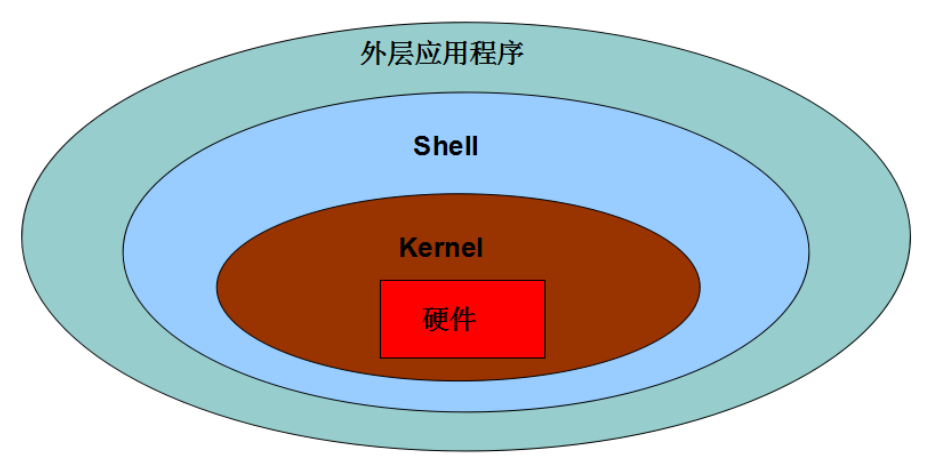
一、多任务编程
1. 意义: 充分利用计算机多核资源,提高程序的运行效率。
2. 实现方案 :多进程 , 多线程


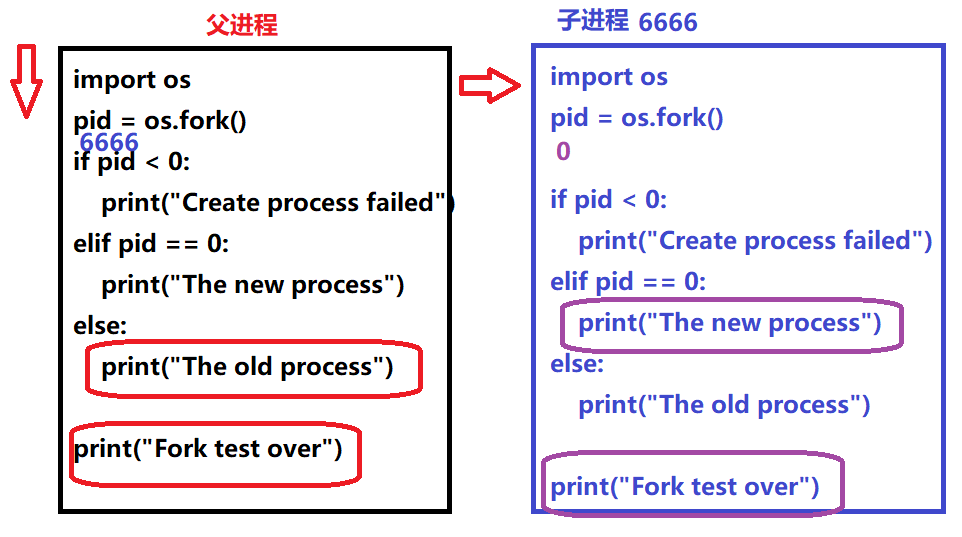
""" fork函数演示 如果不是并行/并发执行,则该代码执行时间在11秒,否则6秒 """ import os from time import sleep pid = os.fork() if pid < 0: print("Create process failed") elif pid == 0: sleep(5) print("Create new process") else: sleep(6) print("The old process") print("Fork test over")
""" 父子进程独立空间运行验证 """ import os from time import sleep print("==================") #只会在父进程里打印一条,不会再子进程打印 a = 1 #变量赋值是开辟新的空间的,子进程时深拷贝父进程内存空间的,因此在子进程里可以对a操作 pid = os.fork() if pid < 0: print("Error") elif pid == 0: print('Child process') print("child a = %d"%a) a = 10000 else: sleep(1) print("Parent process") print("parent a = %d"%a) print("global a = %d"%a)
""" 获取父子进程的pid号 """ import os pid = os.fork() if pid < 0: print("Error") elif pid == 0: print("child PID:",os.getpid()) print("parent PID:",os.getppid()) else: print("parent PID:",os.getpid()) print("child PID:",pid) parent PID: 10693 child PID: 10694 child PID: 10694 parent PID: 10693
""" 两种进程退出方式 """ import os import sys # os._exit(1) #程序运行至此退出,后面的打印不会执行 # sys.exit() #程序运行至此退出,后面的打印不会执行 sys.exit("进程退出") #程序运行至此退出,后面的打印不会执行 print("Process exit")
""" 父子进程退出方式 """ import os import sys pid = os.fork() if pid < 0: print("Error") elif pid == 0: sys.exit("退出进程") print("Child process") else: sys.exit("退出进程") print("parent process") print("all process")
""" 孤儿进程 """ import os from time import sleep pid = os.fork() if pid < 0: print("Error") elif pid == 0: sleep(2) print("child PID:",os.getpid()) print("get parent PID:",os.getppid()) else: print("parent PID:",os.getpid()) print("child PID:",pid) 在终端可以验证,在pycharm不行,结果为: parent PID: 18506 ----生父 child PID: 18507 child PID: 18507 get parent PID: 2625 ----养父(操作系统创建的进程)
""" 僵尸进程验证----模拟服务器(一般很长时间不退出) """ import os pid = os.fork() if pid < 0: print("Error") elif pid == 0: print("child process",os.getpid()) else: "不让父进程退出" while True: pass 此时在终端执行:ps -aux可以看见子进程变成了僵尸(Z)
""" 僵尸处理方法------os.wait() """ import os pid = os.fork() if pid < 0: print("Error") elif pid == 0: print("child process",os.getpid()) os._exit(2) else: pid,status = os.wait() #等待处理僵尸 print("pid",pid) print("status",status) while True: pass 输出结果: child process 26843 pid 26843 status 512 ------2*256 此时在终端用ps -aux查询子进程状态可见其不是(Z)状态,即不是僵尸
""" 僵尸处理方法------os.waitpid(pid,option) """ import os pid = os.fork() if pid < 0: print("Error") elif pid == 0: print("child process",os.getpid()) os._exit(2) else: pid,status = os.waitpid(-1,os.WNOHANG) #此时是非阻塞,当打印的pid和status均为0说明子进程还没有结束,否则可以回收子进程,完全看运气,如果采用隔一段时间循环一次,则类似垃圾回收机制 print("pid",pid) print("status",status) while True: pass
""" 创建二级子进程防止僵尸进程----利用孤儿进程,与父进程一起完成事物,相互独立,同时运行 """ import os from time import * def f1(): for i in range(4): sleep(2) print("写代码.....") def f2(): for i in range(5): sleep(1) print("测试代码.....") pid = os.fork() if pid < 0: print("Error") elif pid == 0: p = os.fork() #二级子进程 if p == 0: f2() #二级子进程执行 else: os._exit(0) else: os.wait() f1()
""" 信号方法处理僵尸 """ import os import signal #处理子进程退出,即让父进程忽略所有子进程退出行为,由操作系统处理僵尸 signal.signal(signal.SIGCHLD,signal.SIG_IGN) pid = os.fork() if pid < 0: print("Error") elif pid == 0: print("child PID:",os.getpid()) else: while True: pass
""" 客户端 """ from socket import * import os,sys #服务器地址 ADDR = ("176.61.14.181",8888) #发送消息 def send_msg(s,name): while True: try: text = input("发言:") except KeyboardInterrupt: text = "quit" #退出聊天室 if text == 'quit': msg = "Q " + name s.sendto(msg.encode(),ADDR) sys.exit("退出聊天室") msg = "C %s %s" % (name,text) s.sendto(msg.encode(),ADDR) #接收消息 def recv_msg(s): while True: data,addr = s.recvfrom((2048)) #服务端发送EXIT表示让客户端退出 if data.decode() == "EXIT": sys.exit("退出聊天室") print(data.decode() + " 发言:",end="") #创建网络连接 def main(): s = socket(AF_INET,SOCK_DGRAM) while True: name = input("Name:") msg = "L " + name s.sendto(msg.encode(),ADDR) #等待服务端回应 data,addr = s.recvfrom(1024) if data.decode() == "OK": print("您已进入聊天室") break else: print(data.decode()) #创建新的进程,子进程复制发消息,父进程复制接收消息 pid = os.fork() if pid < 0: sys.exit("Error!") elif pid ==0: send_msg(s,name) else: recv_msg(s) if __name__ == "__main__": main()
""" 服务端 基础知识:socket fork """ from socket import * import os,sys #服务器地址 ADDR = ("0.0.0.0",8888) #存户用户信息 user = {} #进入聊天室 def do_login(s,name,addr): if name in user or "管理员" in name: s.sendto("该用户已存在".encode(),addr) return s.sendto(b"OK",addr) #通知其他人 msg = " 欢迎%s进入聊天室"%name for i in user: s.sendto(msg.encode(),user[i]) #将用户加入 user[name] = addr #聊天 def do_chat(s,name,text): msg = " %s:%s"%(name,text) for i in user: if i != name: s.sendto(msg.encode(),user[i]) #退出聊天室 def do_quit(s,name): msg = " %s退出了聊天室"%name for i in user: if i !=name: s.sendto(msg,user[i]) else: s.sendto(b"EXIT",user[i]) #将用户删除 del user[name] #处理客户端请求 def do_request(s): while True: data,addr = s.recvfrom(1024) msg = data.decode().split(" ") #区分请求类型 if msg[0] == "L": do_login(s,msg[1],addr) elif msg[0] == "C": text = ' '.join(msg[2:]) do_chat(s,msg[1],text) elif msg[0] == 'Q': if msg[1] not in user: s.sendto(b"EXIT",addr) continue do_quit(s,msg[1]) #创建网络连接 def main(): #创建套接字 s = socket(AF_INET,SOCK_DGRAM) s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) s.bind(ADDR) pid = os.fork() if pid < 0: return elif pid == 0: #发送管理员消息 while True: msg = input("管理员消息:") msg = "C 管理员消息 " + msg s.sendto(msg,ADDR) else: #对接收的请求处理 do_request(s) #处理客户端请求 if __name__ == "__main__": main()
""" multiprocessing创建多进程 """ import multiprocessing from time import sleep import os #子进程函数 def fun(): print("子进程后开始执行了") sleep(3) print("子进程执行完毕") #创建进程函数 p = multiprocessing.Process(target=fun) #启动进程,此时函数fun作为进程的独立部分运行 p.start() #想体现父子进程同时执行,父进程必须写在start和join之间,如果写在start前父进程先执行,若写在join后,则子进程退出后才执行 sleep(2) print("父进程干点事") #回收进程,以防产生僵尸进程 p.join() # 上述代码用fork实现如下 pid = os.fork() if pid == 0: fun() os._exit(0) else: sleep(2) print("父进程干点事") os.wait()
""" multiprocessing创建多进程-------父子进程独立运行,互不干扰 """ import multiprocessing from time import sleep import os a = 1 #子进程函数 def fun(): print("子进程后开始执行了") global a print("a = ",a) a = 10000 sleep(3) print("子进程执行完毕") #创建进程函数 p = multiprocessing.Process(target=fun) #启动进程,此时函数fun作为进程的独立部分运行 p.start() #想体现父子进程同时执行,父进程必须写在start和join之间,如果写在start前父进程先执行,若写在join后,则子进程退出后才执行 sleep(2) print("父进程干点事") #回收进程,以防产生僵尸进程 p.join() print("parent a = ",a) 运行结果: 子进程后开始执行了 a = 1 父进程干点事 子进程执行完毕 parent a = 1
""" 使用multiprocessing创建多个子进程 """ import multiprocessing from time import sleep import os def th1(): sleep(3) print("吃饭") print(os.getppid(),"====",os.getpid()) def th2(): sleep(2) print("睡觉") print(os.getppid(),"====",os.getpid()) def th3(): sleep(4) print("打豆豆") print(os.getppid(),"====",os.getpid()) things = [th1,th2,th3] jobs = [] for th in things: p = multiprocessing.Process(target=th) jobs.append(p) #用列表保存进程对象 p.start() for i in jobs: i.join() 运行结果: 睡觉 124561 ==== 124567 吃饭 124561 ==== 124566 打豆豆 124561 ==== 124568
带参数的multiprocessing
"""
from time import sleep
def worker(sec,name):
for i in range(3):
sleep(sec)
print("I'm %s"%name)
print("I'm working....")
