本节介绍使用飞桨快速实现“手写数字识别”的建模方法。
与“房价预测”的案例类似,我们以同样的标准结构实现“手写数字识别”的建模。在后续的课程中,该标准结构会反复出现,逐渐加深我们对深度学习模型的理解。深度学习模型的标准结构分如下五个步骤:
- 数据处理:读取数据和预处理操作。
- 模型设计:搭建神经网络结构。
- 训练配置:配置优化器、学习率、训练参数。
- 训练过程:循环调用训练过程,循环执行“前向计算 + 损失函数 + 反向传播”。
- 保存模型并测试:将训练好的模型保存并评估测试。
下面我们使用飞桨框架,按照五个步骤写“手写数字识别”模型,体会下使用飞桨框架的感觉。
在数据处理前,首先要加载飞桨平台、与“手写数字识别”模型相关类库,代码如下:
1 #加载飞桨和相关类库 2 import paddle 3 import paddle.fluid as fluid 4 from paddle.fluid.dygraph.nn import FC 5 import numpy as np 6 import os 7 from PIL import Image
1. 数据处理
飞桨提供了多个封装好的数据集API,覆盖计算机视觉、自然语言处理、推荐系统等多个领域,可以帮助我们快速完成机器学习任务。比如,在“手写数字识别”模型中,我们可以通过调用paddle.dataset.mnist的train函数和test函数,直接获取处理好的MNIST训练集和测试集。
定义数据读取器
用户可以通过如下代码定义数据读取器:
1 # 如果~/.cache/paddle/dataset/mnist/目录下没有MNIST数据,API会自动将MINST数据下载到该文件夹下 2 # 设置数据读取器,读取MNIST数据训练集 3 trainset = paddle.dataset.mnist.train() 4 testset = paddle.dataset.mnist.test() 5 # 包装数据读取器,每次读取的数据数量设置为batch_size=8 6 train_reader = paddle.batch(trainset, batch_size=8) 7 test_reader = paddle.batch(testset,batch_size=8)
读取数据,并打印观察
paddle.batch函数将MNIST数据集拆分成多个批次,我们可以用下面的代码读取第一个批次的数据内容(因为for循环结尾处有一个break,运行一个循环后就立即退出),并观察数据结果。
1 # 以迭代的形式读取数据 2 for batch_id, data in enumerate(train_reader()): 3 # 获得图像数据,并转为float32类型的数组 4 img_data = np.array([x[0] for x in data]).astype('float32') 5 # 获得图像标签数据,并转为float32类型的数组 6 label_data = np.array([x[1] for x in data]).astype('float32') 7 # 打印数据形状 8 #print("图像数据形状和对应数据为:", img_data.shape, img_data[0]) 9 print("图像数据形状和对应数据为:", img_data.shape) 10 print("图像标签形状和对应数据为:", label_data.shape, label_data[0]) 11 break 12 13 print(" 打印第一个batch的第一个图像,对应标签数字为{}".format(label_data[0])) 14 # 显示第一batch的第一个图像(可以在程序任一个地方引用库) 15 import matplotlib.pyplot as plt 16 #img=np.array(img_data[0]) #这两句话效果相同 17 img = np.array(img_data[0]+1)*127.5 18 img = np.reshape(img, [28, 28]).astype(np.uint8) 19 20 plt.figure("Image") # 图像窗口名称 21 plt.imshow(img) 22 plt.axis('on') # 关掉坐标轴为 off 23 plt.title('image') # 图像题目 24 plt.show()
图像数据形状和对应数据为: (8, 784) 图像标签形状和对应数据为: (8,) 5.0 打印第一个batch的第一个图像,对应标签数字为5.0

上面得到的数据img_data[0]输出的是一个矩阵,每个数据值在【-1,1】之间。
从代码的输出来看,我们从数据加载器train_loader()中读取一次数据,可以得到形状为 (8, 784)的图像数据和形状为(8,)的标签数据。其中,8与设置的batch大小对应,784为mnist数据集中每个图像的像素数量(28*28)。
另外,从打印的图像数据来看,图像数据的范围是[-1, 1],表明这是已经完成图像归一化后的图像数据,且背景部分的值是-1。我们可以将图像数据反归一化(就是+1,再乘以127),并使用matplotlib工具包将其显示出来。显示的数字是5,和对应标签数字一致。
说明:飞桨将维度是28*28的手写数字数据图像转成向量形式存储,因此,使用飞桨数据读取到的手写数字图像是长度为784(28*28)的向量。
2. 模型设计
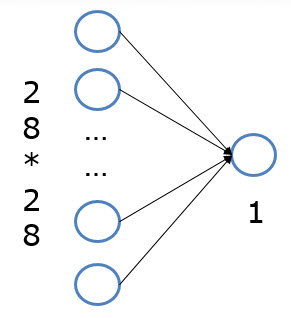
在“房价预测”深度学习任务中,我们使用了单层且没有非线性变换的模型,取得了理想的预测效果。在“手写数字识别”中,我们依然使用这个模型预测输入的图形数字值。其中,模型的输入为784维(28*28)数据,输出为1维数据,如图1所示。
