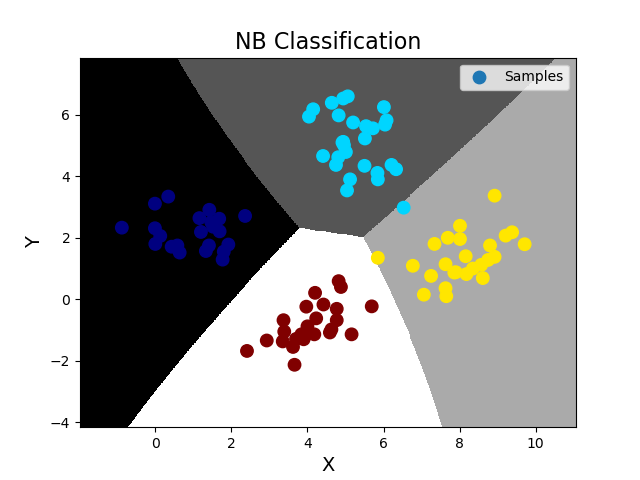
''' 分类模型数据集划分问题: 对于分类问题训练集和测试集的划分不应该用整个样本空间的特定百分比作为训练数据, 而应该在其每一个类别的样本中抽取特定百分比作为训练数据。sklearn模块提供了数据集划分相关方法, 可以方便的划分训练集与测试集数据,使用不同数据集训练或测试模型,达到提高分类可信度。 回归模型数据集直接打乱按照二八原则划分即可 数据集划分相关API: import sklearn.model_selection as ms ms.train_test_split(输入集, 输出集, test_size=测试集占比, random_state=随机种子) ->训练输入, 测试输入, 训练输出, 测试输出 案例: ''' import numpy as np import matplotlib.pyplot as mp import sklearn.naive_bayes as nb import sklearn.model_selection as ms data = np.loadtxt('./ml_data/multiple1.txt', delimiter=',', unpack=False, dtype='f8') print(data.shape) x = np.array(data[:, :-1]) y = np.array(data[:, -1]) # 训练集和测试集的划分 使用训练集训练 再使用测试集测试,并绘制测试集样本图像 train_x, test_x, train_y, test_y = ms.train_test_split(x, y, test_size=0.25, random_state=7) # 训练NB模型,完成分类业务 model = nb.GaussianNB() model.fit(train_x, train_y) pred_test_y = model.predict(test_x) # 得到预测输出,可以与真实输出作比较,计算预测的精准度(预测正确的样本数/总测试样本数) ac = (test_y == pred_test_y).sum() / test_y.size print('预测精准度 ac=', ac) # 绘制分类边界线 l, r = x[:, 0].min() - 1, x[:, 0].max() + 1 b, t = x[:, 1].min() - 1, x[:, 1].max() + 1 n = 500 grid_x, grid_y = np.meshgrid(np.linspace(l, r, n), np.linspace(b, t, n)) bg_x = np.column_stack((grid_x.ravel(), grid_y.ravel())) bg_y = model.predict(bg_x) grid_z = bg_y.reshape(grid_x.shape) # 画图 mp.figure('NB Classification', facecolor='lightgray') mp.title('NB Classification', fontsize=16) mp.xlabel('X', fontsize=14) mp.ylabel('Y', fontsize=14) mp.tick_params(labelsize=10) mp.pcolormesh(grid_x, grid_y, grid_z, cmap='gray') mp.scatter(test_x[:, 0], test_x[:, 1], s=80, c=test_y, cmap='jet', label='Samples') mp.legend() mp.show() 输出结果: (400, 3) 预测精准度 ac= 0.99