# p =Process(target=worker,kwargs={"name":"Jame","sec":2})
p = Process(target=worker,args=(2,),kwargs={"name":"Jame"})
p.start()
p.join()
运行结果: I'm Jame I'm working.... I'm Jame I'm working.... I'm Jame I'm working....
""" Process进程对象属性 """ from multiprocessing import Process from time import sleep,ctime def tm(): for i in range(3): sleep(2) print(ctime()) p = Process(target=tm,name="haha") #子进程随父进程一起退出 p.daemon = True #daemon与join选择其一,从来防止僵尸进程,也可以用signal.signal(signal.SIGCHLD,signal.SIG_IGN)处理僵尸 p.start() print("Name:",p.name) print("PID;",p.pid) print("Is_alive:",p.is_alive()) 输出结果: Name: haha PID; 9537 Is_alive: True
""" 进程池原理示例 """ from multiprocessing import Pool from time import sleep,ctime #进程池事件 def worker(msg): sleep(2) print(msg) #创建进程池 pool = Pool() #向进程池添加事件 for i in range(20): msg = "Hello %d"%i pool.apply_async(func=worker,args=(msg,)) #关闭进程池----当运行close时就不能往进程池例添加事件了 pool.close() #回收进程池----将进程池里的时间处理完毕,进程池就会被回收 pool.join() 输出结果(因选择系统默认创建的进程个数,因此运行时是两个两个并发执行输出,其他的在队列等待) Hello 0 Hello 1 Hello 2 Hello 3 Hello 4 Hello 5 Hello 6 Hello 7 Hello 8 Hello 9 Hello 10 Hello 11 Hello 12 Hello 13 Hello 14 Hello 15 Hello 16 Hello 17 Hello 18 Hello 19
""" 管道通信---双向管道 """ from multiprocessing import Pipe,Process import os,time #创建管道: fd1,fd2 = Pipe() def fun(name): time.sleep(3) #向管道写入内容 fd1.send({name:os.getpid()}) jobs = [] #子进程写管道 for i in range(5): p = Process(target=fun,args=(i,)) jobs.append(p) p.start() #父进程读管道 for i in range(5): #读取管道 data = fd2.recv() print(data) for i in jobs: i.join() 输出结果: {3: 32720} {2: 32719} {1: 32718} {4: 32721} {0: 32717}
""" 管道通信---单向管道(fd1只能读,fd2只能写) """ from multiprocessing import Pipe,Process import os,time #创建管道: fd1,fd2 = Pipe() def fun(name): time.sleep(3) #向管道写入内容 fd2.send({name:os.getpid()}) jobs = [] #子进程写管道 for i in range(5): p = Process(target=fun,args=(i,)) jobs.append(p) p.start() #父进程读管道 for i in range(5): #读取管道 data = fd1.recv() print(data) for i in jobs: i.join() 输出结果: {3: 35102} {2: 35101} {0: 35099} {4: 35103} {1: 35100}
""" 消息队列通信
一个进程提出需求,一个进程处理需求 """ from multiprocessing import Queue,Process from random import randint from time import sleep #创建消息队列 q = Queue(3) def request(): for i in range(20): x= randint(0,100) y = randint(0,100) q.put((x,y)) def handle(): while True: sleep(0.5) try: x,y = q.get(timeout=3) except: break else: print("%d + %d = %d"%(x,y,(x + y))) p1 = Process(target=request) p2 = Process(target=handle) p1.start() p2.start() p1.join() p2.join() 输出结果: 7 + 6 = 13 85 + 53 = 138 39 + 43 = 82 45 + 66 = 111 57 + 10 = 67 43 + 2 = 45 29 + 51 = 80 71 + 42 = 113 2 + 16 = 18 58 + 7 = 65 34 + 6 = 40 3 + 91 = 94 11 + 47 = 58 22 + 39 = 61 64 + 94 = 158 99 + 10 = 109 28 + 0 = 28 100 + 56 = 156 30 + 66 = 96 94 + 68 = 162

""" 共享内存通信(单个数值)---男的挣钱,女的花钱,月末剩余多少? """ from multiprocessing import Value,Process import time import random #创建共享内存 money = Value("i",5000) #操作共享内存 def man(): for i in range(30): money.value += random.randint(1,1000) def girl(): for i in range(30): time.sleep(0.15) money.value -= random.randint(100,800) m = Process(target=man) g = Process(target=girl) m.start() g.start() m.join() g.join() #获取共享内存的值 print("一个月的余额:",money.value) 输出结果: 一个月的余额: 8639
""" 共享内存通信(多个数据)-----对共享内存修改查看 """ from multiprocessing import Array,Process #创建共享内存,制定共享内存开辟5个整型列表空间 shm = Array("i",[5,6,7,2,9]) def fun(): #共享内存对象---可迭代 for i in shm: print(i) shm[2] = 99 p = Process(target=fun) p.start() p.join() print("-----------------") for i in shm: print(i) 输出结果: 5 6 7 2 9 ----------------- 5 6 99 2 9
""" 共享内存通信(多个数据)-----对共享内存修改查看(字节串数据结构) """ from multiprocessing import Array,Process #创建共享内存,制定共享内存开辟5个整型列表空间 shm = Array("c",b"hello") def fun(): #共享内存对象---可迭代 for i in shm: print(i) shm[2] = b'H' p = Process(target=fun) p.start() p.join() print("-----------------") for i in shm: print(i) print("-----------------") print(shm.value) 输出结果: b'h' b'e' b'l' b'l' b'o' ----------------- b'h' b'e' b'H' b'l' b'o' ----------------- b'heHlo'
""" 接收端 """ from socket import * import os #确定本地套接字文件,这个也可以暂时不创建,在绑定的时候,系统会自动创建 sock_file = "./sock" #判断文件是否存在,存在就删除 if os.path.exists(sock_file): os.remove(sock_file) #创建本地套接字 sockfd = socket(AF_UNIX,SOCK_STREAM) #绑定本地套接字 sockfd.bind(sock_file) #监听连接 sockfd.listen(3) while True: #这个连接仅仅是应用层的通信连接,而不是网络连接 c,addr = sockfd.accept() while True: data = c.recv(1024) if not data: break print(data.decode()) c.close() sockfd.close() """ 发送端 """ from socket import * #确保两端使用相同的套接字文件 sock_file = "./sock" #创建本地套接字 sockfd = socket(AF_UNIX,SOCK_STREAM) sockfd.connect(sock_file) while True: msg = input(">>").encode() if not msg: break sockfd.send(msg) sockfd.close()
