''' 线性回归: 输入 输出 0.5 5.0 0.6 5.5 0.8 6.0 1.1 6.8 1.4 7.0 ... y = f(x) 预测函数:y = w0+w1x x: 输入 y: 输出 w0和w1: 模型参数 所谓模型训练,就是根据已知的x和y,找到最佳的模型参数w0 和 w1,尽可能精确地描述出输入和输出的关系。 如:5.0 = w0 + w1 × 0.5 5.5 = w0 + w1 × 0.6 单样本误差:根据预测函数求出输入为x时的预测值:y' = w0 + w1x,单样本误差为1/2(y' - y)2。 总样本误差:把所有单样本误差相加即是总样本误差:1/2 Σ(y' - y)2 损失函数:loss = 1/2 Σ(w0 + w1x - y)2 损失函数就是总样本误差关于模型参数w0 w1的函数,该函数属于三维数学模型,即需要找到一组w0 w1使得loss取极小值。 示例:画图模拟梯度下降的过程 1>整理训练集数据,自定义梯度下降算法规则,求出w0 , w1 ,绘制回归线。 2>绘制随着每次梯度下降,w0,w1,loss的变化曲线。 3>基于三维曲面绘制梯度下降过程中的每一个点。 4>基于等高线的方式绘制梯度下降的过程。 ''' import numpy as np import matplotlib.pyplot as mp from mpl_toolkits.mplot3d import axes3d import warnings warnings.filterwarnings('ignore') train_x = np.array([0.5, 0.6, 0.8, 1.1, 1.4]) train_y = np.array([5.0, 5.5, 6.0, 6.8, 7.0]) # 实现梯度下降的过程 times = 1000 # 迭代次数 lrate = 0.01 # 学习率,取值不应太大 w0, w1 = [1], [1] # 初始化模型参数,记录每次梯度下降的参数 losses = [] # 保存每次迭代过程中损失函数值 epoches = [] # 保存每次迭代过程的索引 for i in range(1, times + 1): # 输出每次下降时:w0,w1,loss值的变化 epoches.append(i) loss = ((w0[-1] + w1[-1] * train_x - train_y) ** 2).sum() / 2 losses.append(loss) print('{:4}> w0={:.6f},w1={:.6f},loss={:.6f}'.format(epoches[-1], w0[-1], w1[-1], losses[-1])) # 每次梯度下降过程,需要求出w0和w1的修正值,求修正值需要推导loss函数在w0及w1方向的偏导数 d0 = (w0[-1] + w1[-1] * train_x - train_y).sum() d1 = ((w0[-1] + w1[-1] * train_x - train_y) * train_x).sum() # w0和w1的值不断修正 w0.append(w0[-1] - lrate * d0) w1.append(w1[-1] - lrate * d1) print(w0[-1], w1[-1]) pred_y = w0[-1] + w1[-1] * train_x # 绘制样本点 mp.figure('Linear Regression', facecolor='lightgray') mp.title('Linear Regression') mp.grid(linestyle=':') mp.scatter(train_x, train_y, s=60, c='orangered', label='Samples', marker='o') # 绘制回归线 mp.plot(train_x, pred_y, color='dodgerblue', label='Regression Line') mp.legend() # 绘制随着每次梯度下降,w0,w1,loss的变化曲线。 