基本概念
•SRP: The Totem Single-Ring Ordering and MembershipProtocol
–基于以太网的组通信协议,节点间组成单环结构
–所有数据都采用UDP广播(message)、单播(token)
–消息的可靠性和有序性,基于token-passing实现
–每个节点都接收到同样的消息序列,故可容忍消息丢失、节点崩溃
•RRP: The Totem Redundant Ring Protocol
–基于SRP,RRP嵌入于SRP的网络层(相当于修改了SRP的recv/send函数)
–通过使用冗余网络把多个节点连接起来,可容忍网络的损坏
术语解释
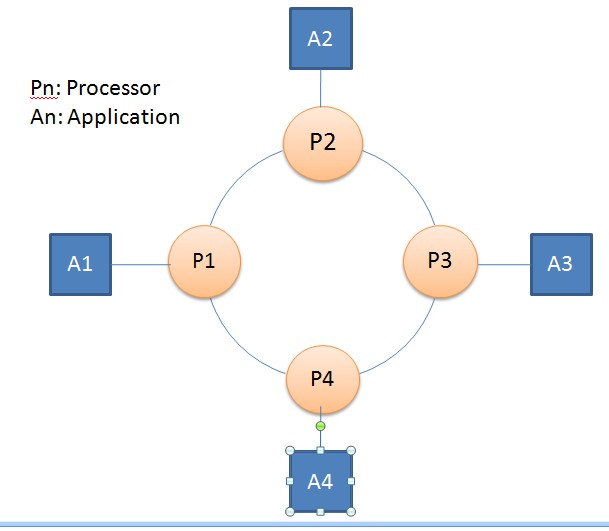
•Processor:
–节点,组通信成员,它需要实现SRP/RRP协议,并对外提供组通信接口,例如corosync,它提供组通信服务(叫CPG)。
•Application:
–
程序,使用组通信服务的应用程序,它调用Processor提供的组通信接口。例如sheepdog就是调用corosync提供的CPG接口。
•Broadcast:
–One Processor => all Processors
•Transmit/Forwardtoken:
–OneProcessor => next Processor
•Delivery:
–OneProcessor => associatedApplication
基本概念
•Causal Order:
–消息的传播是可靠的,即每一个结点都能收到该消息
–所有消息都有先后次序,不存在并发的情况
–Processor将消息传送给Application时,严格按照消息的先后次序传送
•Agreed Order:
–满足Causal Order