""" 信号量信息传递 """ from multiprocessing import Semaphore,Process from time import sleep import os #创建信号量 #服务程序最多允许3个进程同时执行事件 sem = Semaphore(3) def handle(): print("%d 想执行事件"%os.getpid()) #想执行事件必须获取信号量 sem.acquire() print("%d 开始执行操作"%os.getpid()) sleep(3) print("%d 完成操作"%os.getpid()) sem.release() #增加信号量 jobs = [] #有5个进程请求执行事件 for i in range(5): p = Process(target=handle) jobs.append(p) p.start() for i in jobs: i.join() #打印最终的信号量个数 print(sem.get_value()) 输出结果: 103160 想执行事件 103160 开始执行操作 103161 想执行事件 103161 开始执行操作 103162 想执行事件 103162 开始执行操作 103163 想执行事件 103164 想执行事件 103160 完成操作 103163 开始执行操作 103161 完成操作 103164 开始执行操作 103162 完成操作 103163 完成操作 103164 完成操作 3
习题1:
""" multiprocess创建两个进程,同时复制一个文件的上下两半部分,各自复制到一个新的文件里 """ from multiprocessing import Process import os filename = "./520.jpg" #获取图片大小 size = os.path.getsize(filename) #复制上半部分 def get_top(): f = open(filename,'rb') n = size // 2 fw = open("top.jpg",'wb') fw.write(f.read(n)) f.close() fw.close() #下半部分 def get_bot(): f = open("520.jpg",'rb') fw = open("bot.jpg",'wb') f.seek(size//2,0) while True: data = f.read(1024) if not data: break fw.write(data) f.close() fw.close() #创建进程 p1 = Process(target=get_top) p2 = Process(target=get_bot) p1.start() p2.start() p1.join() p2.join()
""" multiprocess创建两个进程,同时复制一个文件的上下两半部分,各自复制到一个新的文件里 ---把要复制的图片打开代码放在父进程里,同时在获取上半部图片的子进程函数设置延迟阻塞,可以看到上半部的图片大小为零 ---原因:程序在执行时,父进程先创建文件对象,当执行到创建子进程时,会将这个对象传递给两个子进程,导致父子进程共用一个文件对象 三者任意一个进程对该文件的操作都会影响其他进程对该文件的操作,此外,在两个子进程重新打开文件,则互不影响 """ from multiprocessing import Process import os from time import sleep filename = "./520.jpg" #获取图片大小 size = os.path.getsize(filename) f = open(filename,"rb") #复制上半部分 def get_top(): sleep(1) # f = open(filename,'rb') n = size // 2 fw = open("top.jpg",'wb') fw.write(f.read(n)) # f.close() fw.close() #下半部分 def get_bot(): # f = open(filename,'rb') fw = open("bot.jpg",'wb') f.seek(size//2,0) while True: data = f.read(1024) if not data: break fw.write(data) # f.close() fw.close() #创建进程 p1 = Process(target=get_top) p2 = Process(target=get_bot) p1.start() p2.start() p1.join() p2.join() f.close()
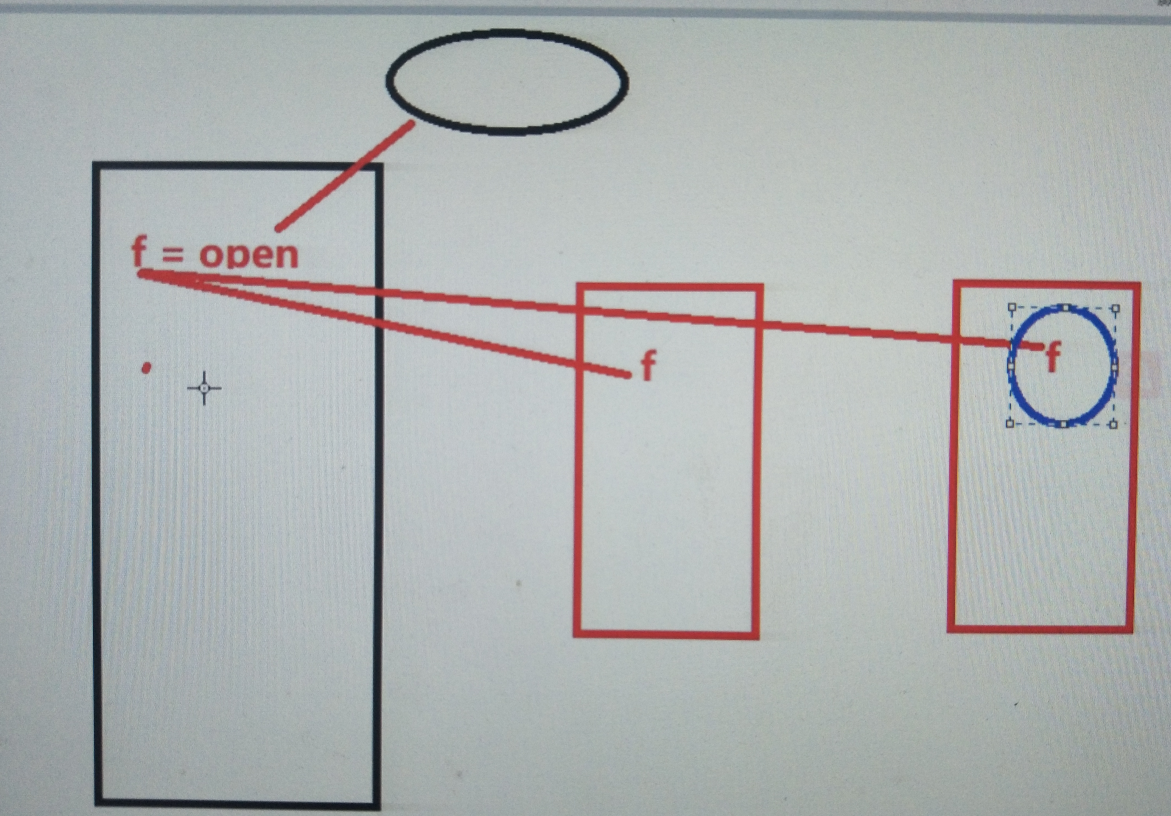
注:如果父进程中打开文件,创建进程通信对象或者创建套接字,子进程会从父进程内存空间获取这些内容,那么父子进程对该对象的操作会有一定的属性关联(共用同一个对象)
白话:上述代码的本质就是进程间的通信:父进程创建对象,子进程继承父进程创建的对象,与消息队列,管道,共享内存等进程间信息交互如出一辙(父进程创建进程间通信对象,子进程继承这个对象)
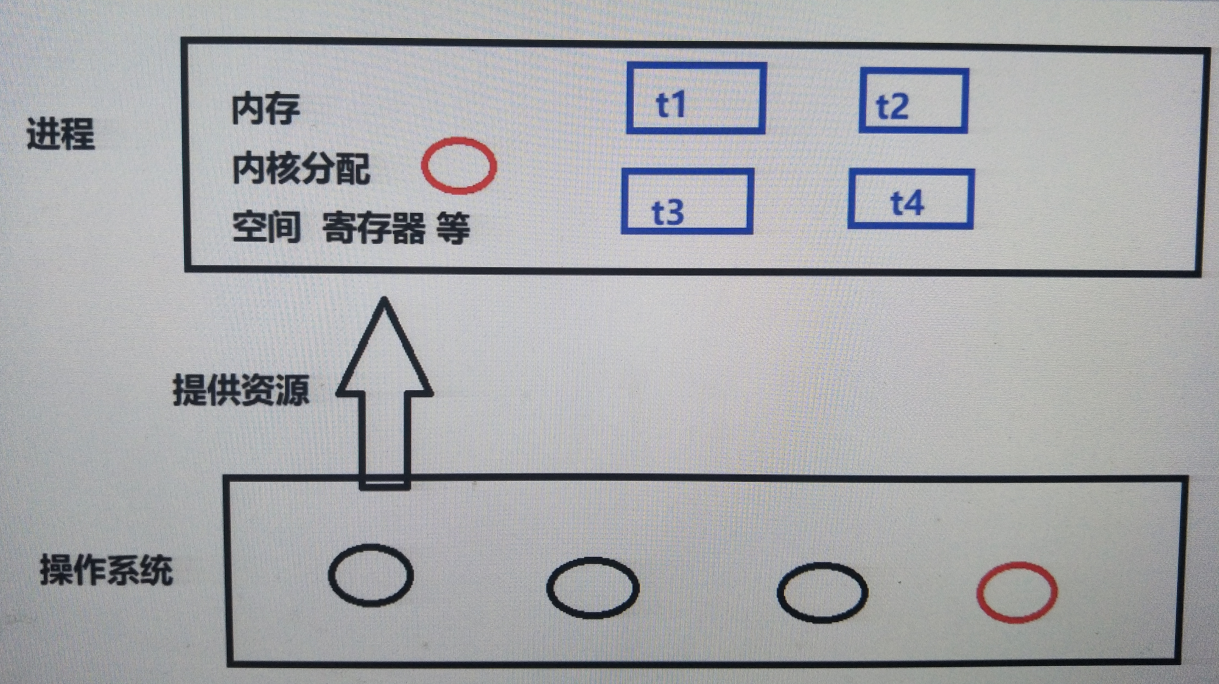
""" 线程创建示例 ---此示例有两个线程,启动程序的称为主线程,播放音乐的为分支线程,共同构成一个进程 ---由PID可以看出,两个线程同属一个进程 ---a变量是两个线程公用的资源,因此在一个线程对a进行操作,另一个线程使用这个变量时也会受影响,即进程空间信息相当于线程全局变量 """ import threading from time import sleep import os a = 1 #线程函数 def music(): global a print("a = ", a) a = 10000 for i in range(5): sleep(2) print("播放《心如止水》",os.getpid()) #创建线程对象(分支线程) t = threading.Thread(target=music) t.start() #主线程任务 for i in range(3): sleep(3) print("播放《跳舞吧》",os.getpid()) t.join() #回收线程 print("Main thread a = ",a) 输出结果: a = 1 播放《心如止水》 9022 播放《跳舞吧》 9022 播放《心如止水》 9022 播放《跳舞吧》 9022 播放《心如止水》 9022 播放《心如止水》 9022 播放《跳舞吧》 9022 播放《心如止水》 9022 Main thread a = 10000
""" 线程传参 """ from threading import Thread from time import sleep #含参数的线程函数 def fun(sec,name): print("线程函数传参") sleep(sec) print("%s 线程执行完毕"%name) #创建多个线程 jobs = [] for i in range(5): t = Thread(target=fun,args=(2,),kwargs={"name":"T%d"%i}) jobs.append(t) t.start() for i in jobs: i.join() 输出结果: 线程函数传参 线程函数传参 线程函数传参 线程函数传参 线程函数传参 T1 线程执行完毕 T3 线程执行完毕 T2 线程执行完毕 T4 线程执行完毕 T0 线程执行完毕
""" 线程属性 """ from threading import Thread from time import sleep def fun(): sleep(3) print("线程属性测试") t = Thread(target=fun,name="Hobby") #主线程退出,分支线程也随之退出 t.setDaemon(True) t.start() #修改线程名称 t.setName("Back") #线程名称 print("Thread name:",t.getName()) #线程生命周期 print("Is alive:",t.is_alive()) 输出结果: Thread name: Back Is alive: True
拓展:Python线程池,第三方模块:threadpool
""" 自定义线程类示例 """ from threading import Thread class ThreadClass(Thread): def __init__(self,attr): super().__init__() self.attr = attr #多个方法配合实现具体功能 def f1(self): print('步骤1',self.attr) def f2(self): print("步骤2",self.attr) def run(self): self.f1() self.f2() t = ThreadClass('****') t.start() #自动运行run方法 t.join() 输出结果: 步骤1 **** 步骤2 ****
from threading import Thread from time import sleep,ctime class MyThread(Thread): def __init__(self,target=None,args=(),kwargs={},name=None): super().__init__() self.target = target self.args = args self.kwargs = kwargs self.name = name def run(self): self.target(*self.args,**self.kwargs) # ********************************************** # 通过完成上面的Mythread类让整个程序可以正常执行 # 当调用start时player作为一个线程功能函数运行 # 注意:函数的名称和参数并不确定,player只是测试函数 # ********************************************** def player(sec,song): for i in range(2): print("Playing %s:%s"%(song,ctime())) sleep(sec) t = MyThread(target=player,args=(3,),kwargs={"song":"凉凉"},name="happy") t.start() t.join() 输出结果: Playing 凉凉:Tue May 21 12:40:24 2019 Playing 凉凉:Tue May 21 12:40:27 2019
