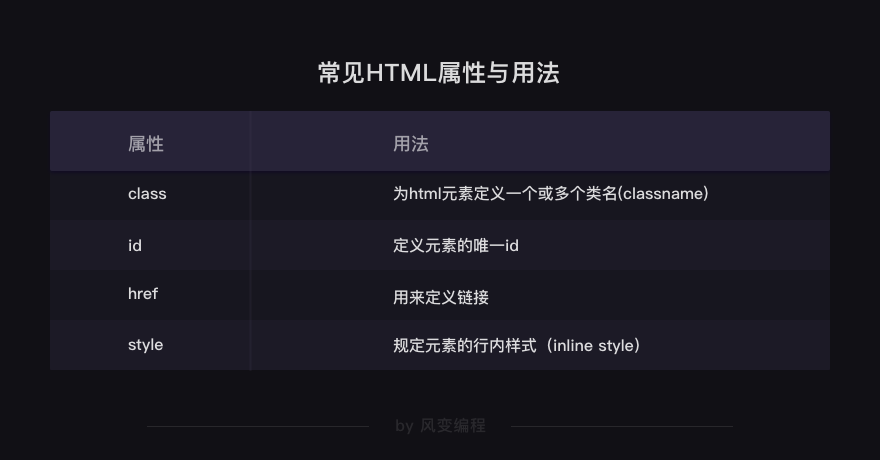
认识了HTML中的常见标签和常见属性:
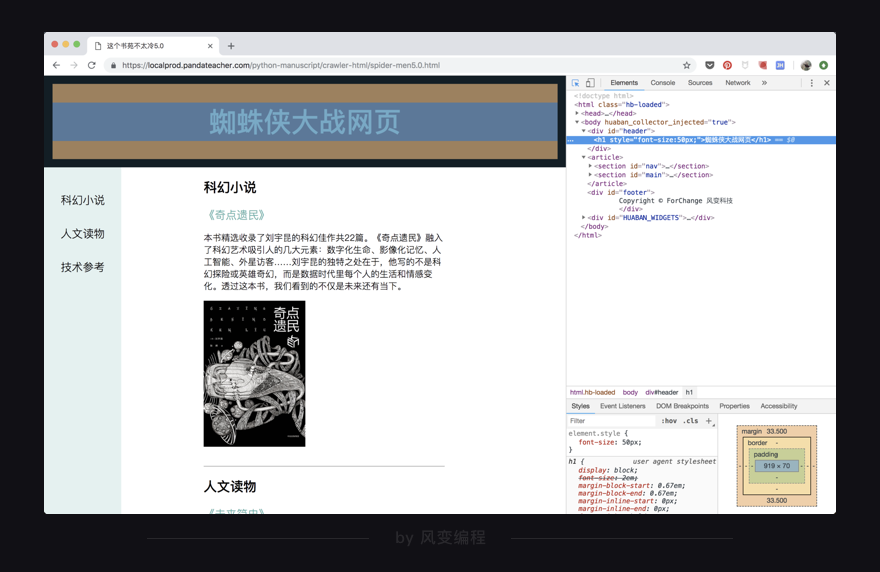
然后,我们读了一遍【这个书苑不太冷】的网页源代码。
分析完网页的结构和组成,又在HTML源代码的页面里成功修改了网页上显示的标题——“这个书苑不太冷”。
最后,还通过调用requests模块,获取到了网页源代码。
有了HTML的背景知识,我们就可以去学习爬虫的第1步【解析数据】和第2步【提取数据】啦。
只有看得懂网页结构,我们才能在HTML中找出要解析的数据,才能知道如何根据HTML本身的结构去提取出我们想要的数据。
5. 习题练习
1.要求:
把网页这个书院不太冷5.0修改为【我的书苑我做主】,并在网页中增加至少1本书。
2.目的
让你在了解HTML结构、元素、属性的基础上,有能力修改和编写网页。
3.写代码吧~
复习了所有知识点,一切都准备就绪,那就开始写属于你的网页吧!