–Processor在传送某个消息给Application时,必须确保该消息之前的所有消息都已经传送完毕,确保消息不会丢失
•Safe Order:
–满足Agreed Order
–Processor在传送某个消息给Application时,必须确保该消息之前的所有消息都已经被所有Processor接收
SRP细分为三个子协议
•The Totem Ordering Protocol(OP):
–确保消息从Single-Ring中传播,到最终传递给Application时,满足Agreed Order或SafeOrder。
•The Membership Protocol(MP):
–当有新的Processor加入或旧的Processor离开时,自动形成新的Single-Ring。
•The Recovery Protocol(RP):
–从Old Ring过渡到New Ring的过程中,恢复属于(残缺的)Old Ring的消息(使它们满足Agreed或SafeOrder)。
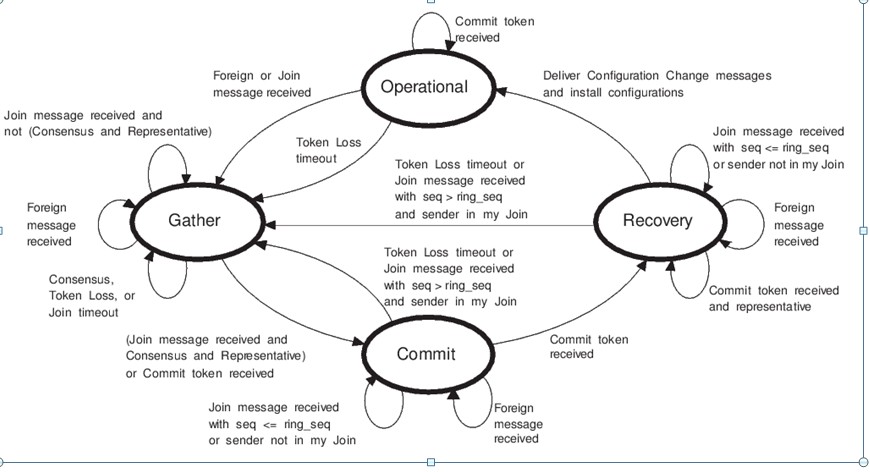
SRP的四个状态
子协议与状态的关系
•TheTotem Ordering Protocol(OP):
–工作在Operational状态
•TheMembership Protocol(MP):
–工作在Gather、Commit状态
•TheRecovery Protocol(RP):
–工作在Recovery状态
TheTotal Ordering Protocol
•TheTotem Ordering Protocol(OP):
–工作在Operational状态
–确保消息从Single-Ring中传播,到最终传递给Application时,满足Agreed Order或SafeOrder。
–由Application在发送消息时,指定采用Agreed还是Safe方式。