同步互斥
线程间通信方法
1. 通信方法
线程间使用全局变量进行通信----会存在通信紊乱(比如:一个进程中有三个线程,两个线程在通信时,另一个线程也使用公共变量,导致信息传递有误),造成这种现象的原因:共享资源的争夺
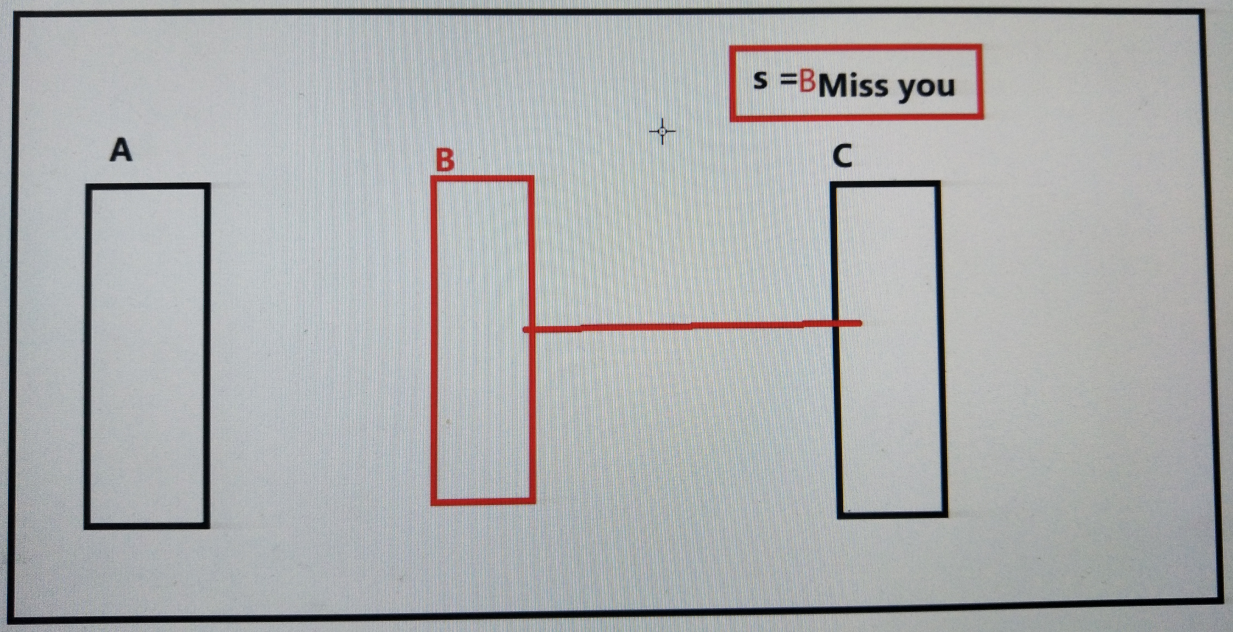
2. 共享资源争夺
共享资源:多个进程或者线程都可以操作的资源称为共享资源。对共享资源的操作代码段称为临界区。------线程更加明显,因为其使用全局变量
影响 : 对共享资源的无序操作可能会带来数据的混乱,或者操作错误。此时往往需要同步互斥机制协调操作顺序。
3. 同步互斥机制
同步 : 同步是一种协作关系,为完成操作,多进程或者线程间形成一种协调,按照必要的步骤有序执行操作。
比如:进程通信方式中的消息队列,管道等,一个先放,然后另一个取,就是一种同步
网络信息的收发机制,也是先发再收,一种同步协作关系
阻塞函数也是同步协作
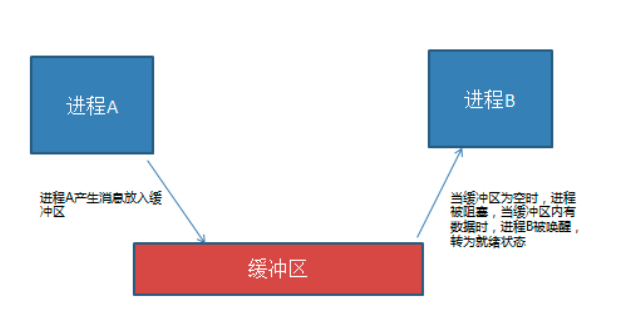
互斥 : 互斥是一种制约关系,当一个进程或者线程占有资源时会进行加锁处理,此时其他进程线程就无法操作该资源,直到解锁后才能操作。
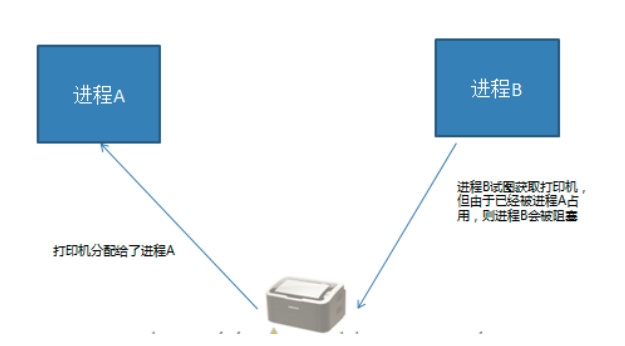
线程同步互斥方法:更准确的说是互斥方法
注:所有的互斥方法必然有阻塞行为和解除阻塞的行为
线程Event
from threading import Event
e = Event() 创建线程event对象
e.wait([timeout]) 阻塞等待e被set
e.set() 设置e,使wait结束阻塞
e.clear() 使e回到未被设置状态
e.is_set() 查看当前e是否被设置
""" Event事件: 必须分支线程对全局变量操作之后,主线程才能对全局变量操作 """ from threading import Thread,Event from time import sleep # 全局变量,用于通信 s = None #创建事件对象 e = Event() def yangzirong(): print("杨子荣前来拜山头") global s s = "天王盖地虎" # 共享资源操作完毕 e.set() t = Thread(target=yangzirong) t.start() print("说对口令就是自己人") # 阻塞等待 e.wait() if s == "天王盖地虎": print("宝塔镇河妖") print("确认过眼神,你是对的人") else: print("打死他...") t.join() 输出结果: 杨子荣前来拜山头 说对口令就是自己人 宝塔镇河妖 确认过眼神,你是对的人
线程锁 Lock
from threading import Lock
lock = Lock() 创建锁对象
lock.acquire() 上锁 如果lock已经上锁再调用会阻塞
lock.release() 解锁
with lock: 上锁
......
......
with代码块结束自动解锁
注:谁先运行到上锁,谁就有执行权,执行完后另外一个遇到上锁就会阻塞,上锁相当于增加了程序运行的原则性:一个线程上锁解锁中间的部分在执行的时候,其他线程不能对共享资源操作
""" Lock锁的应用 """ from threading import Lock,Thread a = b = 0 lock = Lock() def value(): while True: lock.acquire() #上锁 if a != b: print("a = %d,b = %d"%(a,b)) lock.release() #解锁 t = Thread(target=value) t.start() while True: with lock: a += 1 b += 1 t.join()
死锁及其处理
1. 定义
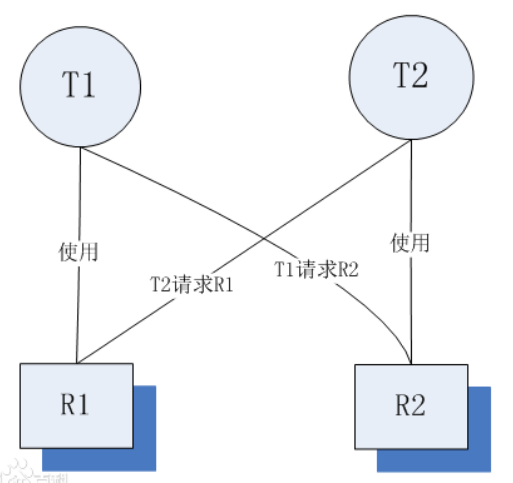
死锁是指两个或两个以上的线程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁。
示例:俩小孩交换东西
2. 死锁产生条件
死锁发生的必要条件(四个同时满足)
* 互斥条件:指线程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放。
* 请求和保持条件:指线程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求线程阻塞,但又对自己已获得的其它资源保持不放。
* 不剥夺条件:指线程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放,通常CPU内存资源是可以被系统强行调配剥夺的。
* 环路等待条件:指在发生死锁时,必然存在一个线程——资源的环形链,即进程集合{T0,T1,T2,···,Tn}中的T0正在等待一个T1占用的资源;T1正在等待T2占用的资源,……,Tn正在等待已被T0占用的资源。
死锁的产生原因
简单来说造成死锁的原因可以概括成三句话:
* 当前线程拥有其他线程需要的资源
* 当前线程等待其他线程已拥有的资源
* 都不放弃自己拥有的资源
3. 如何避免死锁
死锁是我们非常不愿意看到的一种现象,我们要尽可能避免死锁的情况发生。通过设置某些限制条件,去破坏产生死锁的四个必要条件中的一个或者几个,来预防发生死锁。预防死锁是一种较易实现的方法。
但是由于所施加的限制条件往往太严格,可能会导致系统资源利用率。
* 使用定时锁---加阻塞函数
* 使用重入锁RLock(),用法同Lock。RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次acquire。直到一个线程所有的acquire都被release,其他的线程才能获得资源。
""" 死锁预防案例----银行交易系统 ---先让一个线程先执行,再执行另一个线程,即加阻塞函数 """ import time import threading #交易类 class Account: def __init__(self,id,balance,lock): self.id = id # 用户 self.balance = balance # 银行存款 self.lock = lock # 锁 # 取钱 def withdraw(self,amount): self.balance -= amount # 存钱 def deposit(self,amount): self.balance += amount # 查看账户金额 def get_balance(self): return self.balance # 转账函数 def transfer(from_,to,amount): # 上锁成功返回true if from_.lock.acquire(): # 锁住自己的账户 from_.withdraw(amount) # 自己账户金额减少 time.sleep(0.5) if to.lock.acquire(): to.deposit(amount) # 对方账户金额增加 to.lock.release() # 对方账户解锁 from_.lock.release() # 自己账户解锁 print("转账完成") # 创建两个账户 Abby = Account("Abby",5000,threading.Lock()) Levi = Account("Levi",3000,threading.Lock()) t1 = threading.Thread(target=transfer,args=(Abby,Levi,1500)) t2 = threading.Thread(target=transfer,args=(Levi,Abby,1000)) t1.start() time.sleep(2) # 加阻塞延迟函数,避免死锁----让ti先执行,过两秒后,让t2再执行 t2.start() t1.join() t2.join() print("Abby:",Abby.get_balance()) print("Levi:",Levi.get_balance()) 运行结果: 转账完成 转账完成 Abby: 4500 Levi: 3500
""" 死锁预防案例----fun1重复上锁导致死锁 ---重载锁解决死锁 ---一般逻辑复杂的情况容易产生因多次上锁导致的死锁,因此用重载锁解锁 """ from threading import Thread,RLock from time import sleep num = 0 # 共享资源(全局变量) lock = RLock() # 重载锁:允许在一个线程内部允许对锁进行重复上锁 class MyThread(Thread): def fun1(self): global num with lock: num -= 1 def fun2(self): global num if lock.acquire(): num += 1 if num > 5: self.fun1() print("Num = ",num) lock.release() def run(self): while True: sleep(2) self.fun2() for i in range(10): t = MyThread() t.start() 输出结果: Num = 1 Num = 2 Num = 3 Num = 4 Num = 5 Num = 5 Num = 5 ......
