转载请注明出处“一块努力的牛皮糖”:http://www.cnblogs.com/yuxc/
新手上路,翻译不恰之处,恳请指出,不胜感谢
Updated log
3.4 Regular Expressions for Detecting Word Patterns
使用正则表达式检测词组
Many linguistic processing tasks involve pattern matching(模式匹配). For example, we can find words ending with ed using endswith('ed'). We saw a variety of such “word tests” in Table 1-4. Regular expressions give us a more powerful and flexible method for describing the character patterns we are interested in.
There are many other published introductions to regular expressions, organized around the syntax of regular expressions and applied to searching text files. Instead of doing this again, we focus on the use of regular expressions at different stages of linguistic processing. As usual, we’ll adopt a problem-based approach and present new features only as they are needed to solve practical problems. In our discussion we will mark regular expressions using chevrons(V型) like this: «patt».

Figure 3-4. Unicode and IDLE: UTF-8 encoded string literals in the IDLE editor; this requires that an appropriate font is set in IDLE’s preferences; here we have chosen Courier CE.
To use regular expressions in Python, we need to import the re library using: import re. We also need a list of words to search; we’ll use the Words Corpus again (Section 2.4). We will preprocess it to remove any proper names.
>>> wordlist = [w for w in nltk.corpus.words.words('en') if w.islower()]
Using Basic Metacharacters 使用基本的元字符
Let’s find words ending with ed using the regular expression «ed$». We will use the re.search(p, s) function to check whether the pattern p can be found somewhere inside the string s. We need to specify the characters of interest, and use the dollar sign, which has a special behavior in the context of regular expressions in that it matches the end of the word($表示以此结尾的单词):
['abaissed', 'abandoned', 'abased', 'abashed', 'abatised', 'abed', 'aborted', ...]
The . wildcard(通配符) symbol matches any single character(句号可以匹配任何单字符). Suppose we have room in a crossword puzzle(纵横字谜) for an eight-letter word, with j as its third letter and t as its sixth letter. In place of each blank cell we use a period(句号,圆点):
['abjectly', 'adjuster', 'dejected', 'dejectly', 'injector', 'majestic', ...]
![]() Your Turn: The caret symbol(插入字符) ^ matches the start of a string, just like the $ matches the end. What results do we get with the example just shown if we leave out both of these, and search for «..j..t..»? 字符长度就不能保证为8了
Your Turn: The caret symbol(插入字符) ^ matches the start of a string, just like the $ matches the end. What results do we get with the example just shown if we leave out both of these, and search for «..j..t..»? 字符长度就不能保证为8了
Finally, the ? symbol specifies that the previous character is optional(?表示先前的字符是可选的). Thus «^e-?mail $» will match both email and e-mail. We could count the total number of occurrences of this word (in either spelling) in a text using sum(1 for w in text if re.search('^e-? mail$', w)).
Ranges and Closures 范围和结束
The T9 system is used for entering text on mobile phones (see Figure 3-5). Two or more words that are entered with the same sequence of keystrokes(击键) are known as textonyms(网上找来的解释:words that map to the same mobile phone keys when sending text messages). For example, both hole and golf are entered by pressing the sequence 4653(手机键盘). What other words could be produced with the same sequence? Here we use the regular expression «^[ghi][mno][jlk][def]$»:
['gold', 'golf', 'hold', 'hole']
The first part of the expression, «^[ghi]», matches the start of a word followed by g, h, or i. The next part of the expression, «[mno]», constrains the second character to be m, n, or o. The third and fourth characters are also constrained. Only four words satisfy all these constraints. Note that the order of characters inside the square brackets is not significant, so we could have written «^[hig][nom][ljk][fed]$» and matched the same words.
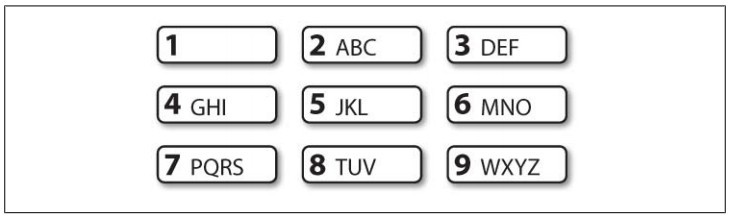
Figure 3-5. T9: Text on 9 keys.
![]() Your Turn: Look for some “finger-twisters,” by searching for words that use only part of the number-pad. For example «^[ghijklmno]+$», or more concisely, «^[g-o]+$», will match words that only use keys 4, 5, 6 in the center row, and «^[a-fj-o]+$» will match words that use keys 2, 3, 5, 6 in the top-right corner. What do - and + mean? +表示一个或多个,-表示范围
Your Turn: Look for some “finger-twisters,” by searching for words that use only part of the number-pad. For example «^[ghijklmno]+$», or more concisely, «^[g-o]+$», will match words that only use keys 4, 5, 6 in the center row, and «^[a-fj-o]+$» will match words that use keys 2, 3, 5, 6 in the top-right corner. What do - and + mean? +表示一个或多个,-表示范围
Let’s explore the + symbol a bit further. Notice that it can be applied to individual letters, or to bracketed sets of letters:
>>> [w for w in chat_words if re.search('^m+i+n+e+$', w)]
['miiiiiiiiiiiiinnnnnnnnnnneeeeeeeeee', 'miiiiiinnnnnnnnnneeeeeeee', 'mine',
'mmmmmmmmiiiiiiiiinnnnnnnnneeeeeeee']
>>> [w for w in chat_words if re.search('^[ha]+$', w)]
['a', 'aaaaaaaaaaaaaaaaa', 'aaahhhh', 'ah', 'ahah', 'ahahah', 'ahh',
'ahhahahaha', 'ahhh', 'ahhhh', 'ahhhhhh', 'ahhhhhhhhhhhhhh', 'h', 'ha', 'haaa',
'hah', 'haha', 'hahaaa', 'hahah', 'hahaha', 'hahahaa', 'hahahah', 'hahahaha', ...]