–通过token,以“丢手绢”的方式,实现消息的有序传递。
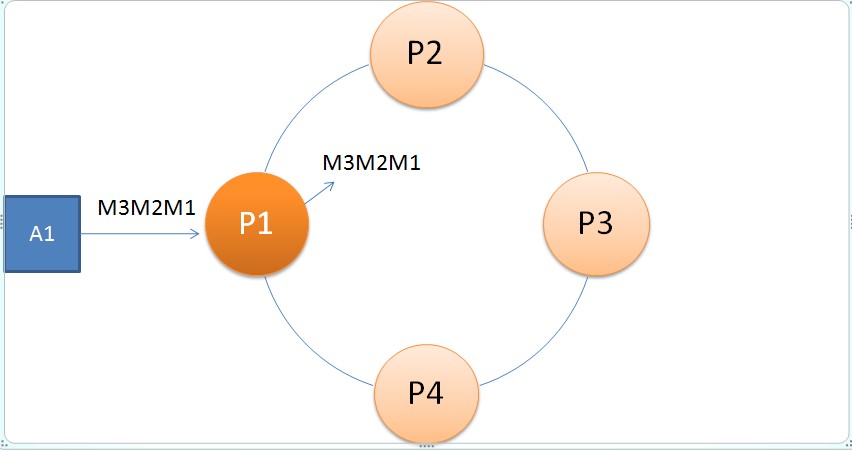
消息传播示意图
ØA1请求P1依次广播三个消息:M1, M2, M3,这些消息暂存在P1的请求队列中
Ø假设P1已拿到token,P1向集群依次广播:M1,M2,M3
ØP1广播的消息,也会保存在它自己的接收队列中
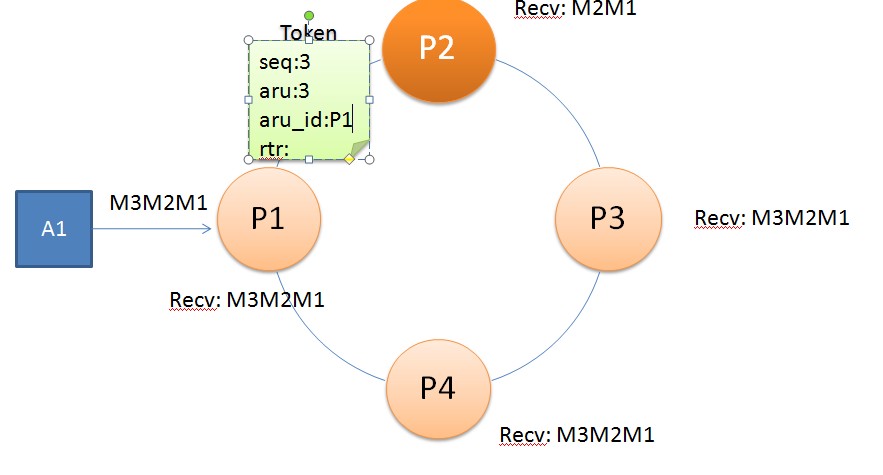
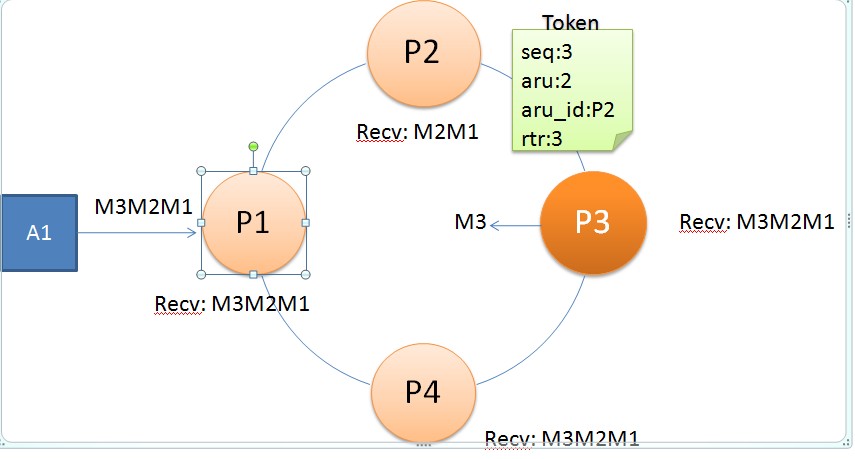
消息传播示意图
ØP2只收到两个消息M2M1,P3,P4完整的收到三个消息M3M2M1
ØP1把Token传递给P2,Token中记录了P1接收队列中消息的max
seq:3
ØP2通过比较Token中的seq,发现自己没有接收到M3。
消息传播示意图
ØP2把token传给P3,更新token的aru(all-received-up-to)为:2
在Token的重传请求列表(rtr)中记录了未收到的消息序号:3
ØP3收到token后,向集群广播M3,清除token的rtr后,把token传给P4
ØP2收到P3广播的消息M3,
其它节点乎略消息M3
ØP4收到P3传过来的token,没做任务事情,把token传给P1
ØP1收到P4传过来的token,没做任务事情,把token传给P2
ØP1收到P4传过来的token,没做任务事情,把token传给P2
ØP2发现token中的aru_id是它自己,并且知道自己已经收到M3,
所以它更新token中的aru为3,至此P2知道集群的所有节点都收到了M3M2M1
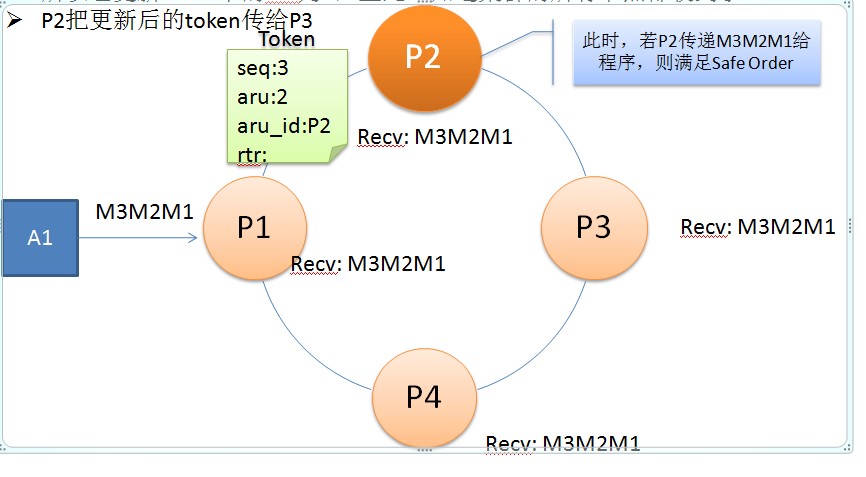
ØP2把更新后的token传给P3
满足Agreed/Safe Order么?