我已经把网页的HTML源代码准备好了,你直接在上面修改就好。
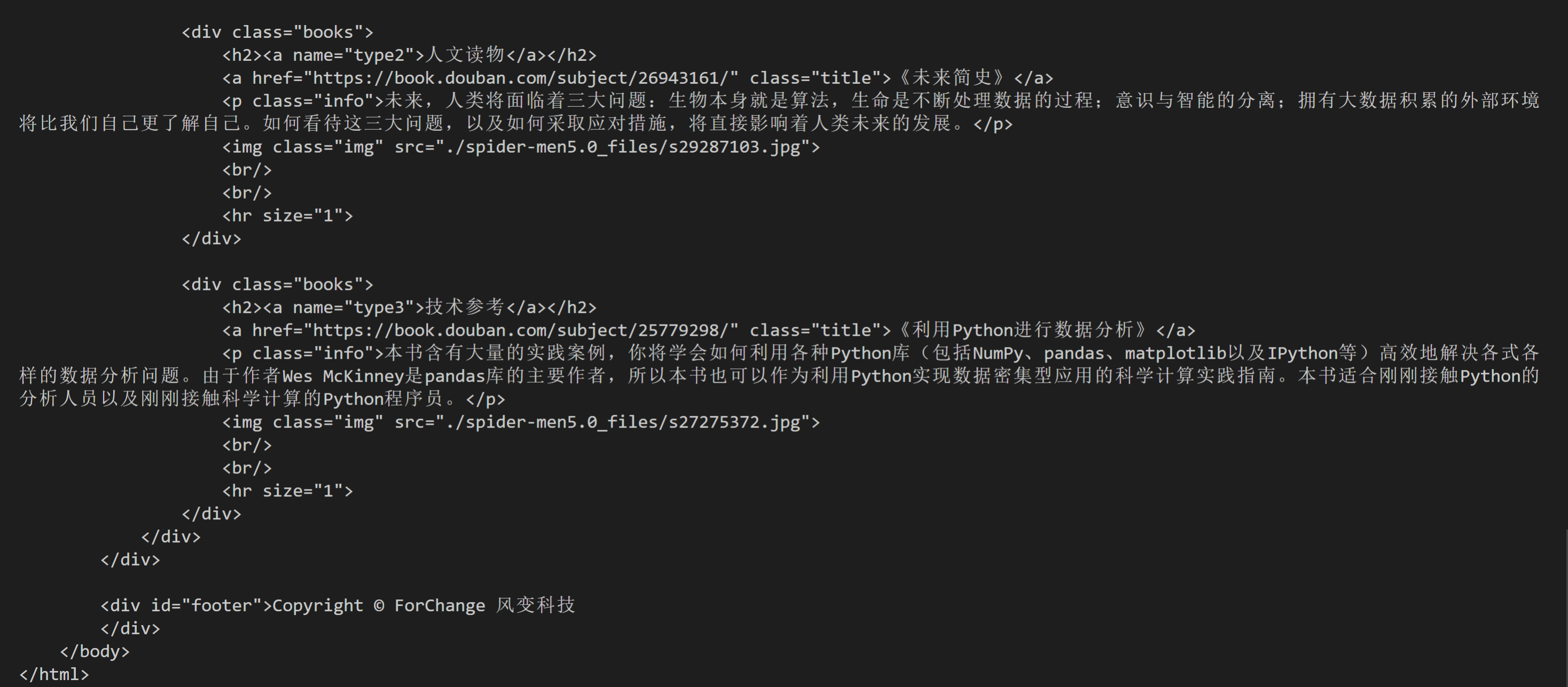
现在,请把网页这个书院不太冷5.0修改为你喜欢的模样。
必做:
修改网页标题
增加至少一本书的描述
修改网页底部
选做:
修改已有书籍的描述
增加多本书的描述
自由地在HTML文档上修改任意内容
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>我的书苑我做主</title>
<style>
a {
text-decoration: none;
}
body {
margin: 0;
100%;
height: 100%;
}
#header {
background-color:#0c1f27;
color:#20b2aa;
text-align:center;
padding:15px;
}
#nav {
line-height:60px;
background-color:#e0f2f0;
80px;
padding:30px;
position: absolute;
left: 0;
top:0;
bottom: 0;
}
#footer {
background-color:#0c1f27;
color:#20b2aa;
clear:both;
text-align:center;
padding:35px;
}
#main {
margin-left: 140px;
padding-left: 150px;
padding-right: 220px;
overflow: scroll;
}
#article {
display: flex;
position: relative;
}
.catlog{
font-size:20px;
color:black;
font-family: sans-serif;
}
.title {
color:#20b2aa;
font-size:20px;
}
.img {
185px;
height: 266px;
}
</style>
</head>
<body>
<div id="header">
<h1 style="font-size:50px;">杨文博的书苑</h1>
</div>
<div id="article">
<div id="nav">
<a href="#type1" class="catlog">科幻小说</a><br>
<a href="#type1" class="catlog">玄幻小说</a><br>
<a href="#type2" class="catlog">人文读物</a><br>
<a href="#type3" class="catlog">技术参考</a><br>
</div>
<div id="main">
<div class="books">
<h2><a name="type1">科幻小说</a></h2>
<a href="https://book.douban.com/subject/27077140/" class="title">《奇点遗民》</a>
<p class="info">本书精选收录了刘宇昆的科幻佳作共22篇。《奇点遗民》融入了科幻艺术吸引人的几大元素:数字化生命、影像化记忆、人工智能、外星访客……刘宇昆的独特之处在于,他写的不是科幻探险或英雄奇幻,而是数据时代里每个人的生活和情感变化。透过这本书,我们看到的不仅是未来还有当下。</p>