It should be clear that + simply means “one or more instances of the preceding item,” which could be an individual character like m, a set like [fed], or a range like [d-f]. Now let’s replace + with *, which means “zero or more instances of the preceding item.” The regular expression «^m*i*n*e*$» will match everything that we found using «^m+i+n+e+$», but also words where some of the letters don’t appear at all, e.g., me, min, and mmmmm. Note that the + and * symbols are sometimes referred to as Kleene closures, or simply closures(闭包?).
The ^ operator has another function when it appears as the first character inside square brackets. For example, «[^aeiouAEIOU]» matches any character other than(除了) a vowel(元音). We can search the NPS Chat Corpus for words that are made up entirely of non-vowel characters using «^[^aeiouAEIOU]+$» to find items like these: :):):), grrr, cyb3r, and zzzzzzzz. Notice this includes non-alphabetic characters. Here are some more examples of regular expressions being used to find tokens that match a particular pattern, illustrating the use of some new symbols: \, {}, (), and |.
>>> [w for w in wsj if re.search('^[0-9]+\.[0-9]+$', w)]
['0.0085', '0.05', '0.1', '0.16', '0.2', '0.25', '0.28', '0.3', '0.4', '0.5',
'0.50', '0.54', '0.56', '0.60', '0.7', '0.82', '0.84', '0.9', '0.95', '0.99',
'1.01', '1.1', '1.125', '1.14', '1.1650', '1.17', '1.18', '1.19', '1.2', ...]
>>> [w for w in wsj if re.search('^[A-Z]+\$$', w)]
['C$', 'US$']
>>> [w for w in wsj if re.search('^[0-9]{4}$', w)]
['1614', '1637', '1787', '1901', '1903', '1917', '1925', '1929', '1933', ...]
>>> [w for w in wsj if re.search('^[0-9]+-[a-z]{3,5}$', w)]
['10-day', '10-lap', '10-year', '100-share', '12-point', '12-year', ...]
>>> [w for w in wsj if re.search('^[a-z]{5,}-[a-z]{2,3}-[a-z]{,6}$', w)]
['black-and-white', 'bread-and-butter', 'father-in-law', 'machine-gun-toting',
'savings-and-loan']
>>> [w for w in wsj if re.search('(ed|ing)$', w)]
['62%-owned', 'Absorbed', 'According', 'Adopting', 'Advanced', 'Advancing', ...]
![]() Your Turn: Study the previous examples and try to work out what the \, {}, (), and | notations mean before you read on.
Your Turn: Study the previous examples and try to work out what the \, {}, (), and | notations mean before you read on.
You probably worked out that a backslash means that the following character is deprived of its special powers and must literally match a specific character in the word. Thus, while . is special, \. only matches a period. The braced(大括号) expressions, like {3,5}, specify the number of repeats of the previous item. The pipe character indicates a choice between the material on its left or its right. Parentheses(圆括号) indicate the scope of an operator, and they can be used together with the pipe (or disjunction) symbol like this: «w(i|e|ai|oo)t», matching wit, wet, wait, and woot. It is instructive(有益的) to see what happens when you omit the parentheses from the last expression in the example, and search for «ed|ing$». The metacharacters we have seen are summarized in Table 3-3
Table 3-3. Basic regular expression metacharacters, including wildcards, ranges, and closures
| Operator | Behavior |
| . | Wildcard, matches any character |
| ^abc | Matches some pattern abc at the start of a string |
| abc$ | Matches some pattern abc at the end of a string |
| [abc] | Matches one of a set of characters |
| [A-Z0-9] | Matches one of a range of characters |
| ed|ing|s | Matches one of the specified strings (disjunction) |
| * | Zero or more of previous item, e.g., a*, [a-z]* (also known as Kleene Closure) |
| + | One or more of previous item, e.g., a+, [a-z]+ |
| ? | Zero or one of the previous item (i.e., optional), e.g., a?, [a-z]? |
| {n} | Exactly n repeats where n is a non-negative integer |
| {n,} | At least n repeats |
| {,n} | No more than n repeats |
| {m,n} | At least m and no more than n repeats |
| a(b|c)+ | Parentheses that indicate the scope of the operators |
To the Python interpreter, a regular expression is just like any other string. If the string contains a backslash followed by particular characters, it will interpret these specially. For example, \b would be interpreted as the backspace(退格) character. In general, when using regular expressions containing backslash, we should instruct the interpreter not to look inside the string at all, but simply to pass it directly to the re library for processing. We do this by prefixing the string with the letter r, to indicate that it is a raw string. For example, the raw string r'\band\b' contains two \b symbols that are interpreted by the re library as matching word boundaries(\b表示匹配单词的边界) instead of backspace characters. If you get into the habit of using r'...' for regular expressions—as we will do from now on—you will avoid having to think about these complications.