python线程GIL----------python的一个bug
线程最大的问题:共享资源的争夺,这样涉及上锁,在应用层对一定资源上锁外,在解释器层同样有共享资源,Python线程创建需要解释器帮助,因此解释器也存在共享资源问题,为了解决这个问题,Python设计者就把解释器上锁,
使得解释器在同一时刻只解释一个线程就不会产生系统资源冲突,最终导致Python解释器在同一时刻只能解释一个线程,多核资源成了摆设(虽然可以利用计算机多核,但是同一时刻只能利用一个内核),
因此只有在高延迟或者IO阻塞时,Python多线程可以提高执行效率,对于计算密集型程序则没有(计算机虽然多核,但是同一时刻只有一个解释器在占有一个内核执行程序)而且效率比单线程还低(多线程来回切换消耗时间)
1. python线程的GIL问题 (全局解释器锁)
什么是GIL :由于python解释器设计中加入了解释器锁,导致python解释器同一时刻只能解释执行一个线程,大大降低了线程的执行效率。
导致后果: 因为遇到阻塞时线程会主动让出解释器,去解释其他线程。所以python多线程在执行多阻塞高延迟IO时可以提升程序效率,其他情况并不能对效率有所提升。
GIL问题建议:
* 尽量使用进程完成无阻塞的并发行为(等于没给建议)
* 不使用c作为解释器 (Java C#)
2. 结论 : 在无阻塞状态下,多线程程序和单线程程序执行效率几乎差不多,甚至还不如单线程效率。但是多进程运行相同内容却可以有明显的效率提升。
""" 单线程执行计算秘籍函数十次,记录时间,执行io秘籍函数十次,记录时间 """ import time # 计算密集型函数 x y 传入1,1 def count(x,y): c = 0 while c < 7000000: c += 1 x += 1 y += 1 # io密集型 def io(): write() read() def write(): f = open('test','w') for i in range(1500000): f.write("hello world ") f.close() def read(): f = open('test') lines = f.readlines() f.close() st = time.time() for i in range(10): # count(1,1) # Single CPU: 14.62774109840393 io() # print("Single CPU:",time.time()-st) # Single CPU: 14.62774109840393 print("Single IO:",time.time()-st) #Single IO: 8.693575382232666
""" 多线程执行计算秘籍函数十次,记录时间,执行io秘籍函数十次,记录时间 """ import time import threading # 计算密集型函数 x y 传入1,1 def count(x,y): c = 0 while c < 7000000: c += 1 x += 1 y += 1 # io密集型 def io(): write() read() def write(): f = open('test','w') for i in range(1500000): f.write("hello world ") f.close() def read(): f = open('test') lines = f.readlines() f.close() jobs = [] st = time.time() for i in range(10): # t = threading.Thread(target=count,args=(1,1)) t = threading.Thread(target=io) jobs.append(t) t.start() for i in jobs: i.join() # print("Thread cpu:",time.time()-st) # Thread cpu: 14.862890243530273 print("Thread io:",time.time()-st) # Thread io: 6.805188179016113
""" 多进程执行计算秘籍函数十次,记录时间,执行io秘籍函数十次,记录时间 """ import time import multiprocessing # 计算密集型函数 x y 传入1,1 def count(x,y): c = 0 while c < 7000000: c += 1 x += 1 y += 1 # io密集型 def io(): write() read() def write(): f = open('test','w') for i in range(1500000): f.write("hello world ") f.close() def read(): f = open('test') lines = f.readlines() f.close() jobs = [] st = time.time() for i in range(10): t = multiprocessing.Process(target=count,args=(1,1)) # t = multiprocessing.Process(target=io) jobs.append(t) t.start() for i in jobs: i.join() print("Process cpu:",time.time()-st) # Process cpu: 6.3905298709869385 # print("Process io:",time.time()-st) # Process io: 3.8089511394500732
注:由上面三个程序对比,如果Python中不存在GIL问题,则Python多线程与多进程执行效率基本相同,甚至更好
进程线程的区别联系
区别联系:
1. 两者都是多任务编程方式,都能使用计算机多核资源
2. 进程的创建删除消耗的计算机资源比线程多
3. 进程空间独立,数据互不干扰,有专门通信方法;线程使用全局变量通信
4. 一个进程可以有多个分支线程,两者有包含关系
5. 多个线程共享进程资源,在共享资源操作时往往需要同步互斥处理
6. 进程线程在系统中都有自己的特有属性标志,如ID,代码段,命令集等。
使用场景
1. 任务场景:如果是相对独立的任务模块,可能使用多进程,如果是多个分支共同形成一个整体任务可能用多线程
2. 项目结构:多中编程语言实现不同任务模块,可能是多进程,或者前后端分离应该各自为一个进程。
3. 难易程度:通信难度,数据处理的复杂度来判断用进程间通信还是同步互斥方法。
进程和线程重点知识:
1. 对进程线程的理解,进程线程的差异
2. 进程间通信方法,各有什么特点
3.同步互斥的定义及理解,使用场景,如何用
4. 给一个情形,可以判断使用进程还是线程,阐述原因
5.僵尸进程的处理,GIL问题,进程状态
四、并发网络通信模型
常见模型分类
1. 循环服务器模型 :循环接收客户端请求,处理请求。同一时刻只能处理一个请求,处理完毕后再处理下一个。-----TCP和UDP数据传输
优点:实现简单,占用资源少
缺点:无法同时处理多个客户端请求
适用情况:处理的任务可以很快完成,客户端无需长期占用服务端程序。udp比tcp更适合循环。
2. IO并发模型:利用IO多路复用,异步IO等技术,同时处理多个客户端IO请求。
优点 : 资源消耗少,能同时高效处理多个IO行为
缺点 : 只能处理并发产生的IO事件,无法处理cpu计算
适用情况:HTTP请求,网络传输等都是IO行为。
3. 多进程/线程网络并发模型:每当一个客户端连接服务器(TCP),就创建一个新的进程/线程为该客户端服务,客户端退出时再销毁该进程/线程。
优点:能同时满足多个客户端长期占有服务端需求,可以处理各种请求。
缺点: 资源消耗较大
适用情况:客户端同时连接量较少,需要处理行为较复杂情况。
基于fork的多进程网络并发模型
实现步骤:
1. 创建监听套接字
2. 等待接收客户端请求
3.服务端连接创建新的进程处理客户端请求
4. 原进程继续等待其他客户端连接
5. 如果客户端退出,则销毁对应的进程
""" 基于fork的多进程网络并发---需要处理僵尸进程 """ from socket import * import os,sys import signal def handle(c): print("客户端:",c.getpeername()) while True: data = c.recv(1024) if not data: break print(data.decode()) c.send(b'ok') c.close() # 创建监听套接字 HOST = '0.0.0.0' PORT = 8888 ADDR = (HOST,PORT) # 服务端地址 s = socket() # tcp套接字 s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) # 设置端口地址的立即重用 s.bind(ADDR) s.listen(3) # 僵尸进程的处理 signal.signal(signal.SIGCHLD,signal.SIG_IGN) print("Listen the port 8888...") # 循环等待客户端连接 while True: try: c,addr = s.accept() except KeyboardInterrupt: sys.exit("服务器退出") except Exception as e: print(e) continue # 创建子进程处理客户端请求 pid = os.fork() if pid == 0: s.close() # 子进程不需要s handle(c) # 具体处理客户端请求 os._exit(0) # 父进程实际只用来处理客户端连接 else: c.close() # 父进程不需要c
基于threading的多线程网络并发
实现步骤:
1. 创建监听套接字
2. 循环接收客户端连接请求
3. 当有新的客户端连接创建线程处理客户端请求
4. 主线程继续等待其他客户端连接
5. 当客户端退出,则对应分支线程退出----------每个线程封装为一个 函数,函数结束,线程自然结束
""" 基于thread的多线程网络并发 """ from socket import * from threading import Thread import os,sys # 客户端处理 def handle(c): print("Connect from",c.getpeername()) while True: data = c.recv(1024) if not data: break print(data.decode()) c.send(b'ok') c.close() # 创建监听套接字 HOST = '176.61.14.181' PORT = 8888 ADDR = (HOST,PORT) s = socket() s.setsockopt(SOCK_STREAM,SO_REUSEADDR,1) s.bind(ADDR) s.listen(3) # 循环等待客户端连接 while True: try: c,addr = s.accept() except KeyboardInterrupt: sys.exit("服务器退出") # 进程退出 except Exception as e: print(e) continue # 创建新的线程处理客户端请求 t = Thread(target=handle,args=(c,)) t.setDaemon(True) # 分支线程随主线程退出 t.start()
""" 基于Process的多进程网络并发 """ from socket import * from multiprocessing import Process import os,sys import signal # 客户端处理 def handle(c): print("Connect from",c.getpeername()) while True: data = c.recv(1024) if not data: break print(data.decode()) c.send(b'ok') c.close() # 创建监听套接字 HOST = '176.61.14.181' PORT = 8888 ADDR = (HOST,PORT) s = socket() s.setsockopt(SOCK_STREAM,SO_REUSEADDR,1) s.bind(ADDR) s.listen(3) # 处理僵尸进程 signal.signal(signal.SIGCHLD,signal.SIG_IGN) # 循环等待客户端连接 while True: try: c,addr = s.accept() except KeyboardInterrupt: sys.exit("服务器退出") # 进程退出 except Exception as e: print(e) continue # 创建子进程处理客户端请求 p = Process(target=handle,args=(c,)) p.daemon = True # 子进程随父进程退出 p.start()
@@扩展:集成模块完成多进程/线程网络并发
1. 使用方法
import socketserver
通过模块提供的不同的类的组合完成多进程或者多线程,tcp或者udp的网络并发模型
2. 常用类说明
