''' 岭回归: 普通线性回归模型使用基于梯度下降的最小二乘法,在最小化损失函数的前提下,寻找最优模型参数, 在此过程中,包括少数异常样本在内的全部训练数据都会对最终模型参数造成程度相等的影响, 异常值对模型所带来影响无法在训练过程中被识别出来。为此,岭回归在模型迭代过程所依据的损失函数中增加了正则项, 以限制模型参数对异常样本的匹配程度,进而提高模型面对多数正常样本的拟合精度。 岭回归的目的: 1>普通线性回归无法识别或者避免异常样本对模型参数的影响,导致在预测时效果查(预测结果偏向于异常样本),岭回归可以通过正则强度的设置 来减少异常样本对模型参数的影响,从而使得预测结果更偏向于正常样本,提高了模型拟合精度。 2>加入正则项后,其R2得分肯定会低于普通线性回归,原因:普通线性回归考虑的是全部样本损失函数最小值,而岭回归就是为了避免异常值对预测的影响 从而刻意减少异常样本在计算中的权重,进而导致其损失函数最小值是大于普通线性回归的损失函数最小值。
正则强度越大,泛化能力越强
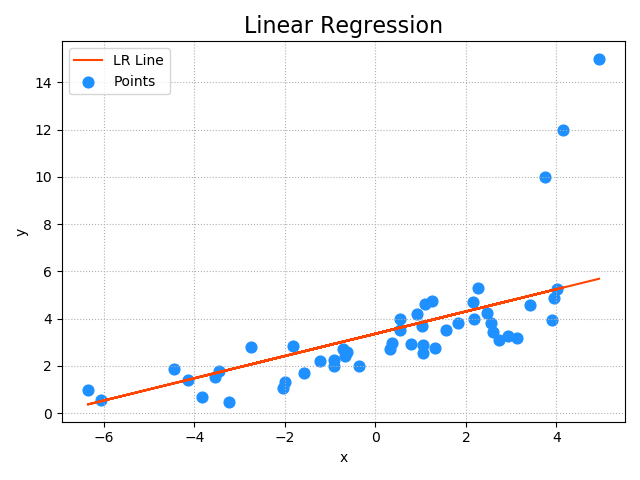
相关API: import sklearn.linear_model as lm # 创建模型 model = lm.Ridge(正则强度,fit_intercept=是否训练截距, max_iter=最大迭代次数) # 训练模型 # 输入:为一个二维数组表示的样本矩阵 # 输出:为每个样本最终的结果 model.fit(输入, 输出) # 预测输出 # 输入array是一个二维数组,每一行是一个样本,每一列是一个特征。 result = model.predict(array) 示例:加载abnormal.txt文件中的数据,基于岭回归算法训练回归模型。 ''' import sklearn.linear_model as lm import numpy as np import matplotlib.pyplot as mp import sklearn.metrics as sm x, y = np.loadtxt('./ml_data/abnormal.txt', delimiter=',', unpack=True, usecols=(0, 1)) # 把输入变成二维数组,一行一样本,一列一特征 x = x.reshape(-1, 1) # 变成n行1列 model = lm.Ridge(150, fit_intercept=True, max_iter=1000) model.fit(x, y) pred_y = model.predict(x) # 把样本x带入模型求出预测y # 输出模型的评估指标 print('平均绝对值误差:', sm.mean_absolute_error(y, pred_y)) print('平均平方误差:', sm.mean_squared_error(y, pred_y)) print('中位绝对值误差:', sm.median_absolute_error(y, pred_y)) print('R2得分:', sm.r2_score(y, pred_y)) # 绘制图像 mp.figure("Linear Regression", facecolor='lightgray') mp.title('Linear Regression', fontsize=16) mp.tick_params(labelsize=10) mp.grid(linestyle=':') mp.xlabel('x') mp.ylabel('y') mp.scatter(x, y, s=60, marker='o', c='dodgerblue', label='Points') mp.plot(x, pred_y, c='orangered', label='LR Line') mp.tight_layout() mp.legend() mp.show()
输出结果:
平均绝对值误差: 1.0717908951634179
平均平方误差: 3.7362971803503267
中位绝对值误差: 0.696470799282414
R2得分: 0.44530850891980656