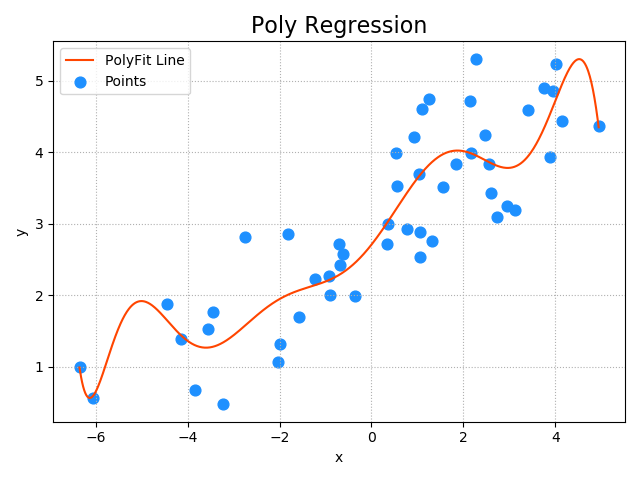
''' 多项式回归:若希望回归模型更好的拟合训练样本数据,可以使用多项式回归器。 一元多项式回归: 数学模型:y = w0 + w1 * x^1 + w2 * x^2 + .... + wn * x^n 将高次项看做对一次项特征的扩展得到: y = w0 + w1 * x1 + w2 * x2 + .... + wn * xn 那么一元多项式回归即可以看做为多元线性回归,可以使用LinearRegression模型对样本数据进行模型训练。 所以一元多项式回归的实现需要两个步骤: 1. 将一元多项式回归问题转换为多元线性回归问题(只需给出多项式最高次数即可)。 2. 将1步骤得到多项式的结果中 w1,w2,w3,...,wn当做样本特征,交给线性回归器训练多元线性模型。 选择合适的最高次数其模型R2评分会高于一元线性回归模型评分,如果次数过高,会出现过拟合现象,评分会低于一元线性回归评分 使用sklearn提供的"数据管线"实现两个步骤的顺序执行: import sklearn.pipeline as pl import sklearn.preprocessing as sp import sklearn.linear_model as lm model = pl.make_pipeline( # 10: 多项式的最高次数 sp.PolynomialFeatures(10), # 多项式特征扩展器 lm.LinearRegression()) # 线性回归器 过拟合和欠拟合: 1.过拟合:过于复杂的模型,对于训练数据可以得到较高的预测精度,但对于测试数据通常精度较低,这种现象叫做过拟合。 2.欠拟合:过于简单的模型,无论对于训练数据还是测试数据都无法给出足够高的预测精度,这种现象叫做欠拟合。 3.一个性能可以接受的学习模型应该对训练数据和测试数据都有接近的预测精度,而且精度不能太低。 训练集R2 测试集R2 0.3 0.4 欠拟合:过于简单,无法反映数据的规则 0.9 0.2 过拟合:过于复杂,太特殊,缺乏一般性 0.7 0.6 可接受:复杂度适中,既反映数据的规则,同时又不失一般性 加载single.txt文件中的数据,基于一元多项式回归算法训练回归模型。 步骤: 导包--->读取数据--->创建多项式回归模型--->模型训练及预测--->通过模型预测得到pred_y,绘制多项式函数图像 ''' import sklearn.pipeline as pl import sklearn.linear_model as lm import sklearn.preprocessing as sp import matplotlib.pyplot as mp import numpy as np import sklearn.metrics as sm # 采集数据 x, y = np.loadtxt('./ml_data/single.txt', delimiter=',', usecols=(0, 1), unpack=True) # 把输入变为二维数组,一行一样本,一列一特征 x = x.reshape(-1, 1) # 创建模型 model = pl.make_pipeline( sp.PolynomialFeatures(10), # 多项式特征拓展器 lm.LinearRegression() # 线性回归器 ) # 训练模型 model.fit(x, y) # 求预测值y pred_y = model.predict(x) # 模型评估 print('平均绝对值误差:', sm.mean_absolute_error(y, pred_y)) print('平均平方误差:', sm.mean_squared_error(y, pred_y)) print('中位绝对值误差:', sm.median_absolute_error(y, pred_y)) print('R2得分:', sm.r2_score(y, pred_y)) # 绘制多项式回归线 px = np.linspace(x.min(), x.max(), 1000) px = px.reshape(-1, 1) pred_py = model.predict(px) # 绘制图像 mp.figure("Poly Regression", facecolor='lightgray') mp.title('Poly Regression', fontsize=16) mp.tick_params(labelsize=10) mp.grid(linestyle=':') mp.xlabel('x') mp.ylabel('y') mp.scatter(x, y, s=60, marker='o', c='dodgerblue', label='Points') mp.plot(px, pred_py, c='orangered', label='PolyFit Line') mp.tight_layout() mp.legend() mp.show() 输出结果: 平均绝对值误差: 0.4818952136579405 平均平方误差: 0.35240714067500095 中位绝对值误差: 0.47265950409692536 R2得分: 0.7868629092058499