mp.figure('BGD Params', facecolor='lightgray') mp.title('BGD Params') mp.tick_params(labelsize=10) mp.subplot(311) mp.title('w0') mp.plot(epoches, w0[:-1], color='dodgerblue', label='w0') mp.grid(linestyle=':') mp.legend() mp.subplot(312) mp.title('w1') mp.plot(epoches, w1[:-1], color='orangered', label='w1') mp.grid(linestyle=':') mp.legend() mp.subplot(313) mp.title('loss') mp.plot(epoches, losses, color='yellowgreen', label='loss') mp.grid(linestyle=':') mp.legend() # 基于三维曲面绘制梯度下降过程中的每一个点。 # 整理网格点坐标矩阵,计算每个点的loss绘制曲面 grid_w0, grid_w1 = np.meshgrid(np.linspace(0, 9, 500), np.linspace(0, 3.5, 500)) grid_loss = np.zeros_like(grid_w0) for x, y in zip(train_x, train_y): grid_loss += ((grid_w0 + grid_w1 * x - y) ** 2) / 2 # 绘制3D损失函数图 mp.figure('Loss Function', facecolor='lightgray') ax3d = mp.gca(projection='3d') ax3d.set_xlabel('w0') ax3d.set_ylabel('w1') ax3d.set_zlabel('loss') ax3d.plot_surface(grid_w0, grid_w1, grid_loss, cmap='jet') # 绘制3D梯度下降曲线图 ax3d.plot(w0[:-1], w1[:-1], losses, 'o-', color='orangered', label='BGD', zorder=3) mp.tight_layout() # 基于等高线的方式绘制梯度下降的过程。 mp.figure('BGD Contour', facecolor='lightgray') mp.title('BGD Contour') mp.xlabel('w0') mp.ylabel('w1') mp.grid(linestyle=':') cntr = mp.contour(grid_w0, grid_w1, grid_loss, c='black', linewidths=0.5) mp.clabel(cntr, fmt='%.2f', inline_spacing=0.2, fontsize=8) mp.contourf(grid_w0, grid_w1, grid_loss, cmap='jet') mp.plot(w0[:-1], w1[:-1], c='orangered', label='BGD') mp.legend() mp.show()
输出结果:
4.065692318299849 2.2634176028710415
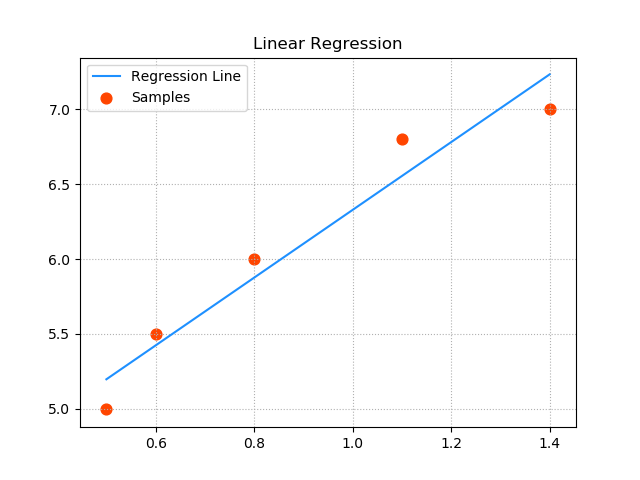
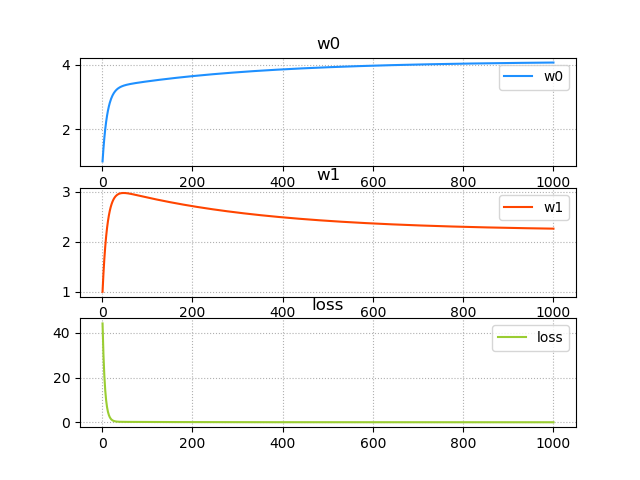
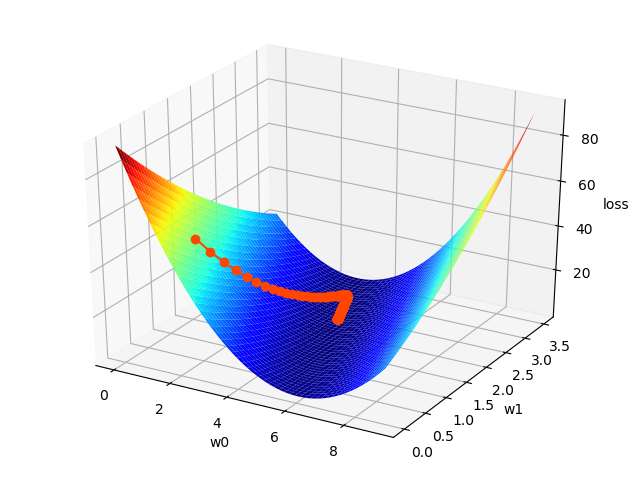

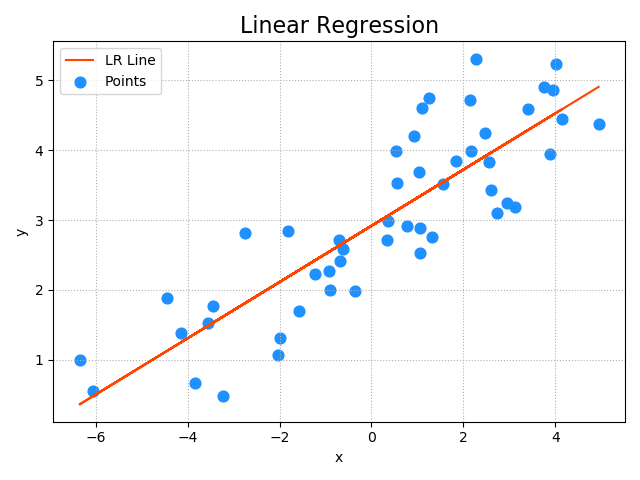