1 # 定义mnist数据识别网络结构,同房价预测网络 2 class MNIST(fluid.dygraph.Layer): 3 def __init__(self, name_scope): 4 super(MNIST, self).__init__(name_scope) 5 name_scope = self.full_name() 6 # 定义一层全连接层,输出维度是1,激活函数为None,即不使用激活函数 7 #hidden1=fluid.layers.fc(input=name_scope,size=100,act='relu') 8 #hidden2=FC(input=hidden1,size=100,act='relu') 9 self.fc = FC(name_scope, size=1, act='relu') 10 11 # 定义网络结构的前向计算过程 12 def forward(self, inputs): 13 outputs = self.fc(inputs) 14 return outputs
3. 训练配置
训练配置负责神经网络训练前的准备,包括:
- 声明定义好的模型。
- 加载训练数据和测试数据。
- 设置优化算法和学习率,本次实验优化算法使用随机梯度下降SGD,学习率使用 0.01。
1 # 定义飞桨动态图工作环境 2 with fluid.dygraph.guard(): 3 # 声明网络结构 4 model = MNIST("mnist") 5 # 启动训练模式 6 model.train() 7 # 定义数据读取函数,数据读取batch_size设置为16 8 train_loader = paddle.batch(paddle.dataset.mnist.train(), batch_size=16) 9 # 定义优化器,使用随机梯度下降SGD优化器,学习率设置为0.001 10 optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.001)
上面中train()函数没有发现在MNIST类中有定义,很是奇怪,需要找到train()函数的原始定义。
4. 训练过程
完成训练配置后,可启动训练过程。采用二层循环嵌套方式:
- 内层循环负责整个数据集的一次遍历,遍历数据集采用分批次(batch)方式。
- 外层循环定义遍历数据集的次数,本次训练中外层循环10次,通过参数EPOCH_NUM设置。
1 # 通过with语句创建一个dygraph运行的context, 2 # 动态图下的一些操作需要在guard下进行 3 with fluid.dygraph.guard(): 4 model = MNIST("mnist") 5 model.train() 6 train_loader = paddle.batch(paddle.dataset.mnist.train(), batch_size=16) 7 optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.001) 8 EPOCH_NUM = 10 9 for epoch_id in range(EPOCH_NUM): 10 for batch_id, data in enumerate(train_loader()): 11 #准备数据,格式需要转换成符合框架要求的 12 image_data = np.array([x[0] for x in data]).astype('float32') 13 label_data = np.array([x[1] for x in data]).astype('float32').reshape(-1, 1) 14 # 将数据转为飞桨动态图格式 15 image = fluid.dygraph.to_variable(image_data) 16 label = fluid.dygraph.to_variable(label_data) 17 18 #前向计算的过程 19 predict = model(image) 20 21 #计算损失,取一个批次样本损失的平均值 22 loss = fluid.layers.square_error_cost(predict, label) 23 avg_loss = fluid.layers.mean(loss) 24 25 #每训练了1000批次的数据,打印下当前Loss的情况 26 if batch_id !=0 and batch_id % 1000 == 0: 27 print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy())) 28 29 #后向传播,更新参数的过程 30 avg_loss.backward() 31 optimizer.minimize(avg_loss) 32 model.clear_gradients() 33 34 # 保存模型 35 fluid.save_dygraph(model.state_dict(), 'mnist')
epoch: 0, batch: 1000, loss is: [1.8736392] epoch: 0, batch: 2000, loss is: [4.0054626] epoch: 0, batch: 3000, loss is: [3.7705934] epoch: 1, batch: 1000, loss is: [1.8645047] epoch: 1, batch: 2000, loss is: [3.8951108] epoch: 1, batch: 3000, loss is: [3.5067868] epoch: 2, batch: 1000, loss is: [1.8366505] epoch: 2, batch: 2000, loss is: [3.778401] epoch: 2, batch: 3000, loss is: [3.4168165] epoch: 3, batch: 