一。引文
1.1 SMP(Symmetric Multi-Processor)
对称多处理器结构,指服务器中多个CPU对称工作,每个CPU访问内存地址所需时间相同。其主要特征是共享,包含对CPU,内存,I/O等进行共享。
SMP能够保证内存一致性,但这些共享的资源很可能成为性能瓶颈,随着CPU数量的增加,每个CPU都要访问相同的内存资源,可能导致内存访问冲突,
可能会导致CPU资源的浪费。常用的PC机就属于这种。
1.2 NUMA(Non-Uniform Memory Access)
非一致存储访问,将CPU分为CPU模块,每个CPU模块由多个CPU组成,并且具有独立的本地内存、I/O槽口等,模块之间可以通过互联模块相互访问,
访问本地内存的速度将远远高于访问远地内存(系统内其它节点的内存)的速度,这也是非一致存储访问的由来。NUMA较好地解决SMP的扩展问题,
当CPU数量增加时,因为访问远地内存的延时远远超过本地内存,系统性能无法线性增加。
二。CLH
CLH(Craig, Landin, and Hagersten locks): 是一个自旋锁,能确保无饥饿性,提供先来先服务的公平性。
CLH锁也是一种基于链表的可扩展、高性能、公平的自旋锁,申请线程只在本地变量上自旋,它不断轮询前驱的状态,如果发现前驱释放了锁就结束自旋。
当一个线程需要获取锁时:
1.创建一个的QNode,将其中的locked设置为true表示需要获取锁
2.线程对tail域调用getAndSet方法,使自己成为队列的尾部,同时获取一个指向其前趋结点的引用myPred
3.该线程就在前趋结点的locked字段上旋转,直到前趋结点释放锁
4.当一个线程需要释放锁时,将当前结点的locked域设置为false,同时回收前趋结点
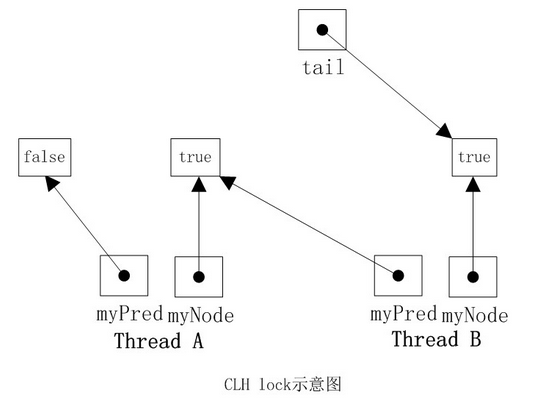
如下图,线程A需要获取锁,其myNode域为true,tail指向线程A的结点,然后线程B也加入到线程A后面,tail指向线程B的结点。然后线程A和B
都在其myPred域上旋转,一旦它的myPred结点的locked字段变为false,它就可以获取锁。明显线程A的myPred locked域为false,此时线程A获取
到了锁。
三。CLH代码示例
public class CLHLock implements Lock { AtomicReference<QNode> tail ; ThreadLocal<QNode> myPred; ThreadLocal<QNode> myNode; public CLHLock() { tail = new AtomicReference<QNode>(new QNode()); myNode = new ThreadLocal<QNode>() { protected QNode initialValue() { return new QNode(); } }; myPred = new ThreadLocal<QNode>() { protected QNode initialValue() { return null; } }; } @Override public void lock() { QNode qnode = myNode.get(); qnode.locked = true; QNode pred = tail.getAndSet(qnode); myPred.set(pred); while (pred.locked) { } } @Override public void unlock() { QNode qnode = myNode.get(); qnode.locked = false; myNode.set(myPred.get()); } }
四。CLH分析
CLH队列锁的优点是空间复杂度低(如果有n个线程,L个锁,每个线程每次只获取一个锁,那么需要的存储空间是O(L+n),n个线程有n个
myNode,L个锁有L个tail),CLH的一种变体被应用在了JAVA并发框架中(AbstractQueuedSynchronizer.Node)。CLH在SMP系统结构下
该法是非常有效的。但在NUMA系统结构下,每个线程有自己的内存,如果前趋结点的内存位置比较远,自旋判断前趋结点的locked域,性能
将大打折扣,一种解决NUMA系统结构的思路是MCS队列锁。
五。MCS
MSC与CLH最大的不同并不是链表是显示还是隐式,而是线程自旋的规则不同:CLH是在前趋结点的locked域上自旋等待,而MCS是在自己的
结点的locked域上自旋等待。正因为如此,它解决了CLH在NUMA系统架构中获取locked域状态内存过远的问题。
MCS队列锁的具体实现如下:
a. 队列初始化时没有结点,tail=null
b. 线程A想要获取锁,于是将自己置于队尾,由于它是第一个结点,它的locked域为false
c. 线程B和C相继加入队列,a->next=b,b->next=c。且B和C现在没有获取锁,处于等待状态,所以它们的locked域为true,
尾指针指向线程C对应的结点
d. 线程A释放锁后,顺着它的next指针找到了线程B,并把B的locked域设置为false。这一动作会触发线程B获取锁

六。代码实现
public class MCSLock implements Lock { AtomicReference<QNode> tail; ThreadLocal<QNode> myNode; @Override public void lock() { tail = new AtomicReference<QNode>(new QNode()); QNode qnode = myNode.get(); QNode pred = tail.getAndSet(qnode); if (pred != null) { qnode.locked = true; pred.next = qnode; // wait until predecessor gives up the lock while (qnode.locked) { } } } @Override public void unlock() { QNode qnode = myNode.get(); if (qnode.next == null) { if (tail.compareAndSet(qnode, null)) return; // wait until predecessor fills in its next field while (qnode.next == null) { } } qnode.next.locked = false; qnode.next = null; } class QNode { boolean locked = false; QNode next = null; } }