''' sklearn中处理线性回归问题的API: import sklearn.linear_model as lm # 创建模型 model = lm.LinearRegression() # 训练模型 # 输入为一个二维数组表示的样本矩阵 # 输出为每个样本最终的结果 model.fit(输入, 输出) # 训练模型 # 预测输出 # 输入array是一个二维数组,每一行是一个样本,每一列是一个特征。 result = model.predict(array) 评估训练结果误差(metrics)---模型评估 线性回归模型训练完毕后,可以利用测试集评估训练结果误差。sklearn.metrics提供了计算模型误差的几个常用算法: import sklearn.metrics as sm # 平均绝对值误差:1/m∑|实际输出-预测输出| sm.mean_absolute_error(y, pred_y) # 平均平方误差:SQRT(1/mΣ(实际输出-预测输出)^2) sm.mean_squared_error(y, pred_y) # 中位绝对值误差:MEDIAN(|实际输出-预测输出|) sm.median_absolute_error(y, pred_y) # R2得分,(0,1]区间的分值。分数越高,误差越小。---应用多 sm.r2_score(y, pred_y) 模型的保存和加载:---持久化存储 1>模型训练是一个耗时的过程,一个优秀的机器学习模型是非常宝贵的。 可以将模型保存到磁盘中,也可以在需要使用的时候从磁盘中重新加载模型即可。不需要重新训练(即model.fit())。 2>模型保存和加载相关API: import pickle pickle.dump(model, 磁盘文件) # 保存模型 model = pickle.load(磁盘文件) # 加载模型 示例:基于一元线性回归训练single.txt中的训练样本,使用模型预测测试样本。 步骤:整理数据----->训练模型----->绘制图像----->评估模型 ''' import numpy as np import sklearn.linear_model as sl import matplotlib.pyplot as mp import sklearn.metrics as sm # 采集数据 x, y = np.loadtxt('./ml_data/single.txt', delimiter=',', usecols=(0, 1), unpack=True) print(x.shape) print(y.shape) # 把输入变成二维数组,一行一样本,一列一特征 x = x.reshape(-1, 1) # 变成n行1列 model = sl.LinearRegression() model.fit(x, y) pred_y = model.predict(x) # 把样本x带入模型求出预测y # 输出模型的评估指标 print('平均绝对值误差:', sm.mean_absolute_error(y, pred_y)) print('平均平方误差:', sm.mean_squared_error(y, pred_y)) print('中位绝对值误差:', sm.median_absolute_error(y, pred_y)) print('R2得分:', sm.r2_score(y, pred_y)) # 绘制图像 mp.figure("Linear Regression", facecolor='lightgray') mp.title('Linear Regression', fontsize=16) mp.tick_params(labelsize=10) mp.grid(linestyle=':') mp.xlabel('x') mp.ylabel('y') mp.scatter(x, y, s=60, marker='o', c='dodgerblue', label='Points') mp.plot(x, pred_y, c='orangered', label='LR Line') mp.tight_layout() mp.legend() mp.show() 输出结果: (50,) (50,) 平均绝对值误差: 0.5482812185435971 平均平方误差: 0.43606903238180605 中位绝对值误差: 0.5356597030142565 R2得分: 0.736263899848181