•AgreedOrder
–在token的上述传递过程中,拿到token的Processor,把已接收到的消息按次序传递给Application,则满足Agreed
Order。
•SafeOrder
在token的上述传递过程中,如果连续两次转发的token的aru大于等于某个消息的序号,则把该消息传递给Application时满足Safe
Order。
与OP协议相关的Corosync选项
•token_retransmit
–Processor在转发完token后,在多长时间内没有收到token或消息后,将引发token重传。
–默认值:238ms
–如果设置了下面的token值,本值由程序自动计算。
•token
–Processor在多长时间内没有收到token(中间包含token重传)后,将触发token丢失事件(将激活MembershipProtocol,进入Gather状态)。
–默认值:1000ms
本值等于Token在Ring中循环一圈的时间,这个时间取决了三个因素:结点数,结点之间的网络速率,每个结点在拿到token后可以发送的max_messages。
与OP协议相关的Corosync选项
•hold
–在Ring不怎么繁忙时,RingRepresentative在转发token前,休息多长时间。
–默认值:180ms
–本值通常由程序根据地其他选项自动计算。
•token_retransmits_before_loss_const
–Token最大重传次数
–默认值:重传4次
–若设置本值,token_retransmit和hold的值,由程序根据地本值和token值计算。
•fail_recv_const
–在多少次token循环中,没有收到任何消息(本该收到消息:token.seq>my_aru),超过这个次数将激活Membership
Protocol,进入Gather状态。
–默认值:2500次
TheMembership Protocol
•TheMembership Protocol(MP):
–工作在Gather、Commit状态
–当有新的Processor加入或旧的Processor离开时,自动形成新的Single-Ring。
新加入一个节点示意图
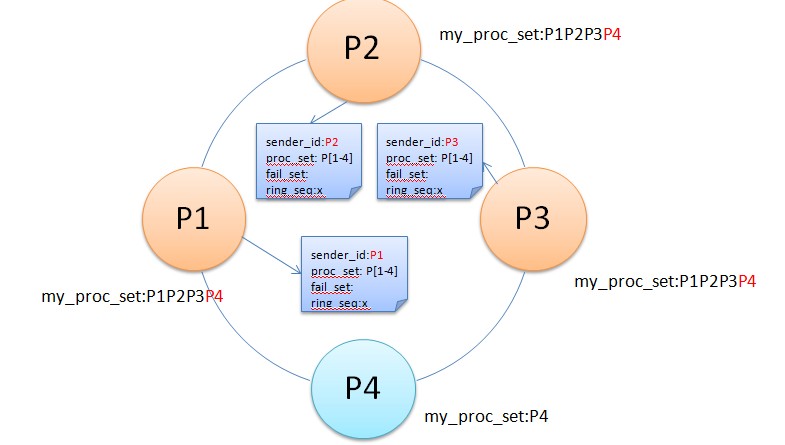
Ø设P4为新加入的节点,旧环为{P1,P2,P3},旧环的seq=100
旧环的三个结点都在各自的my_proc_set里记录了节点成员
ØP4加入集群后,广播一个join
msg。
ØP1,P2,P3收到join
msg后,进入Gather状态,根据msg的内容
做不同的动作
Ø当某个结点发现自己的my_proc_set中的所有成员都达到consensus后,
若它的id是成员中最小的id,则它发出一个CommitToken并进入commit状态,
CommitToken’sring_id.seq = max(old
ring_id and
JoinMsg’sring_id) + 4
Ø按照上面的过程,经过若干次JoinMsg的接收与转发,假设P1,P3,P4的
my_proc_set中的成员都已标记为consensus。
Ø设P2没有收到P3的JoinMsg,P2的consensus列表中consensus[P3]=false。
Ø上一张PPT讨论失败的情况,现在讨论正常的情况
Ø假设经过若干次JoinMsg的接收与转发,所有Processor的
my_proc_set中的成员都已标记为consensus。
ØP2接收到P1传过来的Commit Token后,更新memb_list和memb_idx,
转发Commit Token,并进入Commit状态
ØP3接收到P2传过来的Commit Token后,更新memb_list和memb_idx,
转发Commit Token,并进入Commit状态
ØP4接收到P3传过来的Commit Token后,更新memb_list和memb_idx,
转发Commit Token,并进入Commit状态
ØP1接收到P4传过来的Commit Token后,因为P1已处于Commit状态,
故P1知道此时所有成员,都已经进入了Commit状态。
ØP1第二次转发CommitToken,进入Recovery状态,
并持久化新ring_id (my_ring_id=CommitToken’sring_id)。
ØP2第二次转发CommitToken,进入Recovery状态,
并持久化新ring_id (my_ring_id=CommitToken’sring_id)。
ØP3第二次转发CommitToken,进入Recovery状态,
并持久化新ring_id (my_ring_id=CommitToken’sring_id)。
ØP4第二次转发CommitToken,进入Recovery状态,
并持久化新ring_id (my_ring_id=CommitToken’sring_id)。
Ø由于P4是新加入的结点,它的my_trans_memb只有它自己