<img class="img" src="https://img3.doubanio.com/view/subject/l/public/s29492583.jpg">
<br/>
<br/>
<hr size="1">
</div>
<div class="books">
<h2><a name="type1">玄幻小说</a></h2>
<a href="https://book.qidian.com/info/1004608738/" class="title">《圣墟》</a>
<p class="info">本书精选收录了辰东的玄幻佳作共1篇。《圣墟》在破败中崛起,在寂灭中复苏。沧海成尘,雷电枯竭,那一缕幽雾又一次临近大地,世间的枷锁被打开了,一个全新的世界就此揭开神秘的一角……</p>
<img class="img" src="https://ss0.bdstatic.com/70cFvHSh_Q1YnxGkpoWK1HF6hhy/it/u=4052905923,216231039&fm=26&gp=0.jpg">
<br/>
<br/>
<hr size="1">
</div>
<div class="books">
<h2><a name="type2">人文读物</a></h2>
<a href="https://book.douban.com/subject/26943161/" class="title">《未来简史》</a>
<p class="info">未来,人类将面临着三大问题:生物本身就是算法,生命是不断处理数据的过程;意识与智能的分离;拥有大数据积累的外部环境将比我们自己更了解自己。如何看待这三大问题,以及如何采取应对措施,将直接影响着人类未来的发展。</p>
<img class="img" src="https://img3.doubanio.com/view/subject/l/public/s29287103.jpg">
<br/>
<br/>
<hr size="1">
</div>
<div class="books">
<h2><a name="type3">技术参考</a></h2>
<a href="https://book.douban.com/subject/25779298/" class="title">《利用Python进行数据分析》</a>
<p class="info">本书含有大量的实践案例,你将学会如何利用各种Python库(包括NumPy、pandas、matplotlib以及IPython等)高效地解决各式各样的数据分析问题。由于作者Wes McKinney是pandas库的主要作者,所以本书也可以作为利用Python实现数据密集型应用的科学计算实践指南。本书适合刚刚接触Python的分析人员以及刚刚接触科学计算的Python程序员。</p>
<img class="img" src="https://img3.doubanio.com/view/subject/l/public/s27275372.jpg">
<br/>
<br/>
<hr size="1">
</div>
</div>
</div>
<div id="footer">Copyright © ForChange 风变科技
</div>
</body>
</html>