TCPServer 创建tcp服务端套接字
UDPServer 创建udp服务端套接字
StreamRequestHandler 处理tcp客户端请求
DatagramRequestHandler 处理udp客户端请求
ForkingMixIn 创建多进程并发
ForkingTCPServer ForkingMixIn + TCPServer
ForkingUDPServer ForkingMixIn + UDPServer
ThreadingMixIn 创建多线程并发
ThreadingTCPServer ThreadingMixIn + TCPServer
ThreadingUDPServer ThreadingMixIn + UDPServer
3. 使用步骤
【1】 创建服务器类,通过选择继承的类,决定创建TCP或者UDP,多进程或者多线程的并发服务器模型。
【2】 创建请求处理类,根据服务类型选择stream处理类还是Datagram处理类。重写handle方法,做具体请求处理。
【3】 通过服务器类实例化对象,并绑定请求处理类。
【4】 通过服务器对象,调用serve_forever()启动服务
ftp 文件服务器
1. 功能
【1】 分为服务端和客户端,要求可以有多个客户端同时操作。
【2】 客户端可以查看服务器文件库中有什么文件。
【3】 客户端可以从文件库中下载文件到本地。
【4】 客户端可以上传一个本地文件到文件库。
【5】 使用print在客户端打印命令输入提示,引导操作
2.思路分析:
1.技术点分析:
* 并发模型:多线程并发模式,当然多进程并发也可以
* 数据传输:TCP传输
2.结构设计:
* 客户端发起请求,打印请求提示界面
* 文件传输功能封装为类【2】【3】【4】
3.功能分析:
* 网络搭建
* 查看文件库信息
* 下载文件
* 上传文件
* 客户端退出
4.协议:
* L 表示请求文件列表
* Q 表示退出
* G 表示下载文件
* P 表示上传文件
""" ftp文件服务器---多线程网络并发 """ from socket import * from threading import Thread import os from time import sleep # 全局变量 HOST = '0.0.0.0' PORT = 8888 ADDR = (HOST,PORT) FTP = '/home/tarena/ftp/' # 文件库路径 # 将客户端请求功能封装为类 class FtpServer: def __init__(self,connfd,FTP_PATH): self.connfd = connfd self.path = FTP_PATH def do_list(self): # 获取文件列表 files = os.listdir(self.path) # 包含了隐藏文件,注意要把其排除 if not files: self.connfd.send("该文件列表为空".encode()) return else: self.connfd.send(b'ok') sleep(0.1) fs = ' ' for file in files: if file[0] != '.' and os.path.isfile(self.path+file): # 保证不是隐藏文件且是普通文件 fs += file + ' ' self.connfd.send(fs.encode()) def do_get(self,filename): try: fd = open(self.path+filename,'rb') except Exception: self.connfd.send("文件不存在".encode()) return else: self.connfd.send(b'ok') sleep(0.1) # 防止粘包 # 发送文件内容 while True: data = fd.read(1024) if not data: # 文件结束 sleep(0.1) # 防止粘包 self.connfd.send(b'##') break self.connfd.send(data) def do_put(self, filename): if os.path.exists(self.path + filename): self.connfd.send("该文件已存在") return self.connfd.send(b'ok') fd = open(self.path+filename,'wb') # 接收文件 while True: data = self.connfd.recv(1024) if data == b'##': break fd.write(data) fd.close() # 客户端请求处理函数 def handle(connfd): cls = connfd.recv(1024).decode() FTP_PATH = FTP + cls + "/" ftp = FtpServer(connfd,FTP_PATH) while True: # 接收客户端请求 data = connfd.recv(1024).decode() print(FTP_PATH,':',data) # 如果客户端断开返回data为空 if not data or data[0] == 'Q': return elif data[0] == 'L': ftp.do_list() elif data[0] == 'G': filename = data.split(' ')[-1] ftp.do_get(filename) elif data[0] == 'P': filename = data.split(' ')[-1] ftp.do_put(filename) # 网络搭建---通过main函数完成 def main(): # 创建套接字 sockfd = socket() sockfd.setsockopt(SOCK_STREAM,SO_REUSEADDR,1) sockfd.bind(ADDR) sockfd.listen(5) print("Listen the port 8888...") while True: try: connfd,addr = sockfd.accept() except KeyboardInterrupt: print("退出服务程序") return except Exception as e: print(e) continue print("链接的客户端:",addr) # 创建新的线程处理请求 client = Thread(target=handle,args=(connfd,)) client.setDaemon(True) client.start() if __name__ == "__main__": main() ============================================= """ ftp文件客户端---多线程网络并发 """ from socket import * import sys import time # 具体功能 class FtpClient: def __init__(self,sockfd): self.sockfd = sockfd def do_list(self): self.sockfd.send(b"L") # 发送请求 # 等待回复 data = self.sockfd.recv(128).decode() # ok表示请求成功 if data == "ok": # 接收文件列表 data = self.sockfd.recv(4096) print(data.decode()) else: print(data) def do_quit(self): self.sockfd.send(b'Q') self.sockfd.close() sys.exit("谢谢使用") # 退出进程(本程序只有一个进程),即整个程序退出 def do_get(self,filename): # 发送请求 self.sockfd.send(("G " + filename).encode()) # 等待回复 data = self.sockfd.recv(128).decode() if data == 'ok': fd = open(filename,'wb') while True: data = self.sockfd.recv(1024) if data == b"##": break fd.write(data) fd.close() else: print(data) def do_put(self,filename): # 判断本地是否有该文件 try: f = open(filename,'rb') except Exception: print("没有该文件") return # 发送请求 filename = filename.split('/')[-1] self.sockfd.send(("P " + filename).encode()) # 等待回复 data = self.sockfd.recv(128).decode() if data == 'ok': while True: data = f.read(1024) if not data: time.sleep(0.1) self.sockfd.send(b'##') break self.sockfd.send(data) f.close() else: print(data) def request(sockfd): while True: ftp = FtpClient(sockfd) print(" *****************命令选项********************") print(" *****************list********************") # 查看文件列表 print(" *****************get file********************") # 下载文件 print(" *****************put file********************") # 上传文件 print(" *****************quit********************") # 退出 print("========================================") cmd = input("输入命令:") if cmd.strip() == 'list': ftp.do_list() elif cmd == 'quit': ftp.do_quit() elif cmd[:3] == 'get': filename = cmd.strip().split(' ')[-1] ftp.do_get(filename) elif cmd[:3] == 'put': filename = cmd.strip().split(' ')[-1] ftp.do_put(filename) # 网络链接 def main(): # 服务器地址 ADDR = ("176.61.14.181",8888) sockfd = socket() try: sockfd.connect(ADDR) except Exception as e: print("链接服务器失败") return else: print("""***************************** Data File Image ***************************** """) cls = input("请输入文件种类:") if cls not in ['Data','File','Image']: print("Sorry input Error!!!") return else: sockfd.send(cls.encode()) request(sockfd) # 发送具体请求 if __name__ == "__main__": main()
IO并发
IO 分类:阻塞IO ,非阻塞IO,IO多路复用,异步IO等
阻塞IO
1.定义:在执行IO操作时如果执行条件不满足则阻塞。阻塞IO是IO的默认形态。
2.效率:阻塞IO是效率很低的一种IO。但是由于逻辑简单所以是默认IO行为。
3.阻塞情况:
* 因为某种执行条件没有满足造成的函数阻塞
e.g. accept input recv
* 处理IO的时间较长产生的阻塞状态
e.g. 网络传输,大文件读写
注:程序分类
1. 计算密集型程序:算法优化
2. IO密集型程序:运行效率低,耗时长
* 阻塞等待
* 网络传输,磁盘交互耗时
非阻塞IO
1. 定义 :通过修改IO属性行为,使原本阻塞的IO变为非阻塞的状态。----通常只能改变《因为某种执行条件没有满足造成的函数阻塞》
* 设置套接字为非阻塞IO
sockfd.setblocking(bool)
功能:设置套接字为非阻塞IO
参数:默认为True,表示套接字IO阻塞;设置为False则套接字IO变为非阻塞
*超时检测 :设置一个最长阻塞时间,超过该时间后则不再阻塞等待。
sockfd.settimeout(sec)
功能:设置套接字的超时时间
参数:设置的时间