Ø当P1第三次收到Commit Token时,所有结点都达到Reovery状态
与MP协议相关的Corosync选项
•
–Processor在发送JoinMsg后,在多长时间内没有收到其他成员的JoinMsg,将引发JoinMsg重传。
–默认值:50ms
•send_join
–当Processor数量比较大时(>30),某个节点的加入/离开,可能造成各节点瞬间同时发出JoinMsg,造成网络拥塞。通过设置此值,程序发送JoinMsg前,将随机等待[0,send_join]区间内的某个时长。
–默认值:0ms
•consensus
–Processor从进入Gather状态起,在多长时间内必须使(my_proc_set-my_fail_set)集合的成员达到consensus(被标记为true)。否则清除已被标记为true的成员,重发JoinMsg。
–若设置此值,必须>=1.2*token。
–若未设置此值,程序将按1.2*token值处理。
–注:为了简化PPT的讲解,前面的PPT没有介绍my_fail_set(它用来保存OldRing中失效的节点)
TheRecovery Protocol
•TheRecovery Protocol(RP):
–工作在Recovery状态
–从Old Ring过渡到New Ring的过程中,恢复属于(残缺的)Old Ring的消息(使它们满足Agreed或SafeOrder)。
–在Rcovery状态中,Application发到新Ring的消息,不会被广播(需要等到Operational状态)。
步实现Recovery
•Step1:
–与同属于相同的Old Ring的其它Processors交换消息(这个过程,与OP协议类似,不再详述)。
–同一个New Ring中,可能有多个Old Ring并存。
•Step2:
–把在本Processor的Old Configuration下,满足Agreed或Safe
Order的消息直接delivery给Application(message.seq<=high_ring_delivered)
•Step3:
–向Application传递第一个ConfingChangeMsg,即Transitional
Configuration。
–内含在New Ring中与本Processor同属于一个OldRing的成员列表。
•Step4:
–把在本Processor的Transitional Configuration下,满足Agreed或Safe
Order的消息delivery给Application(注意与Step2的区别)。
•Step3:
–向Application传递第一个ConfingChangeMsg,即Transitional
Configuration。
–内含在New Ring中与本Processor同属于一个OldRing的成员列表。
•Step4:
–把在本Processor的Transitional Configuration下,满足Agreed或Safe
Order的消息delivery给Application(注意与Step2的区别)。
•SRP的Flow Control Mechanism
–window_size:
在一次token的循环中,整个集群可以广播的最大的消息数。
–max_messages:
节点在拿到token后,可以广播的最大消息数。
–以上两个参数,也可以在Corosync中配置。
RPR协议简介
•工作原理
–基于SRP,RRP嵌入于SRP的网络层(相当于修改了SRP的recv/send函数)
–通过使用冗余网络把多个节点连接起来,可容忍网络的损坏
RPR的三种Replication Styles
•Active replication
–所有消息都同时发送到N个冗余网络。
–每个消息都被接收N次。
–Processor的带宽消耗随着N的增大而减少。
•Passive replication
–所有消息只发送到N个冗余网络的其中一个。
–每个消息都只被接收到一次。
–Processor的带宽消耗与Sing-Ring相同。
•Active-passive replication
混合模式,所有消息都同时发送到K(1<K<N,例如为3)个冗余网络。
•rrp_mode
–ReplicationStyle。
–可能的值:none, active, passive。
–目前corosync还不支持active-passive混合模式。
•rrp_token_expired_timeout
–在多长时间内,没有从任意一个冗余网络中收到token,则把ProblemCounter增1。
–默认值:47ms。
•rrp_problem_count_timeout
–在多长时间内,如果某个网络没被标记为faulty,则把ProblemCounter减1。
–默认值:2000ms。
•rrp_problem_count_threshold
–当ProblemCounter达到某个值后,则把某个网络标记为faulty。
–本值*token_expired_timeout<=(token-50ms)
–默认值:10