''' 模型的保存和加载:---持久化存储 1>模型训练是一个耗时的过程,一个优秀的机器学习模型是非常宝贵的。 可以将模型保存到磁盘中,也可以在需要使用的时候从磁盘中重新加载模型即可。不需要重新训练(即model.fit())。 2>模型保存和加载相关API: import pickle pickle.dump(model, 磁盘文件) # 保存模型 model = pickle.load(磁盘文件) # 加载模型 示例:把训练好的模型保存到磁盘中。 ''' import numpy as np import sklearn.linear_model as sl import matplotlib.pyplot as mp import sklearn.metrics as sm import pickle # 采集数据 x, y = np.loadtxt('./ml_data/single.txt', delimiter=',', usecols=(0, 1), unpack=True) print(x.shape) print(y.shape) # 把输入变成二维数组,一行一样本,一列一特征 x = x.reshape(-1, 1) # 变成n行1列 model = sl.LinearRegression() model.fit(x, y) # 保存模型 with open('./lr.pkl', 'wb') as f: pickle.dump(model, f) print('Dump Success!') 输出结果: (50,) (50,) Dump Success!
''' 模型的保存和加载:---持久化存储 1>模型训练是一个耗时的过程,一个优秀的机器学习模型是非常宝贵的。 可以将模型保存到磁盘中,也可以在需要使用的时候从磁盘中重新加载模型即可。不需要重新训练(即model.fit())。 2>模型保存和加载相关API: import pickle pickle.dump(model, 磁盘文件) # 保存模型 model = pickle.load(磁盘文件) # 加载模型 示例:加载模型。 ''' import numpy as np import sklearn.linear_model as sl import matplotlib.pyplot as mp import sklearn.metrics as sm import pickle # 采集数据 x, y = np.loadtxt('./ml_data/single.txt', delimiter=',', usecols=(0, 1), unpack=True) # 从文件中加载模型 with open('./lr.pkl', 'rb') as f: model = pickle.load(f) # 把样本带入模型中求预测y pred_y = model.predict(x.reshape(-1, 1)) # 输出模型的评估指标 print('平均绝对值误差:', sm.mean_absolute_error(y, pred_y)) print('平均平方误差:', sm.mean_squared_error(y, pred_y)) print('中位绝对值误差:', sm.median_absolute_error(y, pred_y)) print('R2得分:', sm.r2_score(y, pred_y)) # 绘制图像 mp.figure("Linear Regression", facecolor='lightgray') mp.title('Linear Regression', fontsize=16) mp.tick_params(labelsize=10) mp.grid(linestyle=':') mp.xlabel('x') mp.ylabel('y') mp.scatter(x, y, s=60, marker='o', c='dodgerblue', label='Points') mp.plot(x, pred_y, c='orangered', label='LR Line') mp.tight_layout() mp.legend() mp.show()
输出结果:
平均绝对值误差: 0.5482812185435971
平均平方误差: 0.43606903238180605
中位绝对值误差: 0.5356597030142565
R2得分: 0.736263899848181