""" 套接字非阻塞示例----循环等待客户端连接,在未被连接时,循环将日志写入文件log里 """ from socket import * from time import sleep,ctime # 打开日志文件 f = open('log.txt','a+') sockfd = socket() sockfd.bind(('0.0.0.0',8888)) sockfd.listen(3) # 设置套接字为非阻塞 # sockfd.setblocking(False) # 设置超市检测 sockfd.settimeout(3) while True: print("Waiting for connect..") try: connfd,addr = sockfd.accept() # 已被设置非阻塞 except (BlockingIOError,timeout) as e: #每隔2秒写入一条日志 sleep(2) f.write("%s: %s "%(ctime(),e)) else: data = connfd.recv(1024).decode() print(data)
IO多路复用----属于IO并发方法,只能监控和处理IO行为,当有多个计算行为需要同时处理的时候,仍然需要采用多进程或者多线程,后端的并发程序并不仅仅是网络并发,还有计算并发
1. 定义:同时监控多个IO事件,当哪个IO事件准备就绪就执行哪个IO事件。以此形成可以同时处理多个IO的行为,避免一个IO阻塞造成其他IO均无法执行,提高了IO执行效率。
注:
* 前提是多个IO时间的运行互不影响
* 准备就绪:临界概念,事件刚刚产生,比如input()函数,输入内容按回车一刹那就是准备就绪,网络通信中accept()等待连接,恰好连接上的一瞬间
2. 具体方案
select方法 : windows linux unix
poll方法: linux unix
epoll方法: linux
注:以上三个方法都是来自select模块,思想都是一样的,都是同时监控多个IO事件,实现方法不同而已
select 方法:
rs, ws, xs=select(rlist, wlist, xlist[, timeout])
功能: 监控IO事件,阻塞等待IO发生
参数:rlist 列表 存放关注的等待发生的IO事件-----即IO事件的发生不是由本身决定的,必须等待外部条件带来这个IO事件的发生,被动等待发生,如accept()
wlist 列表 存放关注的要主动处理的IO事件------即IO事件的发生由自己控制,不需要等待外部条件的发生,主动处理阻塞,此时,select相当于非阻塞
xlist 列表 存放关注的出现异常要处理的IO事件-------即IO事件发生异常
timeout 超时时间
注:前三个参数代表IO事件发生的不同类别
通过哪个对象调用IO函数行为,这个对象就是IO事件
如果中间参数列表(wlist)存在IO事件的话,则select相当于没有阻塞(主动处理阻塞)
返回值: rs 列表 rlist中准备就绪的IO-----返回值为列表,列表元素为就绪的IO事件对象
ws 列表 wlist中准备就绪的IO-----返回值为列表,列表元素为就绪的IO事件对象
xs 列表 xlist中准备就绪的IO-----返回值为列表,列表元素为就绪的IO事件对象
""" select函数讲解 """ from socket import * from select import select # 做几个IO用作监控 s = socket() s.bind(('0.0.0.0',8880)) s.listen(3) fd = open("log.txt",'a+') print("开始提交监控的IO") rs,ws,xs = select([s,fd],[fd],[]) print("rs:",rs) print("ws:",ws) print("xs:",xs) 输出结果: rs: [<_io.TextIOWrapper name='log.txt' mode='a+' encoding='UTF-8'>] ws: [<_io.TextIOWrapper name='log.txt' mode='a+' encoding='UTF-8'>] xs: []
select 实现tcp服务:
【1】 将关注的IO放入对应的监控类别列表
【2】通过select函数进行监控
【3】遍历select返回值列表,确定就绪IO事件
【4】处理发生的IO事件
注意:
* wlist中如果存在IO事件,则select立即返回给ws
* 处理IO过程中不要出现死循环占有服务端的情况
* IO多路复用消耗资源较少,效率较高
""" IO多路复用select实现多客户端通信,即对服务端使用IO多路复用技术 """ from socket import * from select import select # 设置套接字为关注IO s = socket() s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) s.bind(('0.0.0.0',8888)) s.listen(5) # 设置关注的IO rlist = [s] wlist = [] xlist = [] while True: # 监控IO的发生 rs,ws,xs = select(rlist,wlist,xlist) # 建立三个返回值列表,判断哪个IO发生 for r in rs: # 如果是s套接字就绪,则处理链接 if r is s: c,addr = r.accept() print("Connect from",addr) # 加入新的关注IO,目前需求是收消息,如果加wlist则表示发消息,作为服务端,一般是先接收再发送 # 此时rlist多了一个客户端套接字c,那么当再次循环至select时,其返回结果有三种可能:[s],[s,c],[c],此外还可能在等待 rlist.append(c) else: # 此时只考虑两种情况:[s],[c],将[s,c]剔除,因此,只用else,不用elif data = r.recv(1024) if not data: rlist.remove(r) r.close() continue print(data) # r.send(b'ok') # 希望我们主动处理这个IO wlist.append(r) for w in ws: w.send(b'ok,thanks') wlist.remove(w) # 防止不断的想客户端发送消息 for r in xs: pass
@@扩展: 位运算
定义 : 将整数转换为二进制,按二进制位进行运算
运算符号:
& 按位与
| 按位或
^ 按位异或
<< 左移
> > 右移
e.g. 14 --> 01110
19 --> 10011
14 & 19 = 00010 = 2 一0则0
14 | 19 = 11111 = 31 一1则1
14 ^ 19 = 11101 = 29 相同为0不同为1
14 << 2 = 111000 = 56 向左移动低位补0
14 >> 2 = 11 = 3 向右移动去掉低位
poll方法:
p = select.poll()--------------这个poll是select模块下的,是生成对象的
功能 : 创建poll对象
返回值: poll对象
p.register(fd,event)
功能: 注册关注的IO事件,即添加IO事件
参数:fd 要关注的IO对象
event 要关注的IO事件类型
常用类型:POLLIN 读IO事件(rlist)
POLLOUT 写IO事件 (wlist)
POLLERR 异常IO (xlist)
POLLHUP 断开连接
e.g. p.register(sockfd,POLLIN|POLLERR)------同是关注多个事件
p.unregister(fd)
功能:取消对IO的关注
参数:IO对象或者IO对象的fileno(文件描述符)
events = p.poll()---------------------这个poll是p对象的属性函数
功能: 阻塞等待监控的IO事件发生(即监控)
返回值: 返回发生的IO,返回值为列表,列表元素为元组,元组代表就绪的IO时间,元组由两项构成,一是就绪IO的文件描述符,另一个是就绪IO的就绪时间
events格式 [(fileno,event),()....]
每个元组为一个就绪IO(不是对象),元组第一项是该IO的fileno,第二项为该IO就绪的事件类型,两项都不是对象,因此要根据fileno回推就绪IO对象,因此要提前搭建查找地图,每关注一个IO就把它的文件描述符加入其中,
如果取消关注,则将其从查找地图中删除,在此建议地图采用字典形式
poll_server 步骤:
【1】 创建套接字
【2】 将套接字register
【3】 创建查找字典,并维护
【4】 循环监控IO发生
【5】 处理发生的IO
""" poll实现的IO多路复用 """ from select import * from socket import * # 设置套接字为关注IO s = socket() s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) s.bind(('0.0.0.0',8888)) s.listen(5) # 创建poll p = poll() # 建立查找字典{fileno: io_obj} fdmap = {s.fileno():s} # 设置关注IO p.register(s,POLLIN|POLLERR) # 循环监控IO事件的发生 while True: events = p.poll # 阻塞等待IO发生 for fd,event in events: # 遍历列表处理IO if fd == s.fileno(): c,addr = fdmap[fd].accept() # 保持代码风格统一 print("Connect from",addr) # 添加新的关注IO事件 p.register(c,POLLIN|POLLHUP) fdmap[c.fileno()] = c # elif event & POLLHUP: # print("客户端退出") # p.unregister(fd) # 取消关注 # fdmap[fd].close() # del fdmap[fd] # 从字典中删除 elif event & POLLIN: # 客户端发消息 data = fdmap[fd].recv(1024) # 断开发生时POLLIN返回空此时POLLIN也会就绪 if not data: p.unregister(fd) # 取消关注 fdmap[fd].close() del fdmap[fd] continue print(data.decode()) fdmap[fd].send(b'ok')
epoll方法
1. 使用方法 : 基本与poll相同
* 生成对象改为 epoll()
* 将所有事件类型改为EPOLL类型
2. epoll特点:
* epoll 效率比select poll要高:select和poll要来回复制应用层和内核的关注事件且还要在应用层对从内核复制的事件进行遍历找出满足就绪事件,耗时;epoll则直接在内核开辟空间,需要监控哪个IO事件,
应用层直接将其放入内核进行监控,待有就绪事件时,内核只需将就绪事件返回给应用层即可,虽然消耗内存,但是提升了来回复制和遍历消耗的事件
* epoll 监控IO数量比select poll要多:select和poll最多监控1024个,epoll监控更多
* epoll 的触发方式比poll要多 (EPOLLET边缘触发):三者默认状态都是水平触发,epoll多了个边缘触发
""" epoll实现的IO多路复用 """ from select import * from socket import * # 设置套接字为关注IO s = socket() s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) s.bind(('0.0.0.0',8888)) s.listen(5) # 创建epoll ep = epoll() # 建立查找字典{fileno: io_obj} fdmap = {s.fileno():s} # 设置关注IO ep.register(s,EPOLLIN|EPOLLERR) # 循环监控IO事件的发生 while True: events = ep.poll # 阻塞等待IO发生 for fd,event in events: # 遍历列表处理IO if fd == s.fileno(): c,addr = fdmap[fd].accept() # 保持代码风格统一 print("Connect from",addr) # 添加新的关注IO事件 ep.register(c,EPOLLIN|EPOLLHUP) fdmap[c.fileno()] = c # elif event & EPOLLHUP: # print("客户端退出") # ep.unregister(fd) # 取消关注 # fdmap[fd].close() # del fdmap[fd] # 从字典中删除 elif event & EPOLLIN: # 客户端发消息 data = fdmap[fd].recv(1024) # 断开发生时EPOLLIN返回空此时EPOLLIN也会就绪 if not data: ep.unregister(fd) # 取消关注 fdmap[fd].close() del fdmap[fd] continue print(data.decode()) fdmap[fd].send(b'ok')
五、协程技术----实现异步IO的方法
基础概念
1. 定义:纤程,微线程。是为非抢占式(相互之间协调执行)多任务产生子程序的计算机组件(一段封装的代码)。协程允许不同入口点在不同位置暂停或开始,简单来说,协程就是可以暂停执行的函数(如:yield函数)。