1000, loss is: [1.8329564] epoch: 3, batch: 2000, loss is: [3.7081861] epoch: 3, batch: 3000, loss is: [3.3437557] epoch: 4, batch: 1000, loss is: [1.8373424] epoch: 4, batch: 2000, loss is: [3.6615422] epoch: 4, batch: 3000, loss is: [3.2822015] epoch: 5, batch: 1000, loss is: [1.8455799] epoch: 5, batch: 2000, loss is: [3.6457105] epoch: 5, batch: 3000, loss is: [3.2266264] epoch: 6, batch: 1000, loss is: [1.8546844] epoch: 6, batch: 2000, loss is: [3.6325989] epoch: 6, batch: 3000, loss is: [3.1794245] epoch: 7, batch: 1000, loss is: [1.863614] epoch: 7, batch: 2000, loss is: [3.6269343] epoch: 7, batch: 3000, loss is: [3.129442] epoch: 8, batch: 1000, loss is: [1.8726021] epoch: 8, batch: 2000, loss is: [3.6225967] epoch: 8, batch: 3000, loss is: [3.0918531] epoch: 9, batch: 1000, loss is: [1.880715] epoch: 9, batch: 2000, loss is: [3.6216624] epoch: 9, batch: 3000, loss is: [3.0604477]
上面为训练的结果输出。
同样的问题:predict = model(image)这句中,没有调用model的forward()函数就完成了前向计算,也理解不了。
通过观察训练过程中损失所发生的变化,可以发现虽然损失整体上在降低,但到训练的最后一轮,损失函数值依然较高。可以猜测,“手写数字识别”完全复用“房价预测”的代码,训练效果并不好。接下来我们通过模型测试,获取模型训练的真实效果。
5. 模型测试
模型测试的主要目的是验证训练好的模型是否能正确识别出数字。测试模型包括以下三步:
- 从'./demo/example_0.jpg'目录下读取样例图片。
- 加载模型并将模型的状态设置为校验状态(eval),显式告诉框架我们接下来只会使用前向计算的流程,不会计算梯度和梯度反向传播,这将减少内存的消耗。
- 将测试样本传入模型,获取预测结果,取整后作为预测标签输出。
1 # 导入图像读取第三方库 2 import matplotlib.image as mpimg 3 import matplotlib.pyplot as plt 4 # 读取图像 5 example = mpimg.imread('./work/example_0.png') 6 # 显示图像 7 plt.imshow(example)

1 # 读取一张本地的样例图片,转变成模型输入的格式 2 def load_image(img_path): 3 # 从img_path中读取图像,并转为灰度图 4 im = Image.open(img_path).convert('L') 5 print(np.array(im)) 6 im = im.resize((28, 28), Image.ANTIALIAS) 7 im = np.array(im).reshape(1, -1).astype(np.float32) 8 # 图像归一化,保持和数据集的数据范围一致 9 im = 2 - im / 127.5 10 return im 11 12 # 定义预测过程 13 with fluid.dygraph.guard(): 14 model = MNIST("mnist") 15 params_file_path = 'mnist' 16 img_path = './work/example_0.png' 17 # 加载模型参数 18 model_dict, _ = fluid.load_dygraph("mnist") 19 model.load_dict(model_dict) 20 21 model.eval() 22 tensor_img = load_image(img_path) 23 result = model(fluid.dygraph.to_variable(tensor_img)) 24 #预测输出取整,即为预测的数字 25 print("本次预测的数字是", result.numpy().astype('int32'))
[[255 255 255 ... 255 255 255] [255 255 255 ... 255 255 255] [255 255 255 ... 255 255 255] ... [255 255 255 ... 255 255 255] [255 255 255 ... 255 255 255] [255 255 255 ... 255 255 255]]
本次预测的数字是 [[1]]
model.load_dict()是加载模型,model.eval()是去掉训练过程(也就是没有了反向计算过程),只是测试。
如上可见,模型错误预测样例图片中的数字是1,实际应该预测的结果是0。但如果我们尝试更多的样本,会发现很多数字图片识别结果是错误的,完全复用房价预测的实验并不适用于手写数字识别任务,接下来我们会对该实验进行逐一改进,直到获得令人满意的结果。