1、下载hadoop https://hadoop.apache.org/releases.html
2、上传文件,解压,重命名
tar -zxf hadoop-2.8.5.tar.gz mv hadoop-2.8.5 hadoop
3、配置环境变量
vi /etc/profile
#hadoop export HADOOP_HOME=/home/hadoop/ export PATH=${HADOOP_HOME}/bin:$PATH
4、配置生效
source /etc/profile
5、进入安装的hadoop 下的 etc/hadoop/目录
cd /home/hadoop/etc/hadoop/
6、修改配置文件
1) vi core-site.xml <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://服务器IP:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop/tmp</value> </property> </configuration>
2)vi hdfs-site.xml <configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>服务器IP:50090</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/tmp/dfs/data</value> </property> </configuration>
3)vi yarn-site.xml <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
7、初始化操作
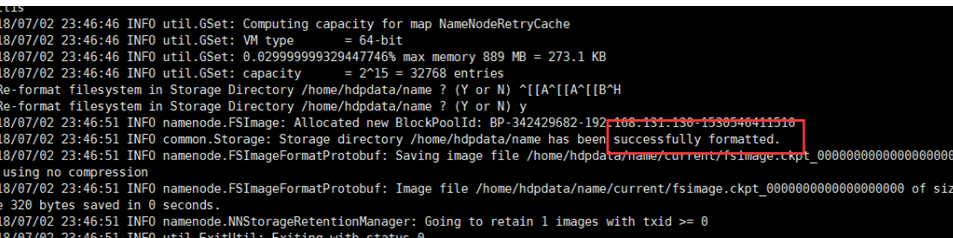
hadoop namenode -format
8、验证hadoop是否安装成功:进入你安装的hadoop目录下的sbin目录:/home/hadoop/sbin
cd /home/hadoop/sbin/
./start-all.sh
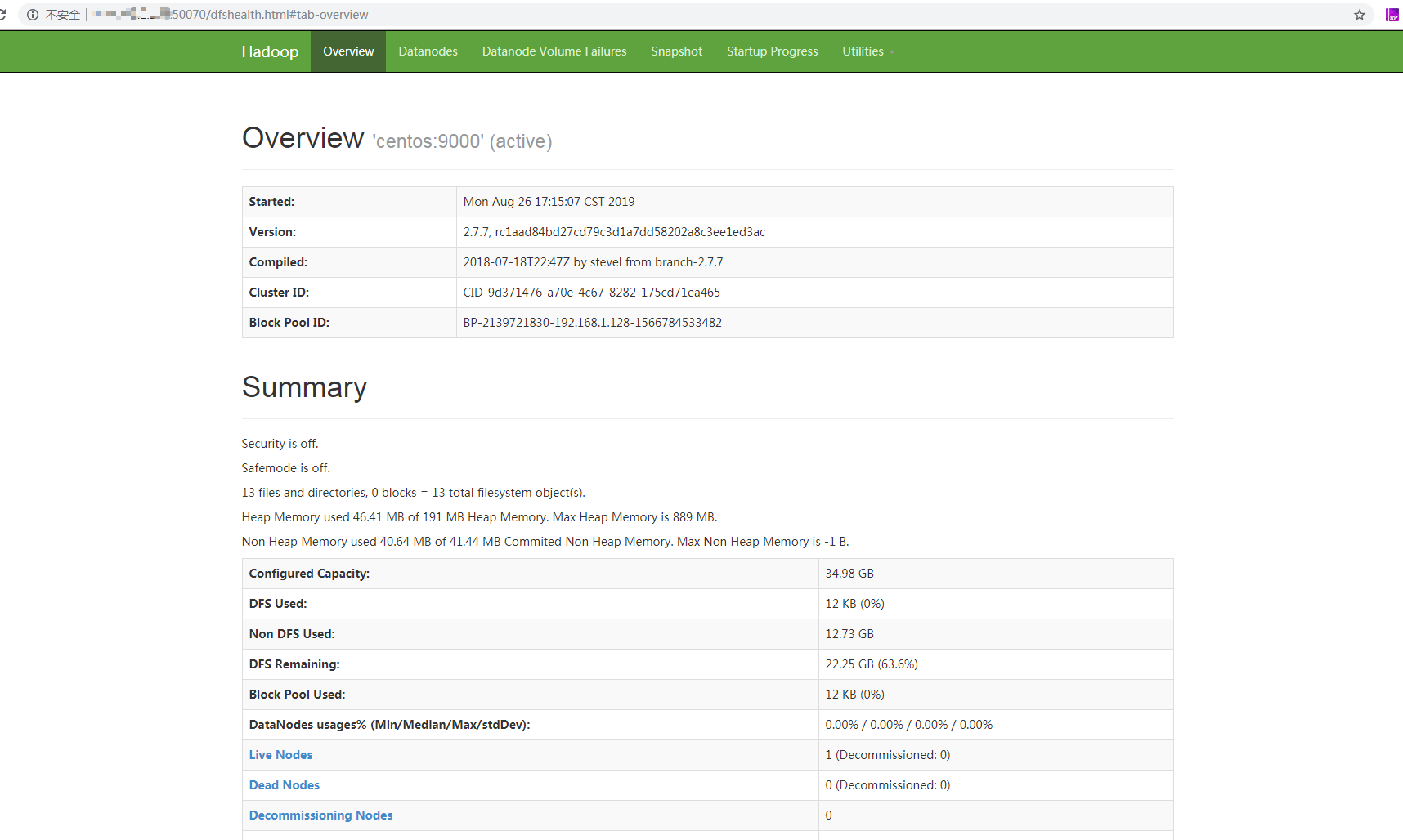
输入IP:50070,出现如下界面,则hadoop安装成功