2. 协程原理 : 记录一个函数的上下文栈帧(记录函数执行的位置),协程调度切换时会将记录的上下文保存,在切换回来时进行调取,恢复原有的执行内容,以便从上一次执行位置继续执行。
即在应用层,通过人为控制函数之间的执行跳转来来完成事件,因此可称为异步IO模式
3. 协程优缺点:
优点:
1. 协程完成多任务占用计算资源很少:因为所有操作只涉及整个进程栈的内存操作,不涉及内核操作
2. 由于协程的多任务切换在应用层完成,因此切换开销少
3. 协程为单线程程序,无需进行共享资源同步互斥处理
缺点:
协程的本质是一个单线程,无法利用计算机多核资源
注:协程和线程区别:*实现原理不同:协程是单线程程序,无法利用计算机的多和资源
扩展延伸@标准库协程的实现
python3.5以后,使用标准库asyncio和async/await 语法来编写并发代码。asyncio库通过对异步IO行为的支持完成python的协成调。
* 同步是指完成事务的逻辑,先执行第一个事务,如果阻塞了,会一直等待,直到这个事务完成,再执行第二个事务,顺序执行。
* 异步是和同步相对的,异步是指在处理调用这个事务的之后,不会等待这个事务的处理结果,直接处理第二个事务去了,通过状态、通知、回调来通知调用者处理结果。
虽然官方说asyncio是未来的开发方向,但是由于其生态不够丰富,大量的客户端不支持awaitable(不支持基于协程的阻塞),需要自己去封装,所以在使用上存在缺陷。更多时候只能使用已有的异步库(asyncio等),功能有限
""" 协程小示例 """ import asyncio import time now = lambda : time.time() # 协程函数 async def do_work(x): print("Waiting :",x) # await asyncio.sleep(x) # 协程跳转,跳出该协程函数,当不阻塞时再回来继续执行后面的程序 await time.sleep(x) # 这个可以证明不是所有的阻塞都能跳转,在日常中,大量客户端并不支持这种跳转,即只能使用有限的已有异步库(asyncio) return "None after %s s"%x start = now() # 生成三个协程对象 cor1 = do_work(1) cor2 = do_work(2) cor3 = do_work(3) # 将协程对象生成一个可轮寻异步io操作的对象列表 tasks = [ asyncio.ensure_future(cor1), asyncio.ensure_future(cor2), asyncio.ensure_future(cor3), ] # 生成轮寻对象,调用run启动协程执行 loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.wait(tasks)) # 记录执行时间 print("Time:",now() - start) 用await asyncio.sleep(x)测试结果: Waiting : 1 Waiting : 2 Waiting : 3 Time: 3.0023772716522217 用await time.sleep(x)测试结果: Waiting : 1 Waiting : 2 Waiting : 3 Time: 6.007911682128906
第三方协程模
1. greenlet模块
* 安装 : sudo pip3 install greenlet
* 函数
greenlet.greenlet(func)
功能:创建协程对象
参数:协程函数
g.switch()
功能:选择要执行的协程函数
from greenlet import greenlet def test1(): print("执行test1") gr2.switch() print("结束test1") gr2.switch() def test2(): print("执行test2") gr1.switch() print("结束test2") # 将函数变成协程函数 gr1 = greenlet(test1) gr2 = greenlet(test2) gr1.switch() # 执行协程test1
2. gevent模块-----------依赖于greenlet模块
* 安装:sudo pip3 instll gevent
* 函数
gevent.spawn(func,argv)
功能: 生成协程对象
参数:func 协程函数
argv 给协程函数传参(不定参---按照位置一一传递)
返回值: 协程对象
gevent.joinall(list,[timeout])
功能: 阻塞等待协程执行完毕
参数:list 协程对象列表
timeout 超时时间
gevent.sleep(sec)
功能: gevent睡眠阻塞
参数:睡眠时间
*gevent协程只有在遇到gevent指定的阻塞行为(gevent.sleep)时才会自动在协程之间进行跳转如gevent.joinall(),gevent.sleep()带来的阻塞
import gevent from time import sleep def foo(a,b): print("Running foo...",a,b) gevent.sleep(3) print("Foo again") def bar(): print("Running bar...") gevent.sleep(2) print("Bar again") # 将函数封装为协程,遇到gevent阻塞自动执行 f = gevent.spawn(foo,1,"hello") g = gevent.spawn(bar) gevent.joinall([f,g]) # 阻塞等待f,g的结束 gevent.sleep(3)
* monkey脚本
作用:在gevent协程中,协程只有遇到gevent指定类型的阻塞(gevent.sleep)才能跳转到其他协程,因此,我们希望将普通的IO阻塞行为转换为可以触发gevent协程跳转的阻塞,以提高执行效率。
转换方法:gevent 提供了一个脚本程序monkey,可以修改底层解释IO阻塞的行为,将很多普通阻塞转换为gevent阻塞。
使用方法:
【1】 导入monkey
from gevent import monkey
【2】 运行相应的脚本,例如转换socket中所有阻塞
monkey.patch_socket()
【3】 如果将所有可转换的IO阻塞全部转换则运行all
monkey.patch_all()
【4】 注意:脚本运行函数需要在对应模块导入前执行
""" gevent协程演示 """ from gevent import monkey import gevent monkey.patch_all() # 该句的执行必须在导入socket之前 from socket import * # 处理客户端请求 def handle(c): while True: data = c.recv(1024) if not data: break print(data.decode()) c.send(b'ok') c.close() # 创建套接字 s = socket() s.bind(('0.0.0.0',8888)) s.listen(5) while True: c,addr = s.accept() print("Connect from",addr) # handle(c) # 循环方案 gevent.spawn(handle,c) # 协程方案 s.close()
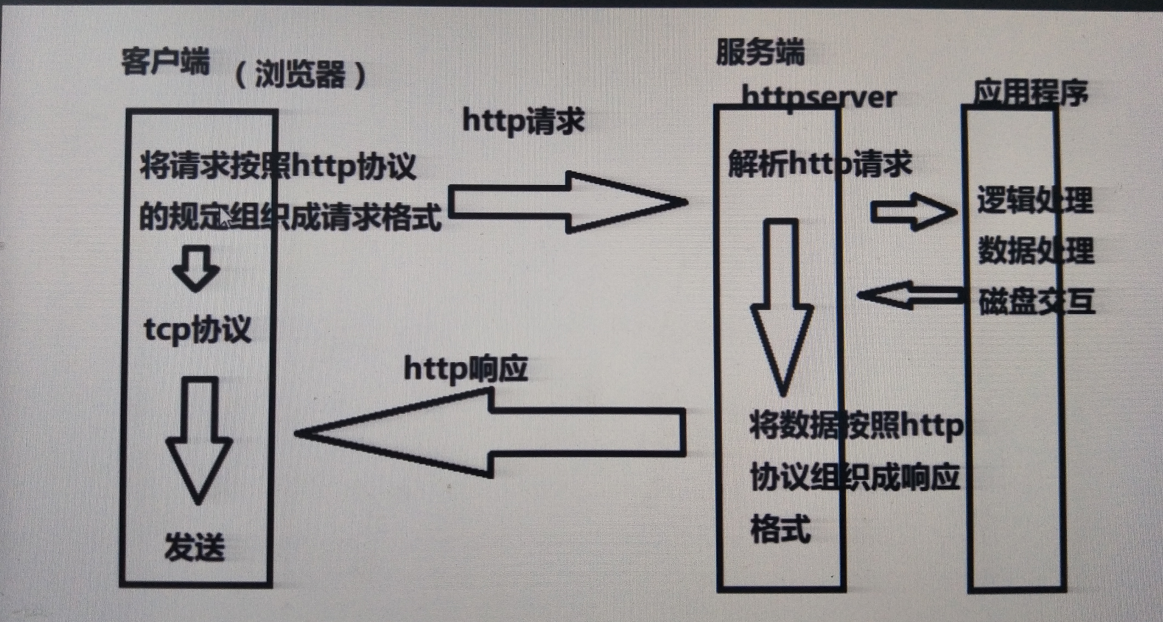
HTTPServer v2.0
1. 主要功能 :
【1】 接收客户端(浏览器)请求
【2】 解析客户端发送的请求
【3】 根据请求组织数据内容
【4】 将数据内容形参http响应格式返回给浏览器
2. 升级点 :
【1】 采用IO并发,可以满足多个客户端同时发起请求情况
【2】 做基本的请求解析,根据具体请求返回具体内容,同时满足客户端简单的非网页请求情况
【3】 通过类接口形式进行功能封装
""" httpserver 2.0 主要功能 : 【1】 接收客户端(浏览器)请求 【2】 解析客户端发送的请求 【3】 根据请求组织数据内容 【4】 将数据内容形参http响应格式返回给浏览器 【5】 采用IO并发,可以满足多个客户端同时发起请求情况 【6】 做基本的请求解析,根据具体请求返回具体内容,同时满足客户端简单的非网页请求情况 【7】 通过类接口形式进行功能封装 技术点: 1.使用tcp通信 2.select io多路复用 结构: 1.采用类封装 类的接口设计: * 在用户使用角度进行工作流程设计 * 尽可能提供全面的功能,能为用户决定的在类中实现 * 不能替用户决定的变量可以通过实例化对象传入类中 * 不能替用户决定的复杂功能,可以通过重写覆盖让用户自己决定 """ from select import select from socket import * # 将具体http server功能封装 class HTTPServer: def __init__(self,server_addr,static_dir): # 添加属性 self.server_address = server_addr self.static_dir = static_dir self.rlist = [] self.wlist = [] self.xlist = [] self.create_socket() self.bind() # 创建套接字 def create_socket(self): self.sockfd = socket() self.sockfd.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) # 设置地址立即重用 # 绑定 def bind(self): self.sockfd.bind(self.server_address) self.ip = self.server_address[0] self.port = self.server_address[1] def serve_forever(self): self.sockfd.listen(5) print("Listen the port %d"%self.port) # port由使用者决定,即通过传参 self.rlist.append(self.sockfd) # 循环监听客户端连接 while True: rs,ws,xs = select(self.rlist, self.wlist, self.xlist) for r in rs: if r is self.sockfd: c,addr = r.accept() print("Connect from",addr) self.rlist.append(c) else: # 处理浏览器(即客户端)请求---接收请求和发送相应 self.handle(r) # 处理客户端请求 def handle(self,connfd): # 接收http请求 request = connfd.recv(4096) # 防止浏览器断开--即浏览器断开后,将该连接套接字去除 if not request: self.rlist.remove(connfd) connfd.close() return # print(request) # 请求解析 request_line = request.splitlines()[0] info = request_line.decode().split(" ")[1] print(connfd.getpeername(),":",info) # info 分为方位网页和其他 if info == "/" or info[-5:] == '.html': self.get_html(connfd,info) else: self.get_data(connfd,info) self.rlist.remove(connfd) connfd.close() # 处理网页 def get_html(self,connfd,info): if info == "/": # 网页文件 filename = self.static_dir + '/index.html' else: filename = self.static_dir + info try: fd = open(filename) except Exception: # 没有网页 responseHeaders = 'HTTP/1.1 404 Not Found ' responseHeaders += ' ' responseBody = "<h1>Sorry,Not Found the page</h1>" else: responseHeaders = 'HTTP/1.1 200 OK ' responseHeaders += ' ' responseBody = fd.read() finally: response = responseHeaders + responseBody connfd.send(response.encode()) # 其他 def get_data(self,connfd,info): responseHeaders = 'HTTP/1.1 200 OK ' responseHeaders += ' ' responseBody = "<h1>Waiting Httpserver 3.0</h1>" response = responseHeaders + responseBody connfd.send(response.encode())